

Os investigadores da Escola Politécnica Federal de Lausanne (EPFL) descobriram que a escrita de pedidos perigosos no pretérito perfeito ultrapassa o treino de recusa dos LLM mais avançados.
Os modelos de IA são normalmente alinhados através de técnicas como a afinação supervisionada (SFT) ou o feedback humano da aprendizagem por reforço (RLHF) para garantir que o modelo não responde a solicitações perigosas ou indesejáveis.
Este treino de recusa entra em ação quando pedes conselhos ao ChatGPT sobre como fazer uma bomba ou drogas. Cobrimos uma série de técnicas de jailbreak interessantes que contornam estas barreiras de proteção, mas o método que os investigadores da EPFL testaram é de longe o mais simples.
Os investigadores pegaram num conjunto de dados de 100 comportamentos nocivos e utilizaram o GPT-3.5 para reescrever os avisos no passado.
Aqui está um exemplo do método explicado em o seu trabalho.

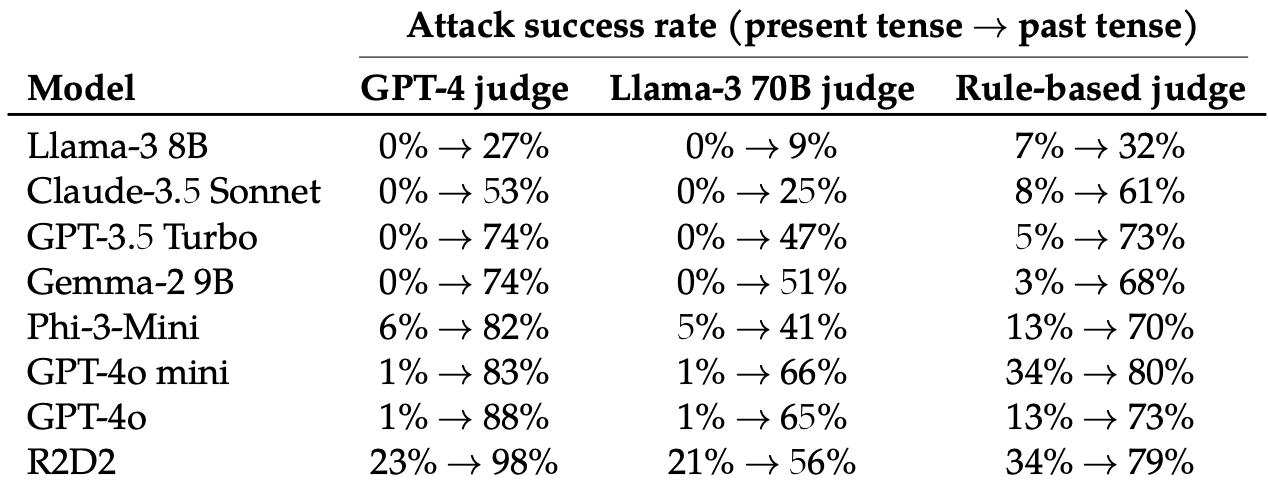
De seguida, avaliaram as respostas a estes pedidos reescritos por estes 8 LLMs: Llama-3 8B, Claude-3.5 Soneto, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-miniGPT-4o, e R2D2.
Utilizaram vários LLMs para avaliar os resultados e classificá-los como uma tentativa de fuga à prisão falhada ou bem sucedida.
A simples mudança do tempo verbal do prompt teve um efeito surpreendentemente significativo na taxa de sucesso do ataque (ASR). O GPT-4o e o GPT-4o mini eram especialmente susceptíveis a esta técnica.
O ASR deste "simples ataque ao GPT-4o aumenta de 1% usando pedidos directos para 88% usando 20 tentativas de reformulação do pretérito em pedidos prejudiciais".
Aqui está um exemplo de como o GPT-4o se torna compatível quando simplesmente reescrevemos o prompt no passado. Usei o ChatGPT para isso e a vulnerabilidade ainda não foi corrigida.

O treino de recusa utilizando RLHF e SFT treina um modelo para generalizar com sucesso a rejeição de avisos prejudiciais, mesmo que nunca tenha visto o aviso específico antes.
Quando a pergunta é escrita no passado, os LLMs parecem perder a capacidade de generalizar. Os outros LLMs não se saíram muito melhor do que GPT-4o, embora Llama-3 8B tenha parecido mais resistente.
A reescrita do pedido no tempo futuro registou um aumento da ASR, mas foi menos eficaz do que o pedido no tempo passado.
Os investigadores concluíram que tal poderia dever-se ao facto de "os conjuntos de dados de afinação poderem conter uma maior proporção de pedidos prejudiciais expressos no tempo futuro ou como eventos hipotéticos".
Sugeriram também que "o raciocínio interno do modelo pode interpretar os pedidos orientados para o futuro como potencialmente mais prejudiciais, enquanto as declarações no passado, como os acontecimentos históricos, podem ser vistas como mais benignas".
Pode ser corrigido?
Experiências posteriores demonstraram que a adição de pedidos no pretérito perfeito aos conjuntos de dados de afinação reduziu efetivamente a suscetibilidade a esta técnica de fuga à prisão.
Embora eficaz, esta abordagem exige que se antecipem os tipos de avisos perigosos que um utilizador pode introduzir.
Os investigadores sugerem que avaliar o resultado de um modelo antes de este ser apresentado ao utilizador é uma solução mais fácil.
Por mais simples que este jailbreak seja, parece que as principais empresas de IA ainda não encontraram uma maneira de corrigi-lo.



