

O colonialismo digital refere-se ao domínio dos gigantes da tecnologia e de entidades poderosas sobre a paisagem digital, moldando o fluxo de informação, conhecimento e cultura para servir os seus interesses.
Este domínio não se limita a controlar a infraestrutura digital, mas também a influenciar as narrativas e as estruturas de conhecimento que definem a nossa era digital.
O colonialismo digital, e agora o colonialismo da IA, são termos amplamente reconhecidos, e instituições como a O MIT investigou e escreveu sobre muito.
Investigadores de topo da Anthropic, da Google, da DeepMind e de outras empresas tecnológicas discutiram abertamente o âmbito limitado da IA na prestação de serviços a pessoas de diversas origens, em especial no que se refere a preconceito em sistemas de aprendizagem automática.
Sistemas de aprendizagem automática freflectem fundamentalmente os dados com que são treinados - dados que como tal, o zeitgeist digital é um conjunto de narrativas, imagens e ideias predominantes que dominam o mundo em linha.
Mas quem é que dá forma a estas forças informativas? Que vozes são amplificadas e quais são atenuadas?
Quando a IA aprende a partir de dados de treino, herda visões do mundo específicas que podem não ter necessariamente ressonância ou representar culturas e experiências globais. Além disso, os controlos que regem os resultados das ferramentas de IA generativa são moldados por vectores socioculturais subjacentes.
Isto levou os programadores, como a Anthropic, a procurar métodos democráticos de moldar o comportamento da IA através de opiniões públicas.
Como Jack Clark, chefe de política da Anthropic, descreveu uma experiência recente da sua empresa, "estamos a tentar encontrar uma forma de desenvolver uma constituição que seja desenvolvida por um conjunto de terceiros, em vez de por pessoas que por acaso trabalham num laboratório em São Francisco".
Os actuais paradigmas de formação em IA generativa correm o risco de criar uma câmara de eco digital onde as mesmas ideias, valores e perspectivas são continuamente reforçados, consolidando ainda mais o domínio daqueles que já estão sobre-representados nos dados.
À medida que a IA se integra em processos complexos de tomada de decisões, desde bem-estar social e recrutamento para decisões financeiras e diagnósticos médicosA representação desequilibrada conduz a preconceitos e injustiças no mundo real.
Os conjuntos de dados estão geográfica e culturalmente situados
Um recente estudo da iniciativa Data Provenance sondou 1800 conjuntos de dados populares destinados ao processamento de linguagem natural (PNL), uma disciplina da IA que se centra na linguagem e no texto.
A PNL é a metodologia de aprendizagem automática dominante por detrás dos grandes modelos de linguagem (LLM), incluindo os modelos ChatGPT e Meta's Llama.
O estudo revela um enviesamento ocidental na representação linguística dos conjuntos de dados, com o inglês e as línguas da Europa Ocidental a definirem os dados de texto.
As línguas dos países asiáticos, africanos e sul-americanos estão claramente sub-representadas.
Consequentemente, os LLM não podem esperar representar com exatidão as nuances culturais e linguísticas destas regiões da mesma forma que as línguas ocidentais.
Mesmo quando as línguas do Sul Global parecem estar representadas, a fonte e o dialeto da língua provêm principalmente de criadores norte-americanos ou europeus e de fontes da Web.

A anterior Experiência antrópica descobriram que a mudança de línguas em modelos como o ChatGPT continuava a produzir pontos de vista ocidentais e estereótipos nas conversas.
Os investigadores antrópicos concluíram que "se um modelo linguístico representar desproporcionadamente certas opiniões, corre o risco de impor efeitos potencialmente indesejáveis, como a promoção de visões do mundo hegemónicas e a homogeneização das perspectivas e crenças das pessoas".
O estudo Data Provenance também dissecou o panorama geográfico da curadoria de conjuntos de dados. As organizações académicas surgem como os principais impulsionadores, contribuindo para 69% dos conjuntos de dados, seguidas pelos laboratórios da indústria (21%) e pelas instituições de investigação (17%).
