

Microsoft выпустила Phi-3 Mini, миниатюрную языковую модель, которая является частью стратегии компании по разработке легких, специфичных для конкретных функций моделей ИИ.
В процессе развития языковых моделей увеличивались параметры, наборы обучающих данных и контекстные окна. Масштабирование размеров этих моделей обеспечивало более мощные возможности, но за это приходилось платить.
Традиционный подход к обучению LLM заключается в том, что он потребляет огромные объемы данных, что требует огромных вычислительных ресурсов. Обучение LLM, например GPT-4, по оценкам, заняло около 3 месяцев и стоило более $21 млн.
GPT-4 - отличное решение для задач, требующих сложных рассуждений, но излишество для более простых задач, таких как создание контента или чатбота для продаж. Это все равно что использовать швейцарский армейский нож, когда вам нужен всего лишь простой нож для писем.
При параметрах всего 3,8 ББ Phi-3 Mini совсем крошечный. Тем не менее Microsoft утверждает, что это идеальное легкое и недорогое решение для таких задач, как резюмирование документа, извлечение информации из отчетов, написание описаний продуктов или постов в социальных сетях.
По данным бенчмарка MMLU, Phi-3 Mini и еще не вышедшие модели Phi опережают такие крупные модели, как Mistral 7B и Джемма 7B.
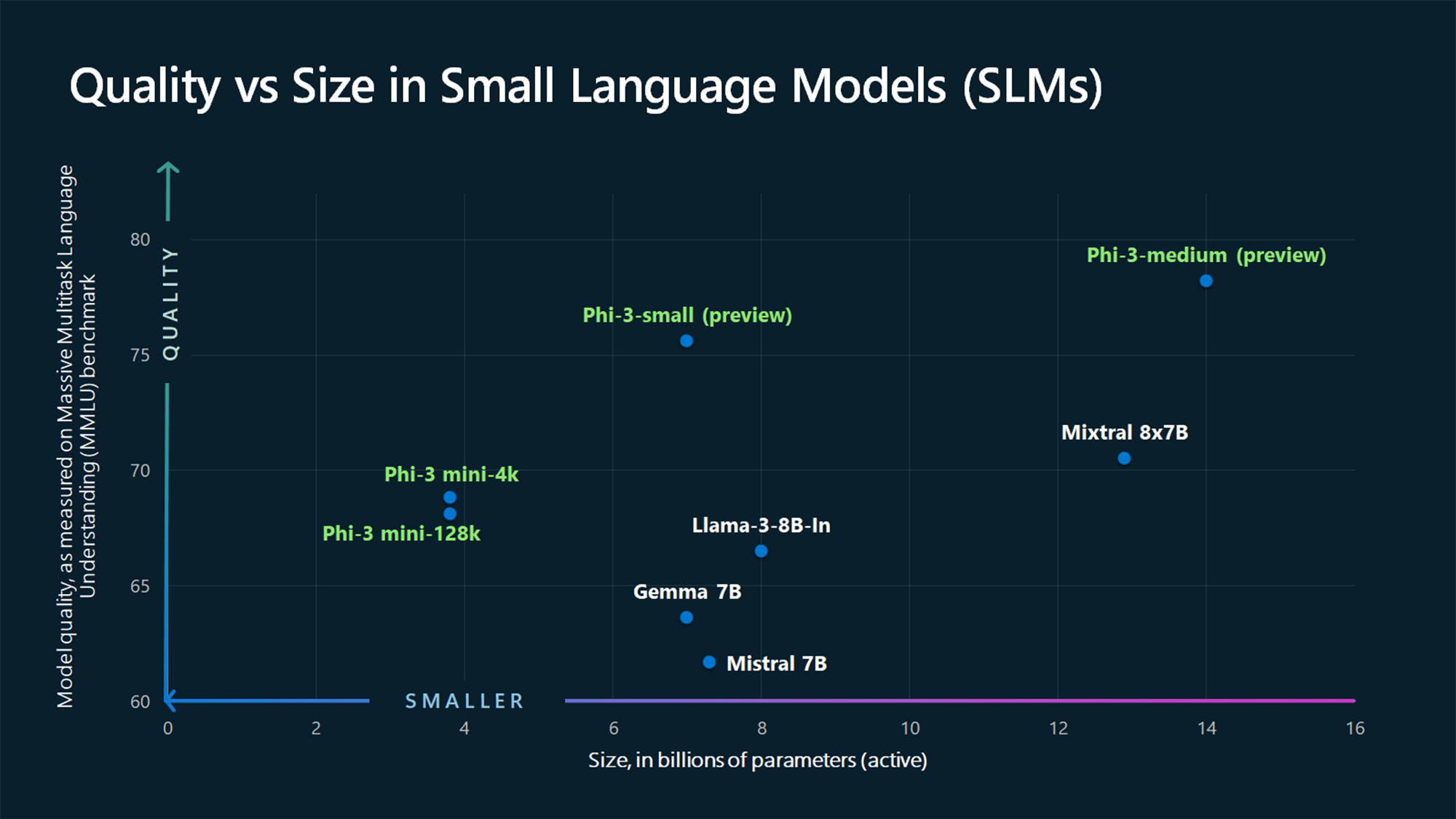
По словам Microsoft, Phi-3-small (7B параметров) и Phi-3-medium (14B параметров) будут доступны в Azure AI Model Catalog "в ближайшее время".
Большие модели, такие как GPT-4, по-прежнему являются золотым стандартом, и мы можем ожидать, что GPT-5 будет еще больше.
SLM, подобные Phi-3 Mini, обладают рядом важных преимуществ, которых нет у более крупных моделей. SLM дешевле в настройке, требуют меньше вычислений и могут работать на устройстве даже в условиях отсутствия доступа к Интернету.
Развертывание SLM на границе обеспечивает меньшую задержку и максимальную конфиденциальность, поскольку нет необходимости отправлять данные в облако и обратно.
Перед вами Себастьен Бубек, вице-президент по исследованиям GenAI в Microsoft AI, с демонстрацией Phi-3 Mini. Он очень быстрый и впечатляющий для такой маленькой модели.
