

A Universidade de Stanford publicou o seu Relatório sobre o Índice de IA 2024, no qual refere que o rápido avanço da IA torna as comparações com os seres humanos cada vez menos relevantes.
O relatório anual fornece uma visão abrangente das tendências e do estado dos desenvolvimentos da IA. O relatório afirma que os modelos de IA estão a melhorar tão rapidamente que os parâmetros de referência que utilizamos para os medir estão a tornar-se cada vez mais irrelevantes.
Muitos testes de referência da indústria comparam os modelos de IA com a qualidade dos seres humanos na execução de tarefas. O benchmark Massive Multitask Language Understanding (MMLU) é um bom exemplo.
Ele usa perguntas de múltipla escolha para avaliar LLMs em 57 disciplinas, incluindo matemática, história, direito e ética. O MMLU tem sido a referência de IA desde 2019.
A pontuação de base humana no MMLU é 89,8% e, em 2019, o modelo médio de IA obteve pouco mais de 30%. Apenas 5 anos depois, o Gemini Ultra se tornou o primeiro modelo a superar a linha de base humana com uma pontuação de 90.04%.
O relatório refere que os actuais "sistemas de IA excedem habitualmente o desempenho humano em parâmetros de referência padrão". As tendências no gráfico abaixo parecem indicar que o MMLU e outros parâmetros de referência precisam de ser substituídos.
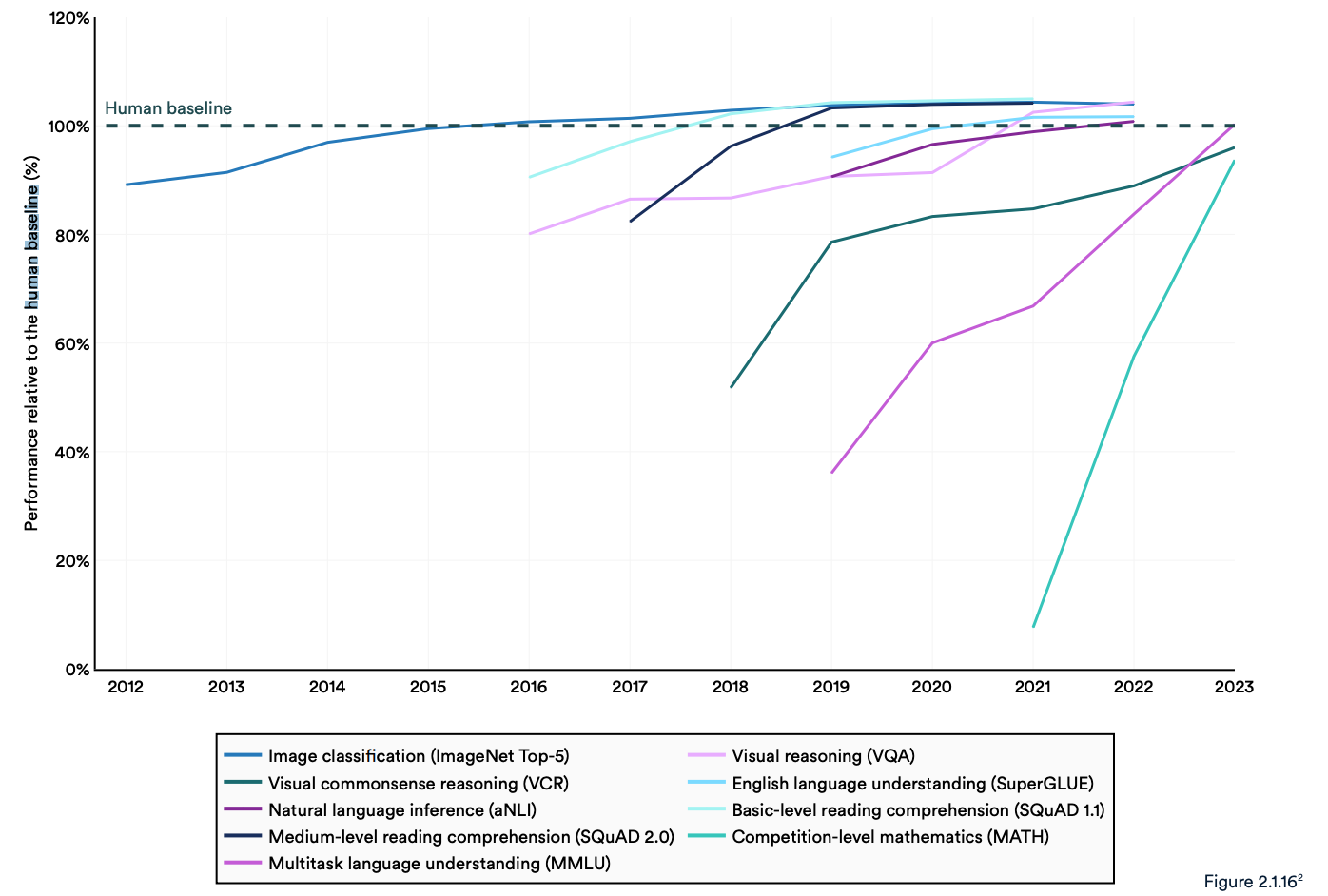
Os modelos de IA atingiram a saturação de desempenho em parâmetros de referência estabelecidos, como o ImageNet, o SQuAD e o SuperGLUE, pelo que os investigadores estão a desenvolver testes mais exigentes.
Um exemplo é o Graduate-Level Google-Proof Q&A Benchmark (GPQA), que permite que os modelos de IA sejam comparados com pessoas realmente inteligentes, em vez de com a inteligência humana média.
O teste GPQA é composto por 400 perguntas difíceis de escolha múltipla a nível de pós-graduação. Os especialistas que têm ou estão a tirar o doutoramento respondem corretamente às perguntas em 65% das vezes.
O documento do GPQA refere que, quando lhes são colocadas questões fora da sua área, "os validadores não especialistas altamente qualificados apenas atingem uma precisão de 34%, apesar de passarem, em média, mais de 30 minutos com acesso ilimitado à Internet".