Nomeadamente, os maiores contribuidores são a AI2 (12,3%), a Universidade de Washington (8,9%) e a Facebook AI Research (8,4%).
A estudo separado 2020 salienta que metade dos conjuntos de dados utilizados para a avaliação da IA em cerca de 26 000 artigos de investigação teve origem em apenas 12 universidades e empresas de tecnologia de topo.
Mais uma vez, verificou-se que áreas geográficas como África, América do Sul e Central e Ásia Central estavam lamentavelmente sub-representadas, como se pode ver abaixo.
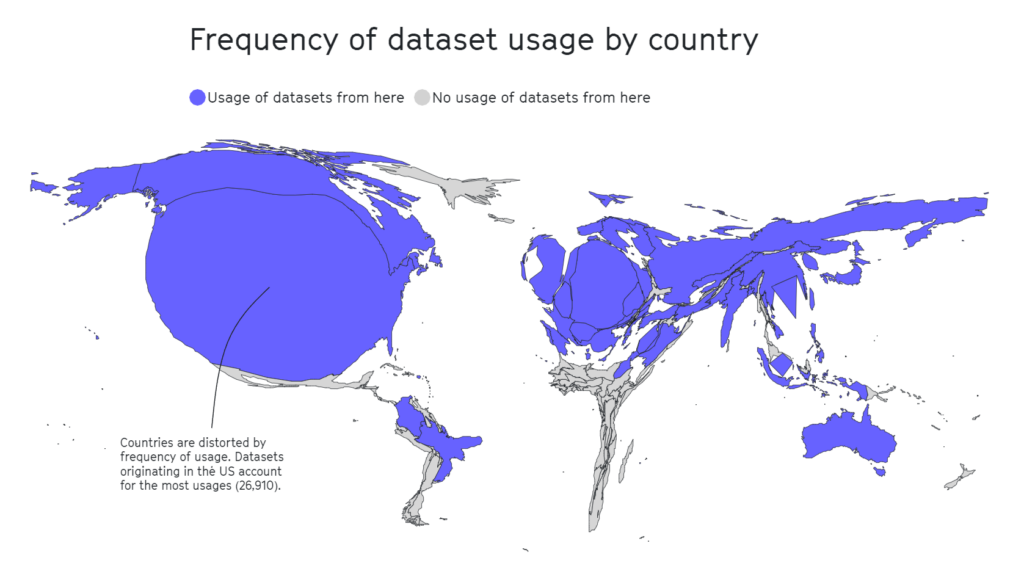
Noutros estudos, conjuntos de dados influentes como o Tiny Images do MIT ou o Labeled Faces in the Wild continham sobretudo imagens de homens ocidentais brancos, com cerca de 77,5% de homens e 83,5% de indivíduos de pele branca no caso do Labeled Faces in the Wild.
No caso da Tiny Images, um Análise de 2020 efectuada pelo The Register descobriu que muitas das Tiny Images continham rótulos obscenos, racistas e sexistas.
Antonio Torralba, do MIT, disse que não tinham conhecimento das etiquetas e que o conjunto de dados foi eliminado. Torralba disse: "É evidente que devíamos tê-los selecionado manualmente".
O inglês domina o ecossistema da IA
Pascale Fung, cientista informática e directora do Centro de Investigação em IA da Universidade de Ciência e Tecnologia de Hong Kong, discutiu os problemas associados à IA hegemónica.
Fung faz referência a mais de 15 trabalhos de investigação que investigaram a proficiência multilingue dos LLM e que constataram consistentemente a sua falta, particularmente quando traduzem inglês para outras línguas. Por exemplo, línguas com escrita não latina, como o coreano, expõem as limitações dos LLM.
Para além do fraco apoio multilingue, outros estudos sugerem que a maioria dos indicadores e medidas de preconceito foram desenvolvidos tendo em conta os modelos de língua inglesa.
As referências de enviesamento não inglês são poucas e distantes entre si, o que leva a uma lacuna significativa na nossa capacidade de avaliar e retificar o enviesamento em modelos linguísticos multilingues.
