

Google's DeepMind Компания Gecko выпустила новый эталон для всесторонней оценки моделей преобразования текста в изображение (T2I) с помощью ИИ.
За последние два года мы увидели такие генераторы изображений с искусственным интеллектом, как DALL-E и Середина путешествия с каждым выпуском версии становятся все лучше и лучше.
Однако решение о том, какая из базовых моделей, используемых этими платформами, является лучшей, во многом субъективно и с трудом поддается контролю.
Утверждать, что одна модель "лучше" другой, не так-то просто. Разные модели превосходят друг друга в различных аспектах создания изображений. Одна может быть хороша в рендеринге текста, а другая - в взаимодействии с объектами.
Основная задача, стоящая перед моделями T2I, - проследить за каждой деталью в подсказке и точно отразить их в сгенерированном изображении.
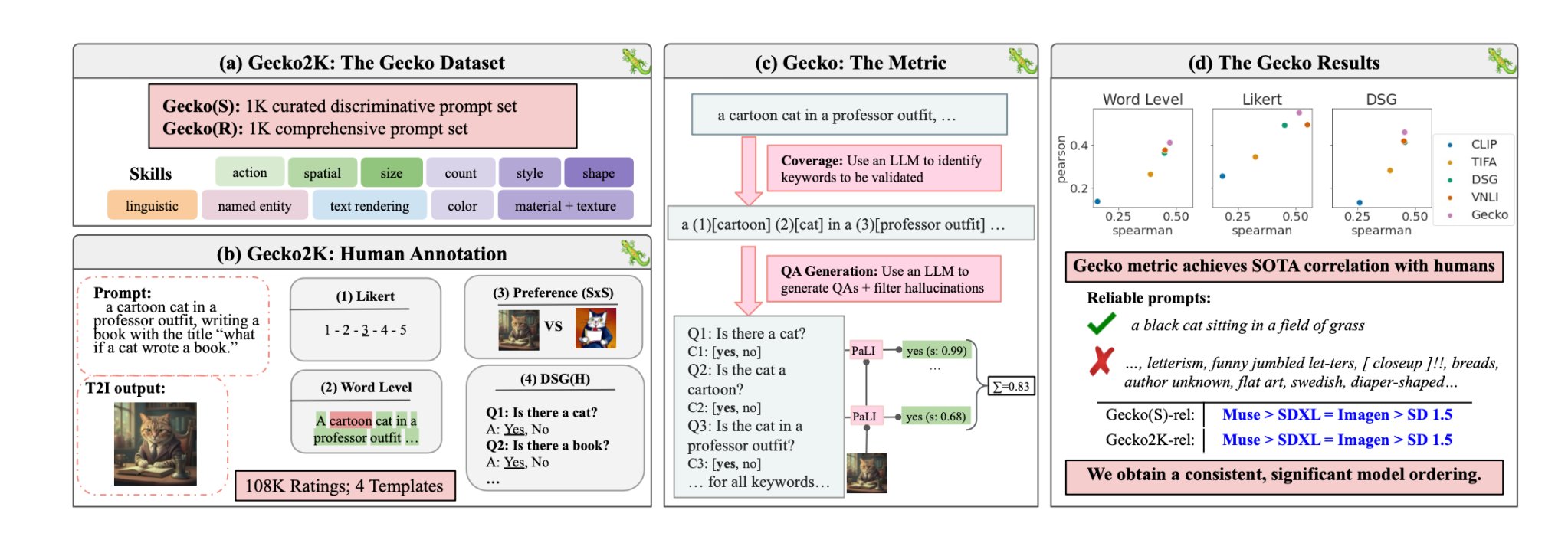
С помощью Gecko DeepMind исследователи создали эталон которая оценивает возможности моделей T2I аналогично тому, как это делают люди.
Набор навыков
Сначала исследователи определили всеобъемлющий набор навыков, имеющих отношение к созданию T2I. К ним относятся пространственное понимание, распознавание действий, визуализация текста и другие. Далее они разделили их на более конкретные поднавыки.
Например, в разделе "Рендеринг текста" поднавыки могут включать рендеринг различных шрифтов, цветов или размеров текста.
Затем с помощью LLM были сгенерированы подсказки для проверки возможностей модели T2I по определенному навыку или поднавыку.
Это позволяет создателям модели T2I точно определить не только то, какие навыки являются сложными, но и то, на каком уровне сложности тот или иной навык становится сложным для их модели.
Оценка "человек против авто
Gecko также измеряет, насколько точно модель T2I следует всем деталям в подсказке. Опять же, LLM использовался для выделения ключевых деталей в каждой подсказке, а затем генерировал набор вопросов, связанных с этими деталями.
Это могут быть как простые, прямые вопросы о видимых элементах изображения (например, "Есть ли на картинке кошка?"), так и более сложные вопросы, проверяющие понимание сцены или отношений между объектами (например, "Сидит ли кошка над книгой?").
Затем модель Visual Question Answering (VQA) анализирует сгенерированное изображение и отвечает на вопросы, чтобы определить, насколько точно модель T2I согласует выходное изображение с входной подсказкой.
Исследователи собрали более 100 000 человеческих аннотаций, в которых участники оценивали сгенерированное изображение в зависимости от того, насколько оно соответствует определенным критериям.
Людей просили рассмотреть конкретный аспект входной подсказки и оценить изображение по шкале от 1 до 5 в зависимости от того, насколько оно соответствует подсказке.
Используя человеческие оценки в качестве золотого стандарта, исследователи смогли подтвердить, что их метрика автооценки "лучше коррелирует с человеческими оценками, чем существующие метрики для нашего нового набора данных".
В результате получилась система бенчмаркинга, которая способна обозначить конкретные факторы, делающие сгенерированное изображение хорошим или плохим.
Gecko, по сути, оценивает выходное изображение так, чтобы оно соответствовало тому, как мы интуитивно решаем, довольны ли мы сгенерированным изображением.
Так какая же модель преобразования текста в изображение является лучшей?
На сайте их газетаИсследователи пришли к выводу, что модель Muse от Google выигрывает у Stable Diffusion 1.5 и SDXL в бенчмарке Gecko. Они могут быть необъективны, но цифры не лгут.



