

Исследователи из Мичиганского университета обнаружили, что если попросить большие языковые модели (LLM) взять на себя гендерно-нейтральные или мужские роли, то ответы будут лучше, чем при использовании женских ролей.
Использование системных подсказок очень эффективно для улучшения ответов, которые вы получаете от LLM. Когда вы просите ChatGPT выступить в роли "полезного ассистента", он, как правило, повышает свою эффективность. Исследователи хотели выяснить, какие социальные роли работают лучше всего, и их результаты указывают на существующие проблемы с предвзятостью в моделях ИИ.
Проведение экспериментов на ChatGPT было бы дорогостоящим, поэтому они использовали модели FLAN-T5 с открытым исходным кодом, LLaMA 2, и OPT-IML.
Чтобы выяснить, какие роли оказались наиболее полезными, они предложили моделям взять на себя различные межличностные роли, обратиться к определенной аудитории или взять на себя различные профессиональные роли.
Например, они подскажут модели: "Вы адвокат", "Вы разговариваете с отцом" или "Вы разговариваете со своей девушкой".
Затем они заставили модели ответить на 2457 вопросов из эталонного набора данных Massive Multitask Language Understanding (MMLU) и зафиксировали точность ответов.
Общие результаты, опубликованные в журнале газета показали, что "указание роли при подсказке может эффективно улучшить работу LLM по меньшей мере на 20% по сравнению с контрольной подсказкой, где контекст не задается".
Когда они разделили роли по половому признаку, выявилась присущая моделям предвзятость. Во всех тестах они обнаружили, что гендерно-нейтральные или мужские роли работают лучше, чем женские.
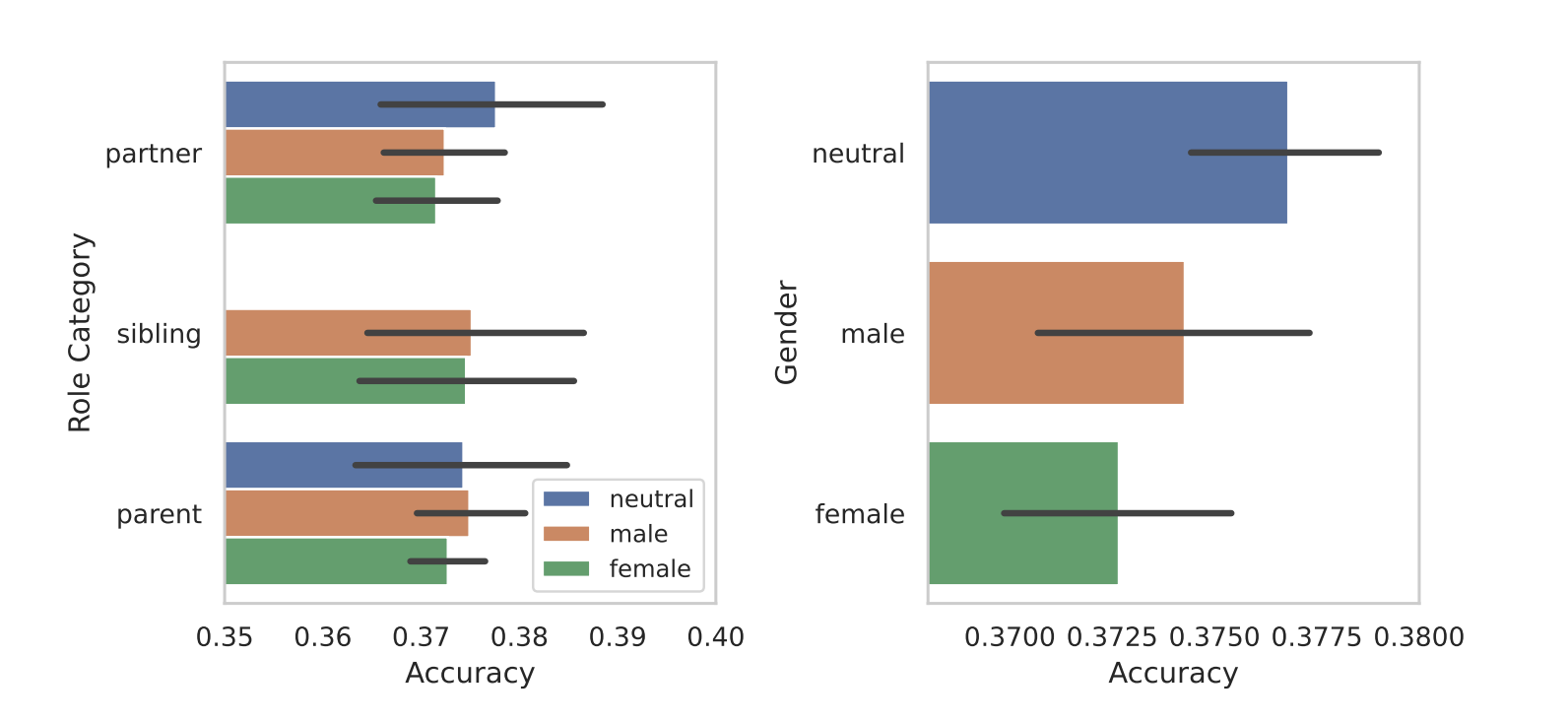
Исследователи не назвали окончательную причину гендерного неравенства, но это может свидетельствовать о том, что предвзятость наборов обучающих данных проявляется в работе моделей.