Há sinais de melhoria, como os esforços da Google com o seu modelo de linguagem PaLM 2 e Meta's Discurso massivamente multilingue (MMS) que consegue identificar mais de 4.000 línguas faladas, 40 vezes mais do que outras abordagens. No entanto, o MMS continua a ser experimental.
Os investigadores estão a criar conjuntos de dados diversificados e multilingues, mas a quantidade esmagadora de dados de texto em inglês, muitas vezes gratuitos e de fácil acesso, torna-os a escolha de facto para os programadores.
Para além dos dados: questões estruturais no trabalho de IA
A vasta análise do MIT sobre o colonialismo da IA chamou a atenção para um aspeto relativamente oculto do desenvolvimento da IA - as práticas de exploração laboral.
A IA desencadeou um aumento intenso da procura de serviços de etiquetagem de dados. Empresas como a Appen e a Sama surgiram como actores-chave, oferecendo serviços de etiquetagem de texto, imagens e vídeos, classificação de fotografias e transcrição de áudio para alimentar modelos de aprendizagem automática.
Os especialistas de dados humanos também rotulam manualmente os tipos de conteúdo, muitas vezes para classificar os dados que contêm conteúdos ilegais, ilícitos ou pouco éticos, tais como descrições de abuso sexual, comportamento nocivo ou outras actividades ilegais.
Embora as empresas de IA automatizem alguns destes processos, continua a ser vital manter os "humanos no circuito" para garantir a exatidão dos modelos e a conformidade com a segurança.
O valor de mercado deste "trabalho fantasma", como o designam a antropóloga Mary Gray e o cientista social Siddharth Suri, está projetado para disparar para $13,7 mil milhões até 2030.
O trabalho clandestino envolve muitas vezes a exploração de mão de obra barata, sobretudo de países economicamente vulneráveis. A Venezuela, por exemplo, tornou-se uma das principais fontes de mão de obra relacionada com a IA devido à sua crise económica.
Enquanto o país se debatia com a sua pior catástrofe económica em tempo de paz e com uma inflação astronómica, uma parte significativa da sua população instruída e ligada à Internet voltou-se para as plataformas de trabalho coletivo como meio de sobrevivência.
A confluência de uma mão de obra bem formada e do desespero económico fez da Venezuela um mercado atrativo para as empresas de etiquetagem de dados.
Este não é um ponto controverso - quando o MIT publica artigos com títulos como "A inteligência artificial está a criar uma nova ordem mundial colonialAo fazer referência a cenários como este, é evidente que alguns intervenientes na indústria pretendem fechar a cortina sobre estas práticas laborais desleais.
Como relata o MIT, para muitos venezuelanos, a florescente indústria da IA tem sido uma faca de dois gumes. Ao mesmo tempo que constituiu uma tábua de salvação económica no meio do desespero, também expôs as pessoas à exploração.
Julian Posada, candidato a doutoramento na Universidade de Toronto, salienta os "enormes desequilíbrios de poder" nestes regimes de trabalho. As plataformas ditam as regras, deixando os trabalhadores com pouca margem de manobra e com uma compensação financeira limitada, apesar dos desafios no local de trabalho, como a exposição a conteúdos perturbadores.
Esta dinâmica faz lembrar as práticas coloniais históricas, em que os impérios exploravam a mão de obra de países vulneráveis, extraindo lucros e abandonando-os assim que as oportunidades se esgotavam, muitas vezes porque havia "melhores preços" disponíveis noutros locais.
Foram observadas situações semelhantes em Nairobi, no Quénia, onde um grupo de antigos moderadores de conteúdos que trabalhavam no ChatGPT apresentou uma petição com o governo do Quénia.
Alegaram "condições de exploração" durante a sua permanência na Sama, uma empresa norte-americana de serviços de anotação de dados contratada pela OpenAI. Os peticionários alegaram que foram expostos a conteúdos perturbadores sem apoio psicossocial adequado, o que lhes provocou graves problemas de saúde mental, incluindo stress pós-traumático, depressão e ansiedade.

Documentos revisto por TIME indicou que a OpenAI tinha assinado contratos com a Sama no valor de cerca de $200.000. Estes contratos envolviam a rotulagem de descrições de abusos sexuais, discursos de ódio e violência.
