

À medida que a era da IA generativa avança, uma vasta gama de empresas juntou-se à luta e os próprios modelos tornaram-se cada vez mais diversificados.
No meio deste boom da IA, muitas empresas anunciaram os seus modelos como "open source", mas o que é que isso significa na prática?
O conceito de código aberto tem as suas raízes na comunidade de desenvolvimento de software. O software tradicional de código aberto disponibiliza livremente o código fonte para que qualquer pessoa o possa ver, modificar e distribuir.
Na sua essência, o código aberto é um dispositivo de partilha de conhecimentos colaborativo alimentado pela inovação de software, que conduziu a desenvolvimentos como o sistema operativo Linux, o browser Firefox e a linguagem de programação Python.
No entanto, a aplicação do princípio do código aberto aos actuais modelos de IA de grande dimensão está longe de ser simples.
Estes sistemas são frequentemente treinados em vastos conjuntos de dados que contêm terabytes ou petabytes de dados, utilizando arquitecturas de redes neuronais complexas com milhares de milhões de parâmetros.
Os recursos informáticos necessários custam milhões de dólares, os talentos são escassos e a propriedade intelectual é frequentemente bem guardada.
Podemos observar isto no OpenAI, que, como o seu nome sugere, costumava ser um laboratório de investigação em IA amplamente dedicado à ética da investigação aberta.
No entanto, essa ética rapidamente corroída quando a empresa sentiu o cheiro do dinheiro e precisou de atrair investimento para alimentar os seus objectivos.
Porquê? Porque os produtos de código aberto não estão orientados para o lucro e a IA é cara e valiosa.
No entanto, com a explosão da IA generativa, empresas como a Mistral, a Meta, a BLOOM e a xAI estão a lançar modelos de código aberto para promover a investigação, evitando que empresas como a Microsoft e a Google acumulem demasiada influência.
Mas quantos destes modelos são verdadeiramente de código aberto por natureza, e não apenas pelo nome?
Esclarecer até que ponto os modelos de código aberto são realmente abertos
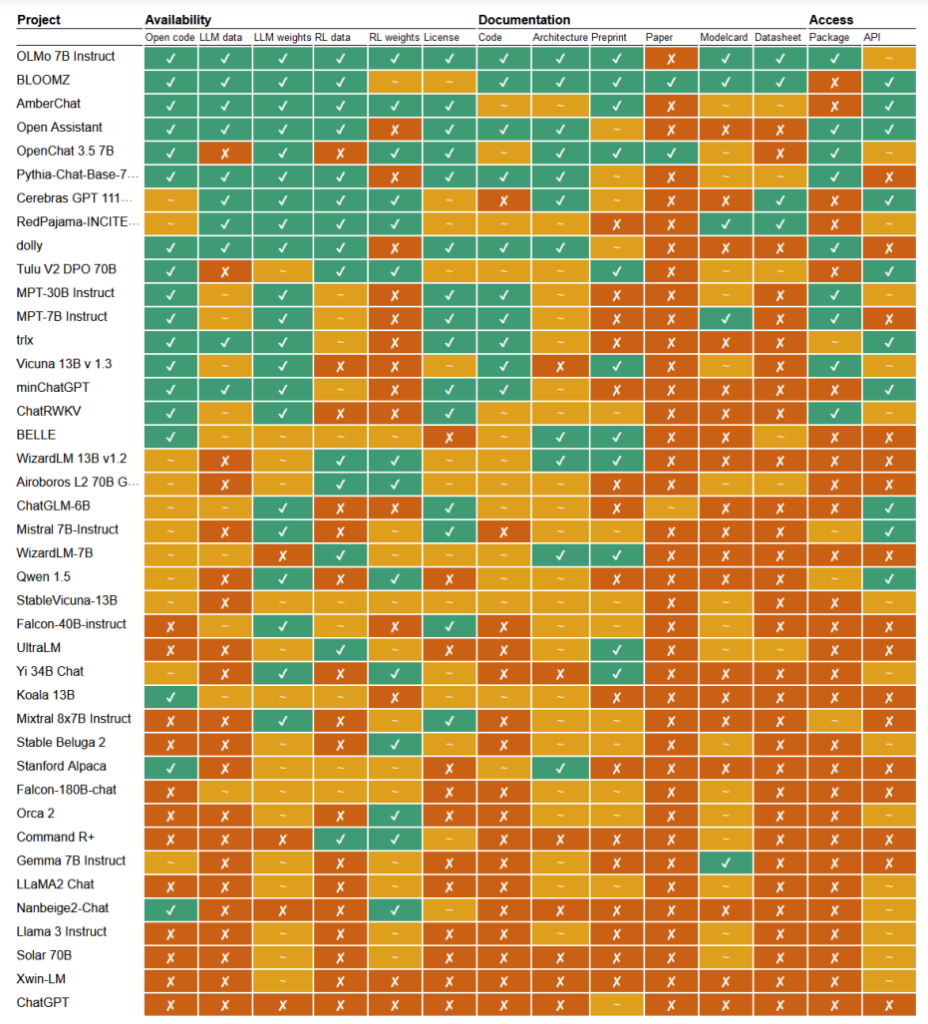
Num recente estudoNo âmbito do projeto de investigação "Aberto", os investigadores Mark Dingemanse e Andreas Liesenfeld da Universidade de Radboud, nos Países Baixos, analisaram vários modelos de IA proeminentes para explorar o seu grau de abertura. Estudaram vários critérios, como a disponibilidade do código-fonte, dados de treino, pesos do modelo, documentos de investigação e APIs.