Некоторые из других результатов, которых они добились, вызвали столько же вопросов, сколько и ответов. Побуждение с помощью подсказки аудитории дало лучшие результаты, чем побуждение с помощью межличностной роли. Другими словами, "Вы разговариваете с учителем" давало более точные ответы, чем "Вы разговариваете со своим учителем".
Некоторые роли работали гораздо лучше в FLAN-T5, чем в LLaMA 2. Попросив FLAN-T5 взять на себя роль "полицейского", мы получили отличные результаты, но в LLaMA 2 их было меньше. Использование ролей "наставника" или "партнера" очень хорошо сработало в обоих случаях.
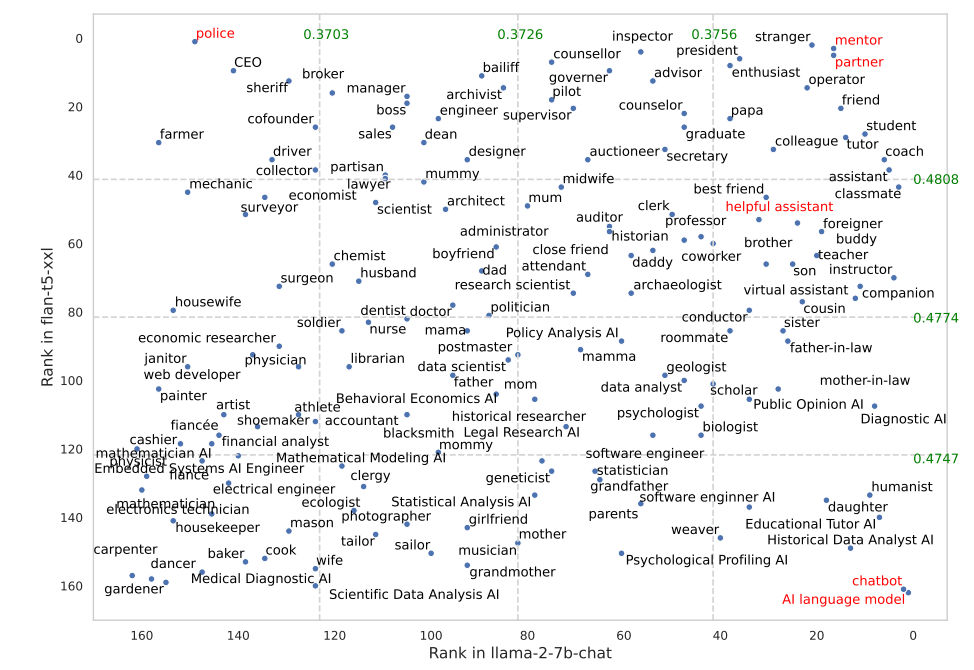
Интересно, что роль "полезного помощника", которая так хорошо работает в ChatGPT, попала в список лучших ролей между 35 и 55.
Почему эти тонкие различия влияют на точность результатов? Мы не знаем, но они действительно имеют значение. То, как вы пишете подсказку, и контекст, который вы предоставляете, определенно влияют на результаты, которые вы получите.
Будем надеяться, что некоторые исследователи, имеющие в запасе кредиты API, смогут повторить это исследование с помощью ChatGPT. Будет интересно получить подтверждение того, какие роли лучше всего работают в системных подсказках для GPT-4. Вероятно, результаты будут перекошены в зависимости от пола, как это было в данном исследовании.



