

Исследователи из Калифорнийского университета в Сан-Диего и Нью-Йоркского университета разработали V* - алгоритм поиска с LLM-наведением, который гораздо лучше GPT-4V справляется с пониманием контекста и точным наведением на конкретные визуальные элементы в изображениях.
Мультимодальные модели большого языка (MLLM), такие как GPT-4V от OpenAI, поразили нас в прошлом году своей способностью отвечать на вопросы об изображениях. Как бы ни был впечатляющ GPT-4V, иногда он испытывает трудности, когда изображения очень сложные, и часто упускает мелкие детали.
Алгоритм V* использует LLM Visual Question Answering (VQA), чтобы определить, на какой области изображения следует сосредоточиться, чтобы ответить на визуальный запрос. Исследователи называют эту комбинацию Show, sEArch и telL (SEAL).
Если бы кто-то дал вам изображение высокого разрешения и задал вопрос о нем, ваша логика подсказала бы вам, что нужно приблизить область, где вы с наибольшей вероятностью найдете искомый предмет. SEAL использует V* для анализа изображений аналогичным образом.
Модель визуального поиска может просто разделить изображение на блоки, увеличить масштаб каждого блока и затем обработать его, чтобы найти нужный объект, но это очень неэффективно с вычислительной точки зрения.
При получении текстового запроса об изображении V* сначала пытается найти цель изображения напрямую. Если это не удается, он просит MLLM использовать здравый смысл, чтобы определить, в какой области изображения, скорее всего, находится цель.
Затем он фокусирует поиск только на этой области, а не пытается выполнить поиск "с увеличением" по всему изображению.

Когда GPT-4V предлагается ответить на вопросы об изображении, требующем обширной визуальной обработки изображений высокого разрешения, он испытывает трудности. SEAL, использующий V*, справляется гораздо лучше.

На вопрос "Какой напиток мы можем купить в этом торговом автомате?" SEAL ответил "Coca-Cola", а GPT-4V неверно угадал "Pepsi".
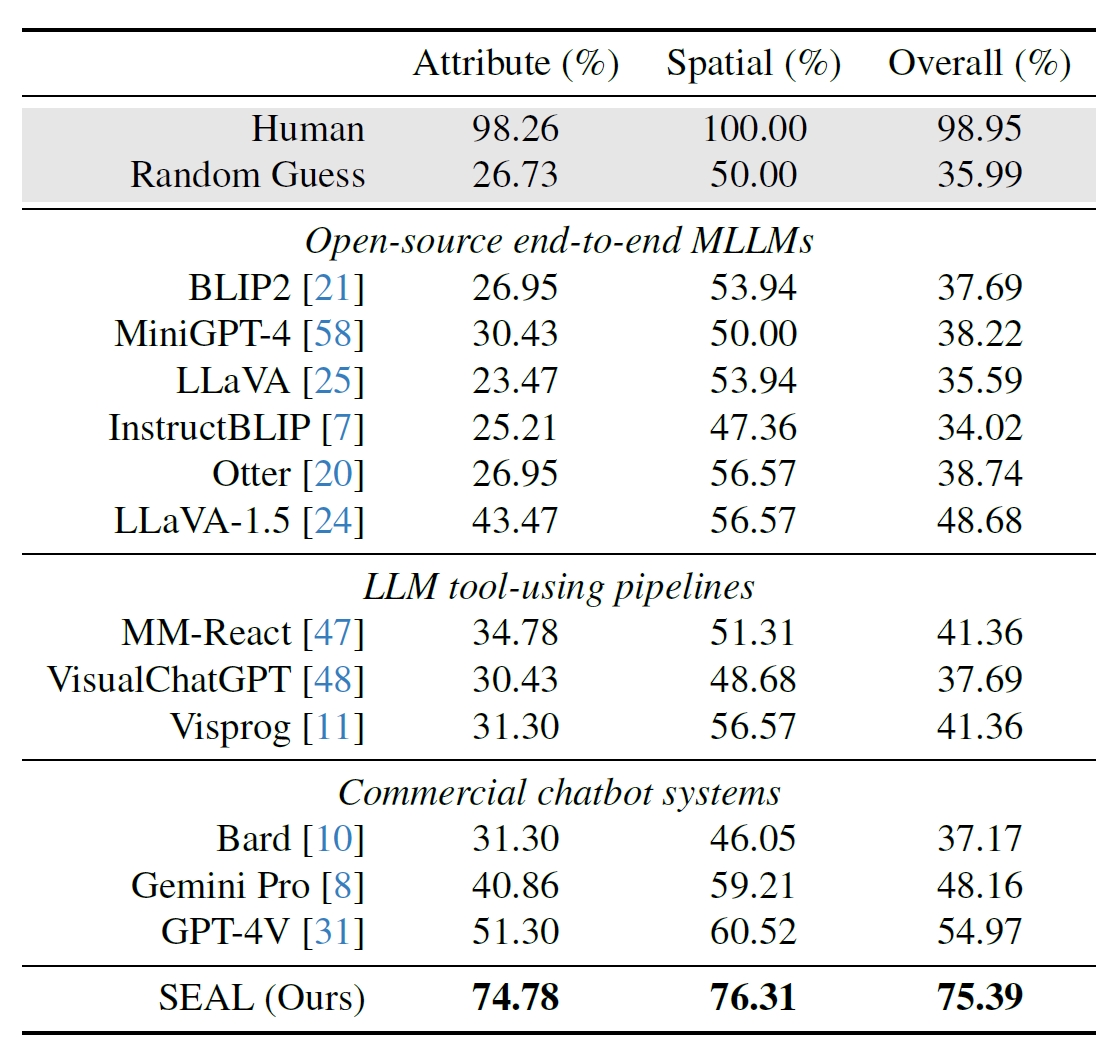
Исследователи использовали 191 изображение высокого разрешения из набора данных Segment Anything (SAM) компании Meta и создали бенчмарк, чтобы увидеть, как производительность SEAL сравнивается с другими моделями. В бенчмарке V*Bench тестируются две задачи: распознавание атрибутов и рассуждения о пространственных отношениях.
На рисунках ниже показана производительность человека в сравнении с моделями с открытым исходным кодом, коммерческими моделями, такими как GPT-4V, и SEAL. Увеличение производительности SEAL за счет V* особенно впечатляет, поскольку в основе используемой им MLLM лежит LLaVa-7b, которая намного меньше GPT-4V.
Этот интуитивный подход к анализу изображений, похоже, действительно хорошо работает, и на сайте можно найти множество впечатляющих примеров. Резюме статьи на GitHub.
Будет интересно посмотреть, примут ли подобный подход другие MLLM, например, от OpenAI или Google.
На вопрос, какой напиток продается из торгового автомата на фотографии выше, Бард из Google ответил: "На переднем плане нет торгового автомата". Возможно, Gemini Ultra справится с этой задачей лучше.
Пока что кажется, что SEAL и его новый алгоритм V* опережают некоторые из самых больших мультимодальных моделей на некоторое расстояние, когда дело доходит до визуального опроса.



