

Несмотря на быстрый прогресс в области LLM, наше понимание того, как эти модели справляются с длинными входными данными, остается недостаточным.
Мош Леви, Алон Якоби и Йоав Голдберг из Университета Бар-Илана и Института искусственного интеллекта Аллена исследовали, как меняется производительность больших языковых моделей (LLM) при изменении длины входного текста, который им предлагается обработать.
Специально для этого они разработали систему рассуждений, которая позволила им изучить влияние длины входных данных на рассуждения LLM в контролируемой среде.
Система вопросов предлагала различные варианты одного и того же вопроса, каждый из которых содержал необходимую для ответа информацию, дополненную дополнительным, не относящимся к делу текстом разной длины и типа.
Это позволяет выделить длину входного сигнала в качестве переменной, гарантируя, что изменения в работе модели могут быть отнесены непосредственно к длине входного сигнала.
Основные выводы
Леви, Якоби и Голдберг обнаружили, что LLM демонстрируют заметное снижение эффективности рассуждений при длине входных данных намного меньше той, которую, как утверждают разработчики, они могут обрабатывать. Они задокументировали свои выводы в данном исследовании.
Спад наблюдался во всех версиях набора данных, что указывает на системную проблему с обработкой более длинных входных данных, а не на проблему, связанную с конкретными образцами данных или архитектурой модели.
Как пишут исследователи: "Наши результаты свидетельствуют о заметном снижении эффективности рассуждений LLM при гораздо меньшей длине входных данных, чем их технический максимум. Мы показали, что тенденция к ухудшению проявляется в каждой версии нашего набора данных, хотя и с разной интенсивностью".

Более того, исследование показывает, что традиционные метрики, такие как недоумение, обычно используемые для оценки LLM, не коррелируют с производительностью моделей в задачах рассуждения с длинными входными данными.
Дальнейшее исследование показало, что снижение производительности зависит не только от наличия нерелевантной информации (подложки), но наблюдается даже тогда, когда такая подложка состоит из дублирующей релевантной информации.
Когда мы сохраняем два основных пролета вместе и добавляем текст вокруг них, точность уже падает. При добавлении абзацев между пролетами результаты падают гораздо сильнее. Падение происходит как в тех случаях, когда добавляемые тексты похожи на тексты заданий, так и в тех, когда они совершенно другие. 3/7 pic.twitter.com/c91l9uzyme
- Мош Леви (@mosh_levy) 26 февраля 2024 года
Это говорит о том, что задача LLM заключается в отфильтровывании шумов и обработке длинных текстовых последовательностей.
Игнорирование инструкций
Одной из критических областей, выявленных в ходе исследования, является тенденция LLM игнорировать инструкции, встроенные во входные данные, по мере увеличения длины входных данных.
Модели также иногда генерировали ответы, указывающие на неопределенность или отсутствие достаточной информации, например "В тексте недостаточно информации", несмотря на наличие всей необходимой информации.
В целом, по мере увеличения длины входных данных, LLM, похоже, постоянно испытывают трудности с определением приоритетов и фокусировкой на ключевых информационных фрагментах, включая прямые инструкции.
Проявление предвзятости в ответах
Еще одной заметной проблемой было увеличение погрешности в ответах моделей при увеличении длины входных данных.
В частности, при увеличении длины входных данных LLM склонялись к ответу "Ложь". Такое смещение указывает на перекос в оценке вероятности или процессах принятия решений в модели, возможно, как защитный механизм в ответ на увеличение неопределенности из-за большей длины входных данных.
Склонность к "ложным" ответам может также отражать дисбаланс в обучающих данных или артефакт процесса обучения моделей, где негативные ответы могут быть перепредставлены или связаны с контекстами неопределенности и двусмысленности.
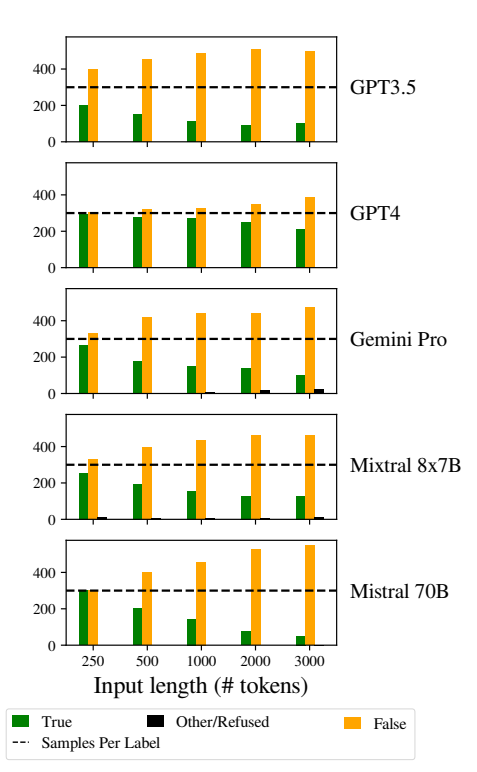
Эта предвзятость влияет на точность результатов моделей и вызывает сомнения в надежности и справедливости LLM в приложениях, требующих тонкого понимания и беспристрастности.
Внедрение надежных стратегий обнаружения и смягчения смещений на этапах обучения и точной настройки модели очень важно для уменьшения необоснованных смещений в ответах модели.
EОбеспечение того, что обучающие наборы данных разнообразны, сбалансированы и представляют широкий спектр сценариев, также может помочь минимизировать смещения и улучшить обобщение модели.
Это способствует другие недавние исследования которые также выявляют фундаментальные проблемы в работе LLM, что приводит к ситуации, когда "технический долг" может со временем поставить под угрозу функциональность и целостность модели.



