

Стэнфордский университет опубликовал отчет AI Index Report 2024, в котором отмечается, что стремительное развитие ИИ делает сравнение с человеком все менее актуальным.
Сайт годовой отчёт дает полное представление о тенденциях и состоянии разработок в области ИИ. В отчете говорится, что модели ИИ совершенствуются настолько быстро, что эталоны, которые мы используем для их оценки, все чаще становятся неактуальными.
Многие отраслевые бенчмарки сравнивают модели ИИ с тем, насколько хорошо человек справляется с задачами. Хорошим примером является бенчмарк Massive Multitask Language Understanding (MMLU).
В нем используются вопросы с несколькими вариантами ответов для оценки уровня магистратуры по 57 предметам, включая математику, историю, право и этику. С 2019 года MMLU является основным эталоном ИИ.
Базовый результат человека в MMLU составляет 89,8%, а в 2019 году средняя модель ИИ набрала чуть больше 30%. Всего через 5 лет Gemini Ultra стала первой моделью, которая побила базовый человеческий показатель, набрав 90,04%.
В отчете отмечается, что современные "системы искусственного интеллекта регулярно превосходят человеческие показатели по стандартным эталонам". Тенденции, показанные на графике ниже, указывают на то, что MMLU и другие эталоны нуждаются в замене.
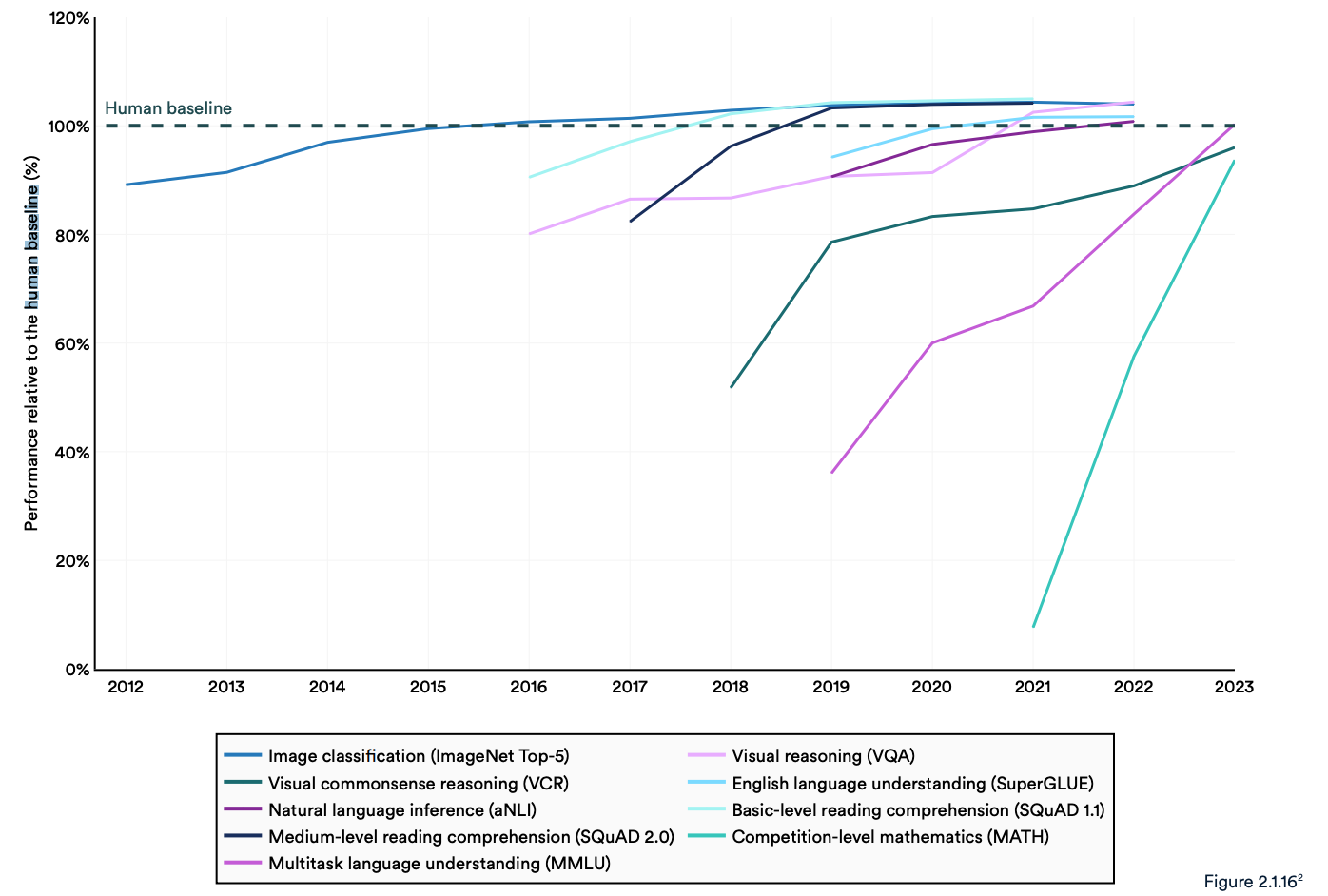
Модели искусственного интеллекта достигли насыщения производительности в таких известных бенчмарках, как ImageNet, SQuAD и SuperGLUE, поэтому исследователи разрабатывают более сложные тесты.
Одним из примеров является бенчмарк Google-Proof Q&A Benchmark (GPQA), который позволяет сравнивать модели ИИ с действительно умными людьми, а не со средним уровнем человеческого интеллекта.
Тест GPQA состоит из 400 сложных вопросов с несколькими вариантами ответов для выпускников. Эксперты, получившие или получающие докторскую степень, правильно отвечают на вопросы в 65% случаев.
В документе GPQA говорится, что, задавая вопросы не по своей специальности, "высококвалифицированные валидаторы, не являющиеся экспертами, достигают точности 34%, несмотря на то, что в среднем тратят более 30 минут на неограниченный доступ к Интернету".
