

Исследователи из DeepMind и Стэнфордского университета разработали ИИ-агент, который проверяет фактологию LLM и позволяет проводить сравнительный анализ фактологичности ИИ-моделей.
Даже самые лучшие модели искусственного интеллекта по-прежнему склонны галлюцинировать иногда. Если вы попросите ChatGPT предоставить вам факты по теме, то чем длиннее будет ответ, тем больше вероятность того, что в нем окажутся неправдивые факты.
Какие модели более точны в фактах, чем другие, при создании длинных ответов? Сложно сказать, потому что до сих пор у нас не было эталона, измеряющего фактичность длинных ответов LLM.
Сначала DeepMind использовала GPT-4 для создания LongFact - набора из 2280 подсказок в виде вопросов, относящихся к 38 темам. Эти подсказки вызывают у тестируемого LLM развернутые ответы.
Затем они создали ИИ-агент, использующий GPT-3.5-turbo, чтобы с помощью Google проверить, насколько фактичны ответы, сгенерированные LLM. Они назвали этот метод Search-Augmented Factuality Evaluator (SAFE).
SAFE сначала разбивает длинный ответ LLM на отдельные факты. Затем он отправляет поисковые запросы в Google Search и определяет правдивость факта на основе информации, полученной в результатах поиска.
Вот пример из научная статья.
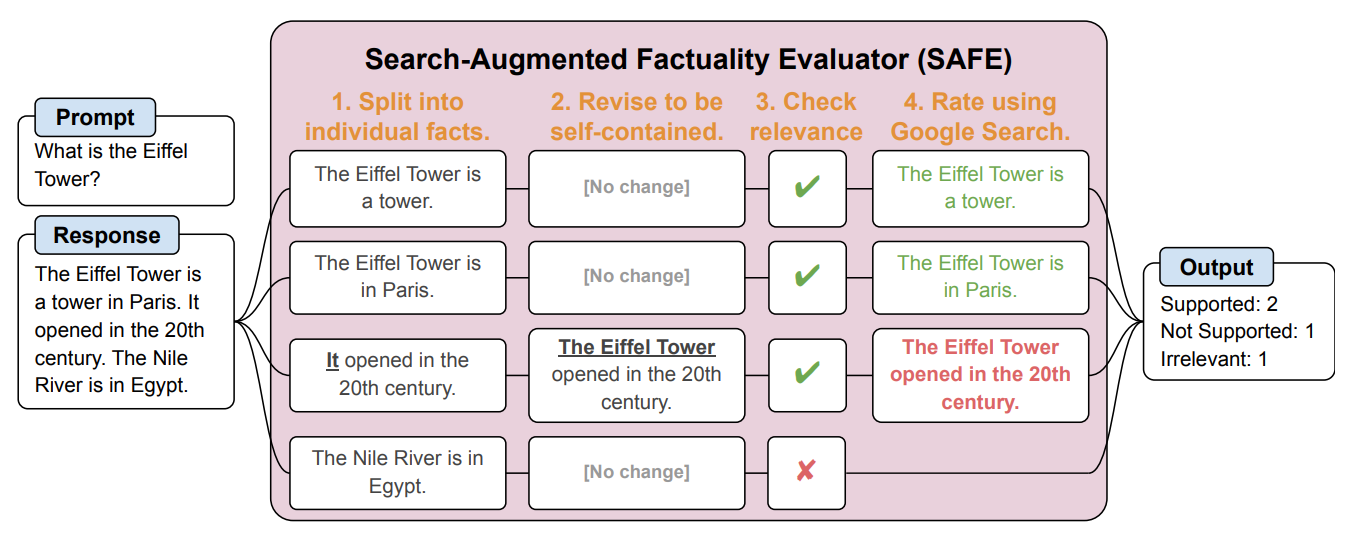
Исследователи утверждают, что SAFE достигает "сверхчеловеческой производительности" по сравнению с человеческими аннотаторами, выполняющими проверку фактов.
SAFE согласился с 72% человеческих аннотаций, а там, где его мнение расходилось с человеческим, он оказался прав в 76% случаев. Кроме того, эта система оказалась в 20 раз дешевле, чем краудсорсинговые человеческие аннотаторы. Таким образом, LLM лучше и дешевле проверяют факты, чем люди.
Качество ответа испытуемых LLM оценивалось по количеству фактоидов в ответе, а также по тому, насколько фактоидами были отдельные факты.