phi-3 уже здесь, и это... хорошо :-).
Я сделал короткую демонстрацию, чтобы дать вам представление о том, на что способен phi-3-mini (3.8B). Оставайтесь с нами и следите за открытыми весами и другими объявлениями завтра утром!
(И, конечно, эта статья была бы неполной без обычной таблицы бенчмарков). pic.twitter.com/AWA7Km59rp
- Себастьен Бубек (@SebastienBubeck) 23 апреля 2024 года
Курируемые синтетические данные
Phi-3 Mini - это результат отказа от идеи, что огромные объемы данных - единственный способ обучить модель.
Себастьен Бубек, вице-президент Microsoft по исследованиям в области генеративного ИИ, спрашивает: "Вместо того чтобы тренироваться на сырых веб-данных, почему бы вам не искать данные исключительно высокого качества?"
Эксперт по машинному обучению Microsoft Research Ронен Элдан читал своей дочери сказки на ночь, когда ему стало интересно, сможет ли языковая модель обучаться, используя только те слова, которые понимает четырехлетний ребенок.
Это привело к эксперименту, в ходе которого они создали набор данных, начинающийся с 3 000 слов. Используя только этот ограниченный словарный запас, они побудили LLM создать миллионы коротких детских историй, которые были собраны в набор данных под названием TinyStories.
Затем исследователи использовали TinyStories для обучения чрезвычайно маленькой модели с 10 миллионами параметров, которая впоследствии смогла генерировать "беглые рассказы с идеальной грамматикой".
Они продолжили итерации и масштабирование этого подхода к созданию синтетических данных, чтобы создать более сложные, но тщательно контролируемые и отфильтрованные синтетические наборы данных, которые в итоге были использованы для обучения Phi-3 Mini.
В результате получилась миниатюрная модель, которая будет более доступна по цене и при этом обеспечит производительность, сравнимую с GPT-3.5.
Более компактные, но более способные модели позволят компаниям отказаться от использования по умолчанию крупных LLM, таких как GPT-4. Вскоре мы также можем увидеть решения, в которых LLM выполняет тяжелую работу, но делегирует более простые задачи легким моделям.