В прошлом месяце компания Anthropic объявила, что Клод 3 набрал чуть меньше 60% с 5-ю выстрелами по подсказке CoT. Нам понадобится более мощный бенчмарк.
Клод 3 получил ~60% точности по GPQA. Мне трудно преуменьшить, насколько сложны эти вопросы - буквальные доктора наук (в областях, отличных от вопросов), имеющие доступ к интернету, получают 34%.
Доктора наук *в том же домене* (также с доступом в Интернет!) получают точность 65% - 75%. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- Дэвид Рин (@idavidrein) 4 марта 2024 года
Оценки и безопасность человека
В докладе отмечается, что ИИ по-прежнему сталкивается с серьезными проблемами: "Он не может надежно работать с фактами, проводить сложные рассуждения или объяснять свои выводы".
Эти ограничения способствуют появлению еще одной характеристики системы ИИ, которая, по мнению авторов доклада, плохо поддается измерению; Безопасность ИИ. У нас нет эффективных контрольных показателей, которые позволили бы нам сказать: "Эта модель безопаснее, чем та".
Отчасти потому, что его трудно измерить, а отчасти потому, что "разработчикам ИИ не хватает прозрачности, особенно в части раскрытия данных для обучения и методик".
В отчете отмечается, что интересной тенденцией в отрасли является краудсорсинг - оценка эффективности ИИ людьми, а не эталонными тестами.
Оценить эстетику образа или прозу модели сложно с помощью теста. В результате, как говорится в отчете, "бенчмаркинг постепенно начал смещаться в сторону включения человеческих оценок, таких как Chatbot Arena Leaderboard, а не компьютерных рейтингов, таких как ImageNet или SQuAD".
По мере того как модели ИИ наблюдают за тем, как человеческий базовый уровень исчезает в зеркале заднего вида, настроение может в конечном итоге определить, какую модель мы выберем.
Тенденции указывают на то, что модели ИИ со временем станут умнее нас и их будет сложнее измерить. Возможно, скоро мы будем говорить: "Не знаю почему, но эта модель мне нравится больше".



