

Apple еще не выпустила официальную модель с искусственным интеллектом, но новое исследование дает представление о прогрессе компании в разработке моделей с самыми современными мультимодальными возможностями.
ГазетаСтатья под названием "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", представляет семейство МЛМ от Apple под названием MM1.
MM1 демонстрирует впечатляющие способности к созданию подписей к изображениям, визуальным ответам на вопросы (VQA) и выводам на естественном языке. Исследователи объясняют, что тщательный подбор пар "изображение - подпись" позволил им добиться превосходных результатов, особенно в сценариях обучения с небольшим количеством снимков.
От других МЛМ MM1 отличает превосходная способность следовать инструкциям на нескольких изображениях и рассуждать о сложных сценах, которые ему предъявляются.
Модели MM1 содержат до 30B параметров, что в три раза больше, чем у GPT-4V, компонента, который обеспечивает GPT-4 от OpenAI возможностями видения.
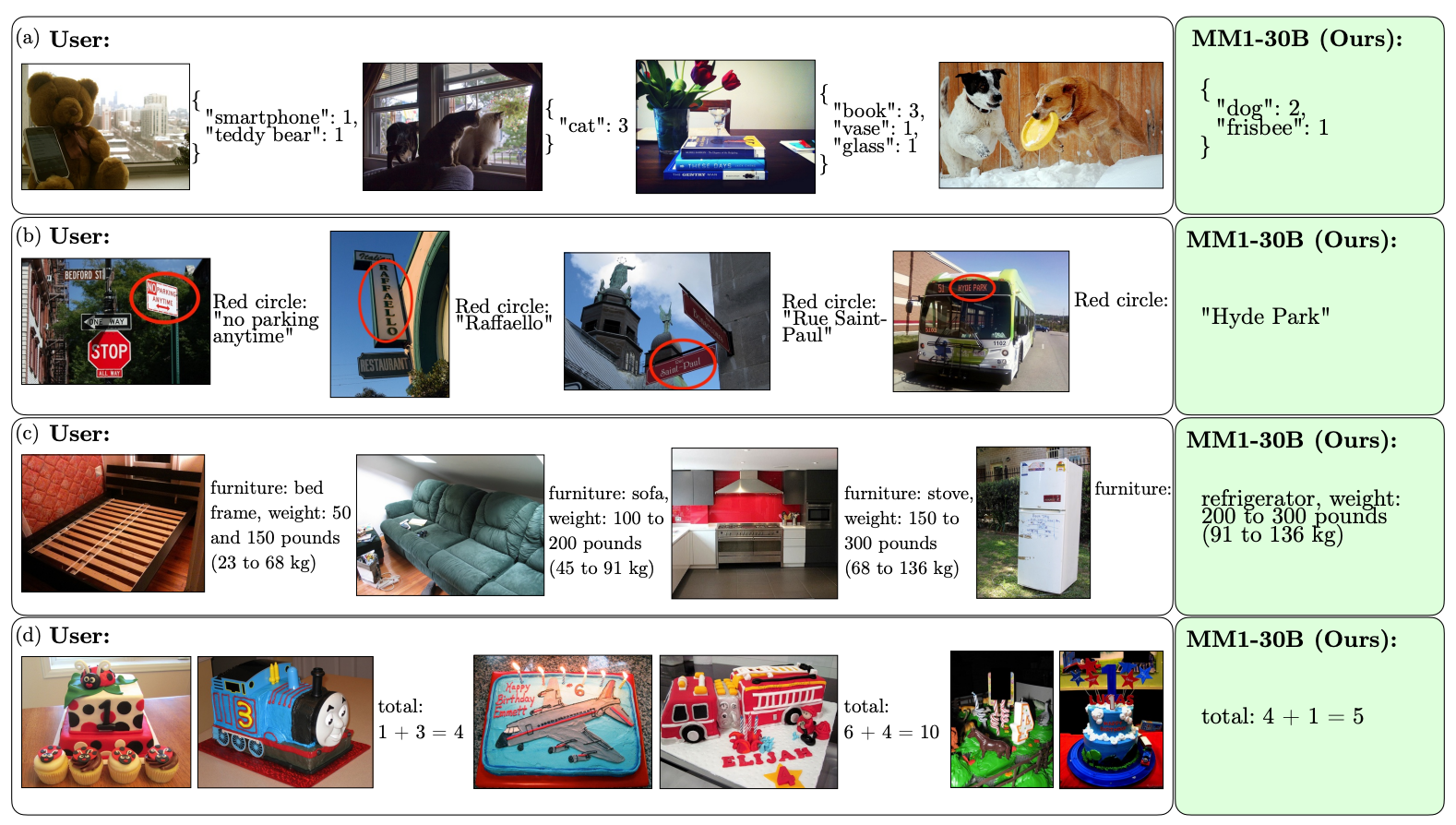
Вот несколько примеров способностей MM1 к VQA.

MM1 прошел масштабное мультимодальное предварительное обучение на "наборе данных из 500M чередующихся изображений и текстовых документов, содержащих 1B изображений и 500B текстовых лексем".
Масштаб и разнообразие предварительного обучения позволяют MM1 выполнять впечатляющие контекстные предсказания и выполнять пользовательское форматирование на небольшом количестве примеров. Вот примеры того, как MM1 обучается желаемому выводу и формату всего на 3 примерах.
Для создания моделей ИИ, которые могут "видеть" и рассуждать, необходим коннектор "зрение-язык", который переводит изображения и язык в единое представление, используемое моделью для дальнейшей обработки.
Исследователи обнаружили, что дизайн коннектора "зрение-язык" в меньшей степени повлиял на производительность MM1. Интересно, что наибольшее влияние оказали разрешение изображения и количество маркеров изображения.
Интересно видеть, насколько открыто Apple делится своими исследованиями с широким сообществом ИИ. Исследователи заявляют, что "в этой статье мы документируем процесс создания MLLM и пытаемся сформулировать уроки дизайна, которые, как мы надеемся, будут полезны для сообщества".
Опубликованные результаты, вероятно, помогут другим разработчикам MMLM определиться с выбором архитектуры и данных для предварительного обучения.
Как именно модели MM1 будут реализованы в продуктах Apple, пока неизвестно. Опубликованные примеры возможностей MM1 намекают на то, что Siri станет намного умнее, когда научится видеть.



