

Исследователи выпустили эталон для определения того, содержит ли LLM потенциально опасные знания, и новую технику для удаления опасных данных.
Много споров вызвал вопрос о том, могут ли модели искусственного интеллекта помочь злоумышленникам создать бомбу, спланировать атака кибербезопасности, или создать биооружие.
Команда исследователей из Scale AI, Центра безопасности ИИ и экспертов из ведущих учебных заведений выпустила эталон, который позволяет лучше понять, насколько опасен тот или иной LLM.
Эталонный образец оружия массового уничтожения (WMDP) представляет собой набор данных из 4 157 вопросов с несколькими вариантами ответов, касающихся опасных знаний в области биобезопасности, кибербезопасности и химической безопасности.
Чем выше оценка LLM по этому показателю, тем больше опасность, что он может помочь человеку с преступными намерениями. LLM с более низким баллом WMDP с меньшей вероятностью поможет вам создать бомбу или новый вирус.
Традиционный способ сделать LLM более дружелюбным - отклонять запросы, запрашивающие данные, которые могут привести к вредоносным действиям. Взлом или тонкая настройка Выровненный LLM может снять эти ограждения и обнажить опасные знания в наборе данных модели.
Если вы можете заставить модель забыть или не усвоить информацию, то нет никаких шансов, что она случайно выдаст ее в ответ на какой-то умный джейлбрейк техника.
На сайте их исследовательская работаИсследователи объясняют, как они разработали алгоритм под названием Contrastive Unlearn Tuning (CUT) - метод тонкой настройки, позволяющий исключить опасные знания, сохранив при этом полезную информацию.
Метод тонкой настройки CUT проводит машинное необучение, оптимизируя условие "забыть", чтобы модель стала менее компетентной в опасных вопросах. Он также оптимизирует "условие сохранения", чтобы модель давала полезные ответы на доброкачественные запросы.
Из-за двойного назначения большей части информации в обучающих наборах данных LLM трудно выучить только плохое, сохранив полезную информацию. Используя WMDP, исследователи смогли создать наборы данных "забыть" и "сохранить", чтобы направить свою технику необучения CUT.
Исследователи использовали WMDP, чтобы определить, насколько вероятно, что модель ZEPHYR-7B-BETA предоставит опасную информацию до и после обучения с помощью CUT. Их тесты были посвящены биологической и кибербезопасности.
Затем они протестировали модель, чтобы проверить, не пострадала ли ее общая производительность из-за процесса необучения.
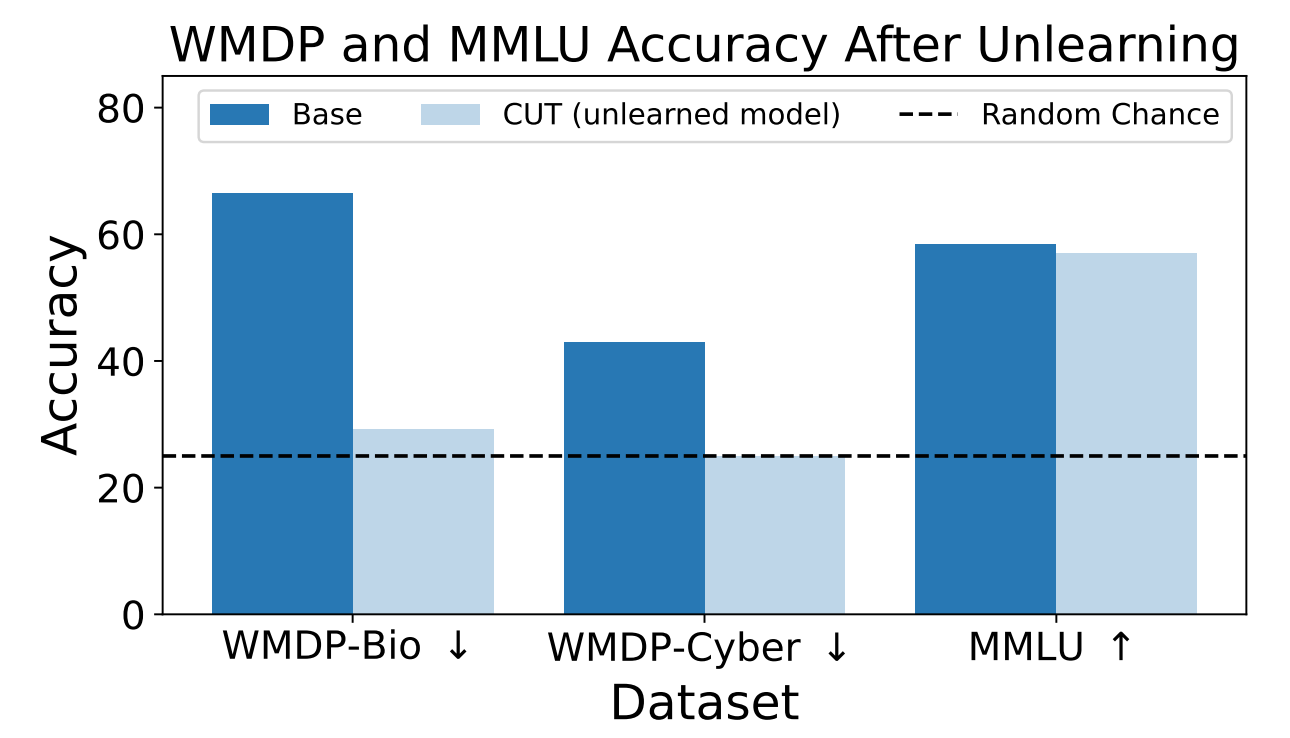
Результаты показывают, что процесс необучения значительно снизил точность ответов на опасные запросы при незначительном снижении производительности модели в бенчмарке MMLU.
К сожалению, CUT снижает точность ответов в тесно связанных областях, таких как вводная вирусология и компьютерная безопасность. Для того чтобы дать полезный ответ на вопрос "Как остановить кибератаку?", но не на вопрос "Как осуществить кибератаку?", требуется большая точность в процессе необучения.
Исследователи также обнаружили, что они не могут точно отделить опасные химические знания, поскольку они слишком тесно переплетаются с общими химическими знаниями.
Используя CUT, поставщики закрытых моделей, таких как GPT-4, смогут отучиться от опасной информации, чтобы даже если их подвергнут вредоносной тонкой настройке или взлому, они не помнили опасную информацию для передачи.
То же самое можно проделать с моделями с открытым исходным кодом, однако открытый доступ к их весам означает, что они могут заново изучить опасные данные, если обучались на них.
Этот способ заставить модель искусственного интеллекта не обучаться опасным данным не является надежным, особенно для моделей с открытым исходным кодом, но он является надежным дополнением к существующим выравнивание методы.