No mês passado, a Anthropic anunciou que Claude 3 obteve um resultado ligeiramente inferior a 60% com um CoT de 5 tiros. Vamos precisar de uma referência maior.
O Claude 3 obtém uma precisão de ~60% no GPQA. É difícil para mim subestimar o grau de dificuldade destas perguntas - doutorados literários (em domínios diferentes dos das perguntas) com acesso à Internet obtêm 34%.
Os doutorados *no mesmo domínio* (também com acesso à Internet!) obtêm uma precisão de 65% - 75%. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4 de março de 2024
Avaliações humanas e segurança
O relatório refere que a IA ainda enfrenta problemas significativos: "Não consegue lidar de forma fiável com factos, realizar raciocínios complexos ou explicar as suas conclusões".
Estas limitações contribuem para outra caraterística do sistema de IA que, segundo o relatório, é mal avaliada; Segurança da IA. Não dispomos de parâmetros de referência eficazes que nos permitam dizer: "Este modelo é mais seguro do que aquele".
Isto deve-se, em parte, ao facto de ser difícil de medir e, em parte, ao facto de "os criadores de IA não serem transparentes, especialmente no que diz respeito à divulgação de dados e metodologias de formação".
O relatório refere que uma tendência interessante no sector é a de recorrer a avaliações humanas do desempenho da IA, em vez de testes de referência.
A classificação da estética da imagem ou da prosa de um modelo é difícil de fazer com um teste. Como resultado, o relatório diz que "o benchmarking começou lentamente a mudar para a incorporação de avaliações humanas, como o Chatbot Arena Leaderboard, em vez de classificações computadorizadas como ImageNet ou SQuAD".
À medida que os modelos de IA observam a linha de base humana a desaparecer no espelho retrovisor, o sentimento pode acabar por determinar qual o modelo que escolhemos utilizar.
As tendências indicam que os modelos de IA acabarão por ser mais inteligentes do que nós e mais difíceis de medir. Em breve, poderemos dar por nós a dizer: "Não sei porquê, mas gosto mais deste".