O impacto na saúde mental dos trabalhadores foi profundo. Mophat Okinyi, um antigo moderador, falou do impacto psicológico, descrevendo como a exposição a conteúdos gráficos levou à paranoia, ao isolamento e a perdas pessoais significativas.
Os salários para um trabalho tão penoso eram chocantemente baixos - um porta-voz da Sama revelou que os trabalhadores ganhavam entre $1,46 e $3,74 por hora.
Resistir ao colonialismo digital
Se a indústria da IA se tornou uma nova fronteira do colonialismo digital, então a resistência já está a tornar-se mais coesa.
Os activistas, muitas vezes apoiados por investigadores de IA, defendem a responsabilização, a alteração de políticas e o desenvolvimento de tecnologias que dêem prioridade às necessidades e aos direitos das comunidades locais.
Nanjala Nyabola's Projeto de Direitos Digitais em Kiswahili constitui um exemplo inovador de como os projectos de base à escala local podem instalar a infraestrutura necessária para proteger as comunidades da hegemonia digital.
O projeto tem em conta a hegemonia das regulamentações ocidentais na definição dos direitos digitais de um grupo, uma vez que nem todos estão protegidos pelas leis de propriedade intelectual, direitos de autor e privacidade que muitos de nós tomamos como garantidas. Este facto deixa uma parte significativa da população mundial sujeita à exploração por parte das empresas tecnológicas.
Reconhecendo que as discussões em torno dos direitos digitais são enfraquecidas se as pessoas não puderem comunicar as questões nas suas línguas nativas, Nyabola e a sua equipa traduziram os principais direitos digitais e termos tecnológicos para a língua Kiswahili, falada principalmente na Tanzânia, Quénia e Moçambique.
Nyabola descrição do projeto"Durante esse processo [da iniciativa Huduma Namba], não dispúnhamos realmente da linguagem e das ferramentas para explicar às comunidades não especializadas ou que não falavam inglês no Quénia quais eram as implicações da iniciativa".
Num projeto de base semelhante, a Te Hiku Media, uma estação de rádio sem fins lucrativos que emite principalmente em língua maori, possuía uma vasta base de dados de gravações que abrangiam décadas, muitas das quais ecoavam as vozes de frases ancestrais que já não eram faladas.
Os principais modelos de reconhecimento de voz, semelhantes aos LLM, tendem a ter um desempenho inferior quando são solicitados em diferentes línguas ou dialectos do inglês.
O Te Hiku Media colaborou com investigadores e tecnologias de código aberto para treinar um modelo de reconhecimento de voz adaptado à língua maori. O ativista Māori Te Mihinga Komene contribuiu com cerca de 4.000 frases para inúmeros outros que participaram no projeto.
O modelo resultante e os dados são protegidos pelo Licença Kaitiakitanga - Kaitiakitanga é uma palavra Māori sem uma definição específica em inglês, mas é semelhante a "guardião" ou "custodiante".
Keoni Mahelona, cofundador da Te Hiku Media, comentou de forma pungente: "Os dados são a última fronteira da colonização".
Estes projectos inspiraram outras comunidades indígenas e nativas sob pressão do colonialismo digital e de outras formas de convulsão social, como os povos Mohawk na América do Norte e os nativos do Havai.
À medida que a IA de código aberto se torna mais barata e mais fácil de aceder, a iteração e o aperfeiçoamento de modelos utilizando conjuntos de dados únicos e localizados deverá tornar-se mais simples, melhorando o acesso transcultural à tecnologia.
Embora a indústria da IA continue a ser jovem, chegou o momento de trazer estes desafios para a ribalta, de modo a que as pessoas possam desenvolver coletivamente soluções.
As soluções podem ser tanto a nível macro, sob a forma de regulamentos, políticas e abordagens de formação em aprendizagem automática, como a nível micro, sob a forma de projectos locais e de base.
Juntos, investigadores, activistas e comunidades locais podem encontrar métodos para garantir que a IA beneficia todos.