Por exemplo, o modelo LLaMA da Meta e o Gemma da Google foram considerados simplesmente "peso aberto", o que significa que o modelo treinado é publicamente divulgado para utilização sem total transparência no seu código, processo de treino, dados e métodos de afinação.
No outro extremo do espetro, os investigadores destacaram o BLOOM, um grande modelo multilingue desenvolvido por uma colaboração de mais de 1000 investigadores de todo o mundo, como um exemplo de verdadeira IA de fonte aberta. Todos os elementos do modelo são de acesso livre para inspeção e investigação.
O documento avaliou mais de 30 modelos (tanto de texto como de imagem), mas estes demonstram a imensa variação entre os modelos que se dizem de fonte aberta:
- BloomZ (BigScience): Totalmente aberto em todos os critérios, incluindo código, dados de treino, pesos do modelo, documentos de investigação e API. Destacado como um exemplo de IA verdadeiramente de código aberto.
- OLMo (Allen Institute for AI): Código aberto, dados de treino, pesos e documentos de investigação. API apenas parcialmente aberta.
- Mistral 7B-Instruct (Mistral AI): Modelo aberto de pesos e API. Código e documentos de investigação apenas parcialmente abertos. Dados de treino indisponíveis.
- Orca 2 (Microsoft): Pesos de modelos e documentos de investigação parcialmente abertos. Código, dados de treino e API fechados.
- Instrução Gemma 7B (Google): Código e pesos parcialmente abertos. Dados de treino, documentos de investigação e API fechados. Descrito como "aberto" pelo Google em vez de "código aberto".
- Llama 3 Instruct (Meta): Pesos parcialmente abertos. Código, dados de treino, documentos de investigação e API fechados. Um exemplo de um modelo de "peso aberto" sem uma transparência total.
A falta de transparência
A falta de transparência em torno dos modelos de IA, especialmente os desenvolvidos por grandes empresas tecnológicas, suscita sérias preocupações quanto à responsabilidade e à supervisão.
Sem acesso total ao código do modelo, aos dados de treino e a outros componentes-chave, torna-se extremamente difícil compreender o funcionamento destes modelos e tomar decisões. Isto dificulta a identificação e a resolução de potenciais enviesamentos, erros ou utilização incorrecta de material protegido por direitos de autor.
A violação de direitos de autor em dados de treino de IA é um excelente exemplo dos problemas que surgem desta falta de transparência. Muitos modelos de IA proprietários, como o GPT-3.5/4/40/Claude 3/Gemini, são provavelmente treinados em material protegido por direitos de autor.
No entanto, uma vez que os dados de formação são guardados a sete chaves, é quase impossível identificar dados específicos dentro deste material.
O jornal The New York Times ação judicial recente contra a OpenAI demonstra as consequências deste desafio no mundo real. A OpenAI acusou o NYT de utilizar ataques de engenharia rápida para expor os dados de treino e persuadir o ChatGPT a reproduzir os seus artigos na íntegra, provando assim que os dados de treino da OpenAI contêm material protegido por direitos de autor.
"O Times pagou a alguém para piratear os produtos da OpenAI", afirmou a OpenAI.
Em resposta, Ian Crosby, o principal advogado do NYT, afirmou: "O que a OpenAI descaracteriza de forma bizarra como 'pirataria' é simplesmente a utilização dos produtos da OpenAI para procurar provas de que roubaram e reproduziram os trabalhos protegidos por direitos de autor do The Times. E foi exatamente isso que encontrámos".
De facto, este é apenas um exemplo de uma enorme pilha de processos judiciais que estão atualmente bloqueados, em parte devido à natureza opaca e impenetrável dos modelos de IA.
Esta é apenas a ponta do icebergue. Sem medidas sólidas de transparência e responsabilização, arriscamo-nos a um futuro em que sistemas de IA inexplicáveis tomam decisões que têm um impacto profundo nas nossas vidas, na economia e na sociedade, mas que permanecem protegidos do escrutínio.
Apelos à abertura
Foram lançados apelos para que empresas como a Google e a OpenAI conceder acesso ao funcionamento interno dos seus modelos para efeitos de avaliação da segurança.
No entanto, a verdade é que mesmo as empresas de IA não compreendem verdadeiramente como funcionam os seus modelos.
