

A Microsoft lançou o Phi-3 Mini, um modelo de linguagem minúsculo que faz parte da estratégia da empresa para desenvolver modelos de IA leves e com funções específicas.
A evolução dos modelos linguísticos tem-se caracterizado por parâmetros, conjuntos de dados de treino e janelas de contexto cada vez maiores. O aumento do tamanho destes modelos proporcionou capacidades mais poderosas, mas com um custo.
A abordagem tradicional para treinar um LLM consiste em fazê-lo consumir grandes quantidades de dados, o que exige enormes recursos informáticos. Estima-se que a formação de um LLM como o GPT-4, por exemplo, tenha levado cerca de 3 meses e custado mais de $21m.
O GPT-4 é uma óptima solução para tarefas que exigem um raciocínio complexo, mas é um exagero para tarefas mais simples, como a criação de conteúdos ou um chatbot de vendas. É como usar um canivete suíço quando tudo o que precisamos é de um simples abridor de cartas.
Com apenas 3,8B de parâmetros, o Phi-3 Mini é minúsculo. Ainda assim, a Microsoft afirma que é uma solução leve e económica ideal para tarefas como resumir um documento, extrair informações de relatórios e escrever descrições de produtos ou publicações em redes sociais.
Os valores de referência do MMLU mostram que o Phi-3 Mini e os modelos Phi maiores, ainda por lançar, batem modelos maiores como Mistral 7B e Gemma 7B.
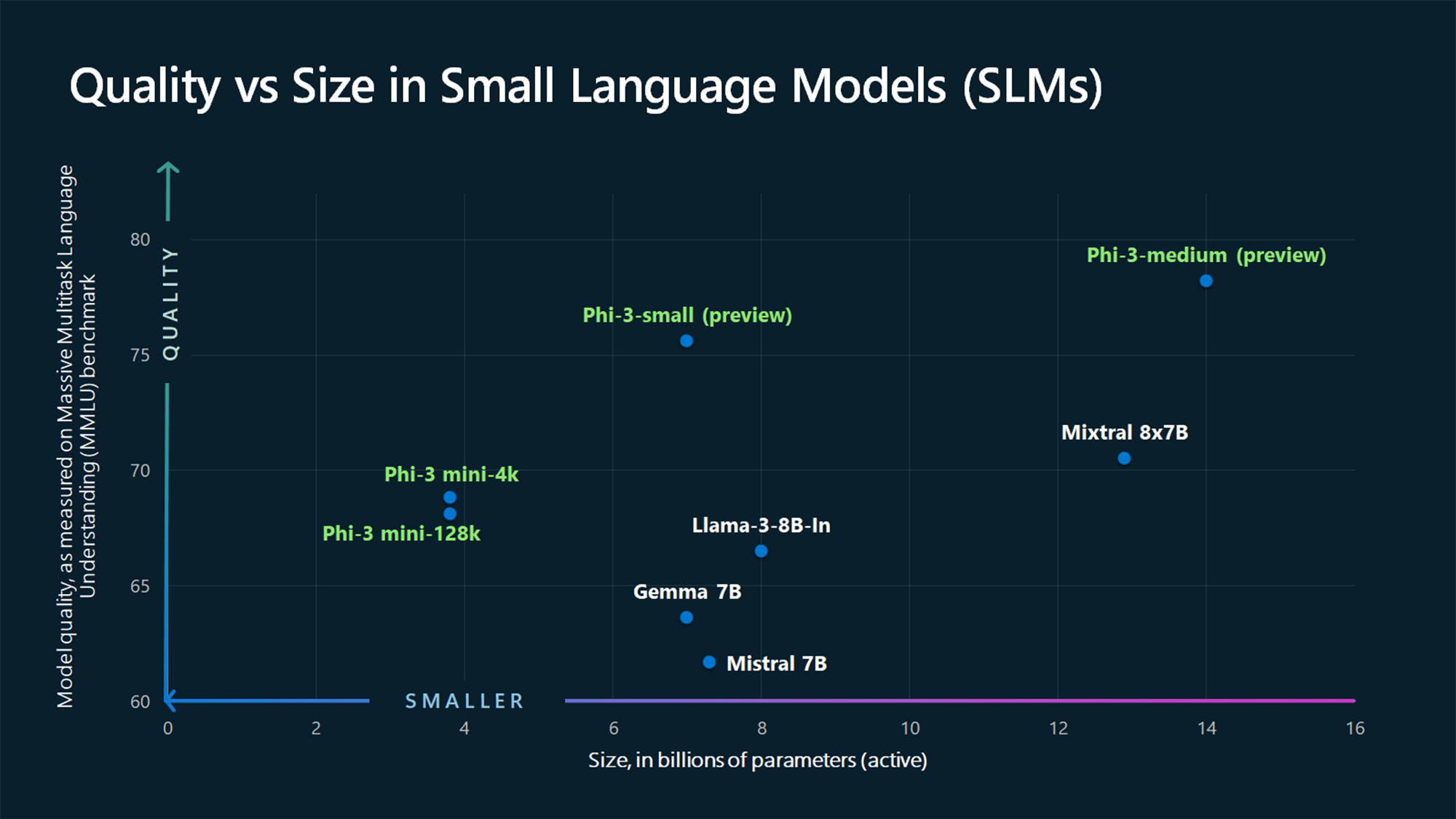
A Microsoft afirma que o Phi-3-small (parâmetros 7B) e o Phi-3-medium (parâmetros 14B) estarão disponíveis no Catálogo de Modelos de IA do Azure "em breve".
Os modelos maiores, como o GPT-4, continuam a ser o padrão de ouro e podemos provavelmente esperar que o GPT-5 seja ainda maior.
Os SLMs como o Phi-3 Mini oferecem algumas vantagens importantes que os modelos maiores não oferecem. Os SLMs são mais baratos de ajustar, requerem menos computação e podem ser executados no dispositivo mesmo em situações em que não há acesso à Internet.
A implantação de um SLM na borda resulta em menor latência e máxima privacidade, pois não há necessidade de enviar dados para frente e para trás para a nuvem.