Используемая ими метрика (F1@K) оценивает предпочтительное для человека "идеальное" количество фактов в ответе. В эталонных тестах в качестве медианы для K использовалось 64, а в качестве максимума - 178.
Проще говоря, F1@K - это показатель "Предоставил ли ответ мне столько фактов, сколько я хотел?" в сочетании с "Сколько из этих фактов оказались правдивыми?".
Какой LLM является наиболее актуальным?
Исследователи использовали LongFact, чтобы предложить 13 LLM из семейств Gemini, GPT, Claude и PaLM-2. Затем они использовали SAFE для оценки фактичности их ответов.
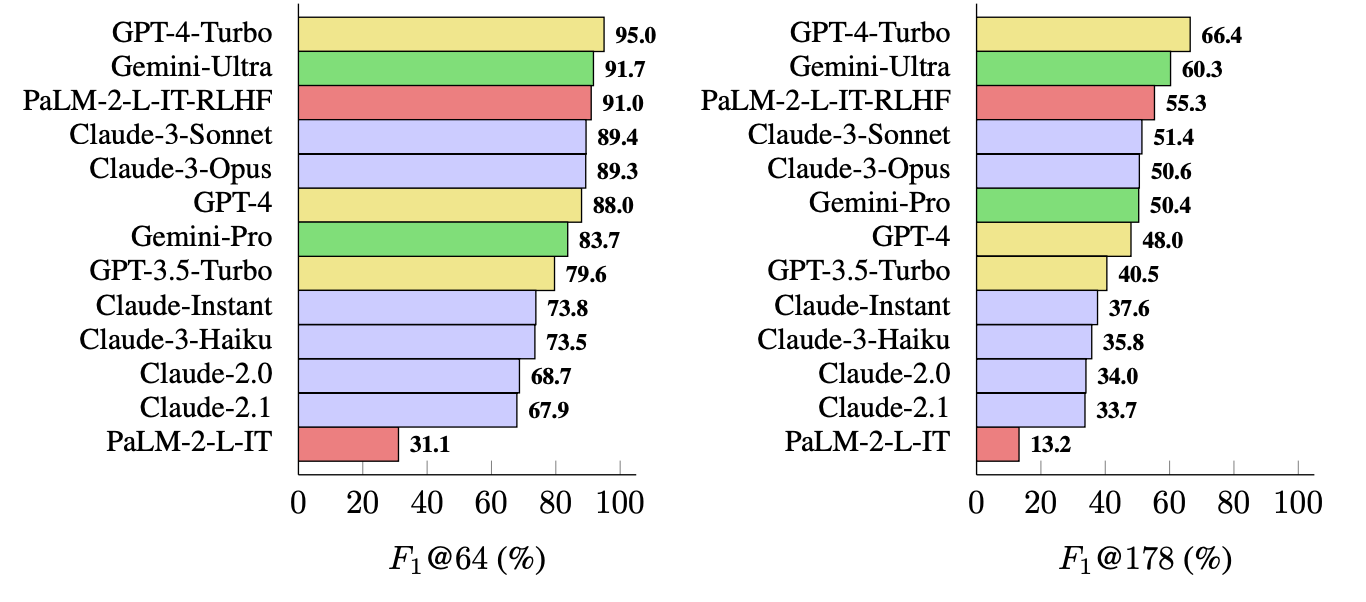
GPT-4-Turbo возглавляет список самых фактографичных моделей при генерации длинных ответов. За ней следуют Gemini-Ultra и PaLM-2-L-IT-RLHF. Результаты показали, что большие LLM более фактографичны, чем маленькие.
Вычисления F1@K, вероятно, порадуют специалистов по обработке данных, но для простоты мы приводим результаты эталонных расчетов, которые показывают, насколько точна каждая модель при возвращении ответов средней длины и более длинных ответов на вопросы.
SAFE - это дешевый и эффективный способ количественной оценки фактологичности длинных форм LLM. Он быстрее и дешевле, чем люди, проверяет факты, но все равно зависит от правдивости информации, которую Google выдает в результатах поиска.
DeepMind выпустила SAFE для публичного использования и предположила, что он может помочь улучшить фактологичность LLM за счет лучшего предварительного обучения и тонкой настройки. Она также может позволить LLM проверять свои факты перед тем, как представить результат пользователю.
OpenAI будет рад увидеть, что исследование Google показало, что GPT-4 побеждает Gemini в еще одном бенчмарке.