A isto chama-se o problema da "caixa negra", que surge quando se tenta interpretar e explicar as decisões específicas do modelo de uma forma compreensível para o ser humano.
Por exemplo, um programador pode saber que um modelo de aprendizagem profunda é preciso e tem um bom desempenho, mas pode ter dificuldade em identificar exatamente quais as características que o modelo utiliza para tomar as suas decisões.
A Anthropic, que desenvolveu os modelos Claude, recentemente realizou uma experiência para identificar o funcionamento do Soneto de Claude 3, explicando: "Na maior parte das vezes, tratamos os modelos de IA como uma caixa negra: algo entra e sai uma resposta, e não é claro porque é que o modelo deu essa resposta específica em vez de outra. Isto torna difícil confiar que estes modelos são seguros: se não sabemos como funcionam, como é que sabemos que não darão respostas prejudiciais, tendenciosas, falsas ou perigosas? Como podemos confiar que são seguros e fiáveis?"
Na verdade, é uma admissão bastante notável o facto de o criador de uma tecnologia não compreender o seu produto na era da IA.
Esta experiência antrópica ilustrou que explicar objetivamente os resultados é uma tarefa excecionalmente complicada. De facto, o Anthropic estimou que consumiria mais poder de computação para "abrir a caixa negra" do que para treinar o próprio modelo!
Os programadores estão a tentar combater ativamente o problema da caixa negra através de investigação como a "IA explicável" (XAI), que visa desenvolver técnicas e ferramentas para tornar os modelos de IA mais transparentes e interpretáveis.
Os métodos XAI procuram fornecer informações sobre o processo de tomada de decisões do modelo, destacar as características mais influentes e gerar explicações legíveis por humanos. Os métodos XAI já foram aplicados a modelos utilizados em concursos de alto risco aplicações como o desenvolvimento de medicamentos, em que a compreensão do funcionamento de um modelo pode ser fundamental para a segurança.
As iniciativas de código aberto são vitais para a XAI e para outras investigações que procuram penetrar na caixa negra e dar transparência aos modelos de IA.
Sem acesso ao código do modelo, aos dados de treino e a outros componentes essenciais, os investigadores não podem desenvolver e testar técnicas para explicar como funcionam verdadeiramente os sistemas de IA e identificar os dados específicos com que foram treinados.
Os regulamentos podem confundir ainda mais a situação do código aberto
A União Europeia Lei da IA recentemente aprovada vai introduzir novos regulamentos para os sistemas de IA, com disposições que abordam especificamente os modelos de código aberto.
Nos termos da lei, os modelos de utilização geral de fonte aberta até uma determinada dimensão ficarão isentos de requisitos de transparência extensivos.
No entanto, tal como Dingemanse e Liesenfeld referem no seu estudo, a definição exacta de "IA de fonte aberta" ao abrigo do AI Act ainda não é clara e pode tornar-se um ponto de discórdia.
Atualmente, a lei define modelos de fonte aberta como os que são lançados ao abrigo de uma licença "livre e aberta" que permite aos utilizadores modificar o modelo. No entanto, não especifica os requisitos relativos ao acesso aos dados de formação ou a outros componentes essenciais.
Esta ambiguidade deixa espaço para interpretações e para potenciais lobbies por parte de interesses empresariais. Os investigadores alertam para o facto de que o aperfeiçoamento da definição de fonte aberta no AI Act "irá provavelmente constituir um único ponto de pressão que será alvo de lobbies empresariais e de grandes empresas".
Existe o risco de que, sem critérios claros e sólidos sobre o que constitui uma IA verdadeiramente de fonte aberta, os regulamentos possam inadvertidamente criar lacunas ou incentivos para que as empresas se envolvam em "lavagem aberta" - alegando abertura para os benefícios legais e de relações públicas, mantendo, no entanto, aspectos importantes dos seus modelos como propriedade.
Além disso, a natureza global do desenvolvimento da IA significa que a existência de diferentes regulamentações entre jurisdições pode complicar ainda mais o cenário.
Se os principais produtores de IA, como os Estados Unidos e a China, adoptarem abordagens divergentes em matéria de requisitos de abertura e transparência, tal poderá conduzir a um ecossistema fragmentado em que o grau de abertura varia muito em função da origem de um modelo.
Os autores do estudo sublinham a necessidade de os reguladores colaborarem estreitamente com a comunidade científica e outras partes interessadas para garantir que quaisquer disposições de fonte aberta na legislação sobre IA se baseiam numa compreensão profunda da tecnologia e dos princípios de abertura.
Como concluem Dingemanse e Liesenfeld num debate com a NaturezaÉ justo dizer que o termo "fonte aberta" assumirá um peso jurídico sem precedentes nos países regidos pelo AI Act da UE".
A forma como isto se desenrolar na prática terá implicações importantes para a futura direção da investigação e implantação da IA.