Aqui está Sebastien Bubeck, vice-presidente de investigação GenAI na Microsoft AI com uma demonstração do Phi-3 Mini. É super rápido e impressionante para um modelo tão pequeno.
O phi-3 está aqui e é ... bom :-).
Fiz uma pequena demonstração para vos dar uma ideia do que o phi-3-mini (3.8B) pode fazer. Fique atento ao lançamento do open weights e a mais anúncios amanhã de manhã!
(E claro que isto não estaria completo sem a habitual tabela de benchmarks!) pic.twitter.com/AWA7Km59rp
- Sebastien Bubeck (@SebastienBubeck) 23 de abril de 2024
Dados sintéticos seleccionados
O Phi-3 Mini é o resultado do abandono da ideia de que grandes quantidades de dados são a única forma de treinar um modelo.
Sebastien Bubeck, vice-presidente de investigação de IA generativa da Microsoft, perguntou: "Em vez de treinar apenas com dados brutos da Web, porque não procurar dados de qualidade extremamente elevada?"
Ronen Eldan, especialista em aprendizagem automática da Microsoft Research, estava a ler histórias de embalar para a sua filha quando se perguntou se um modelo de linguagem poderia aprender utilizando apenas palavras que uma criança de 4 anos pudesse compreender.
Isto levou a uma experiência em que criaram um conjunto de dados a partir de 3.000 palavras. Utilizando apenas este vocabulário limitado, levaram um LLM a criar milhões de pequenas histórias infantis que foram compiladas num conjunto de dados chamado TinyStories.
Os investigadores utilizaram então o TinyStories para treinar um modelo extremamente pequeno, com 10 milhões de parâmetros, que foi subsequentemente capaz de gerar "narrativas fluentes com uma gramática perfeita".
Continuaram a iterar e a escalar esta abordagem de geração de dados sintéticos para criar conjuntos de dados sintéticos mais avançados, mas cuidadosamente seleccionados e filtrados, que acabaram por ser utilizados para treinar o Phi-3 Mini.
O resultado é um modelo minúsculo que será mais económico e que oferece um desempenho comparável ao GPT-3.5.
Os modelos mais pequenos, mas mais capazes, farão com que as empresas deixem de optar por LLMs de grandes dimensões, como o GPT-4. Em breve, também poderemos ver soluções em que um LLM trata do trabalho pesado, mas delega tarefas mais simples a modelos mais leves.



