

Большие языковые модели (LLM) часто вводятся в заблуждение предвзятостью или нерелевантным контекстом в подсказке. Исследователи из Meta нашли простой на первый взгляд способ исправить это.
По мере увеличения контекстных окон подсказки, которые мы вводим в LLM, могут становиться все более длинными и подробными. LLM стали лучше улавливать нюансы и мелкие детали в наших подсказках, но иногда это может сбить их с толку.
В ранних версиях машинного обучения использовался подход "жесткого внимания", который выделял наиболее значимую часть входных данных и реагировал только на нее. Это хорошо работает, когда вы пытаетесь создать подпись к изображению, но плохо - когда вы переводите предложение или отвечаете на многослойный вопрос.
Большинство LLM сейчас используют подход "мягкого внимания", при котором лексема обрабатывается полностью и присваивается вес каждой подсказке.
Мета предлагает подход под названием Система 2 Внимание (S2A), чтобы получить лучшее из двух миров. S2A использует способность LLM к обработке естественного языка, чтобы получить ваш запрос и отсеять предвзятую и неактуальную информацию, прежде чем приступить к работе над ответом.
Вот пример.

S2A избавляется от информации, касающейся Макса, поскольку она не имеет отношения к вопросу. S2A регенерирует оптимизированную подсказку перед началом работы над ней. Известно, что LLM плохо справляются с математика поэтому сделать подсказку менее запутанной будет очень полезно.
LLM - люди приятные и с удовольствием согласятся с вами, даже если вы не правы. S2A устраняет любую предвзятость в подсказке, а затем обрабатывает только релевантные части подсказки. Это уменьшает то, что исследователи ИИ называют "подхалимством", или склонность модели ИИ к подлизыванию задницы.

S2A - это всего лишь системная подсказка, которая дает команду LLM немного доработать исходную подсказку, прежде чем приступить к работе над ней. Результаты, которых исследователи добились в математике, фактологии и длинных вопросах, впечатляют.
В качестве примера можно привести улучшения, достигнутые S2A в вопросах о фактах. Базовым уровнем были ответы на вопросы, содержащие предвзятость, а подсказка Oracle была идеальной подсказкой, уточненной человеком.
S2A очень близок к результатам подсказки Oracle и обеспечивает почти 50% улучшение точности по сравнению с базовой подсказкой.
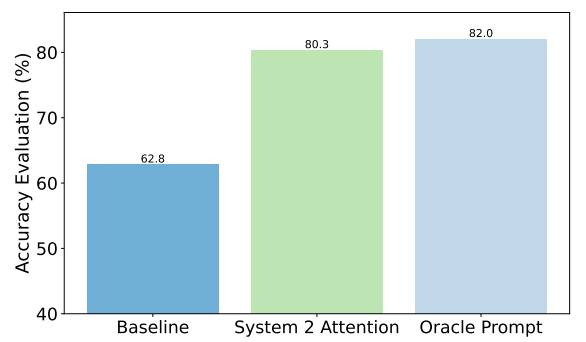
Так в чем же загвоздка? Предварительная обработка исходной подсказки перед ответом на нее добавляет дополнительные вычислительные требования к процессу. Если запрос длинный и содержит много релевантной информации, регенерация запроса может привести к значительным затратам.
Пользователи вряд ли станут лучше в написании хорошо продуманных подсказок, поэтому S2A может стать хорошим способом обойти эту проблему.
Будет ли Meta встраивать S2A в свой Ллама модель? Мы не знаем, но вы сами можете использовать подход S2A.
Если вы будете тщательно избегать мнений и наводящих предложений в своих подсказках, то с большей вероятностью получите точные ответы от этих моделей.



