

A Google lançou dois modelos da sua família de modelos leves e abertos denominada Gemma.
Enquanto os modelos Gemini da Google são proprietários, ou modelos fechados, os modelos Gemma foram lançados como "modelos abertos" e disponibilizados gratuitamente aos programadores.
A Google lançou modelos Gemma em dois tamanhos, parâmetros 2B e 7B, com variantes pré-treinadas e ajustadas por instruções para cada um. A Google está a lançar os pesos dos modelos, bem como um conjunto de ferramentas para os programadores adaptarem os modelos às suas necessidades.
A Google afirma que os modelos Gemma foram construídos utilizando a mesma tecnologia que equipa o seu modelo Gemini. Várias empresas lançaram modelos 7B num esforço para fornecer um LLM que mantenha a funcionalidade utilizável e que possa ser executado localmente em vez de na nuvem.
Llama-2-7B e Mistral-7B são concorrentes notáveis neste espaço, mas a Google afirma que "o Gemma supera modelos significativamente maiores nos principais parâmetros de referência" e apresentou esta comparação de parâmetros de referência como prova.
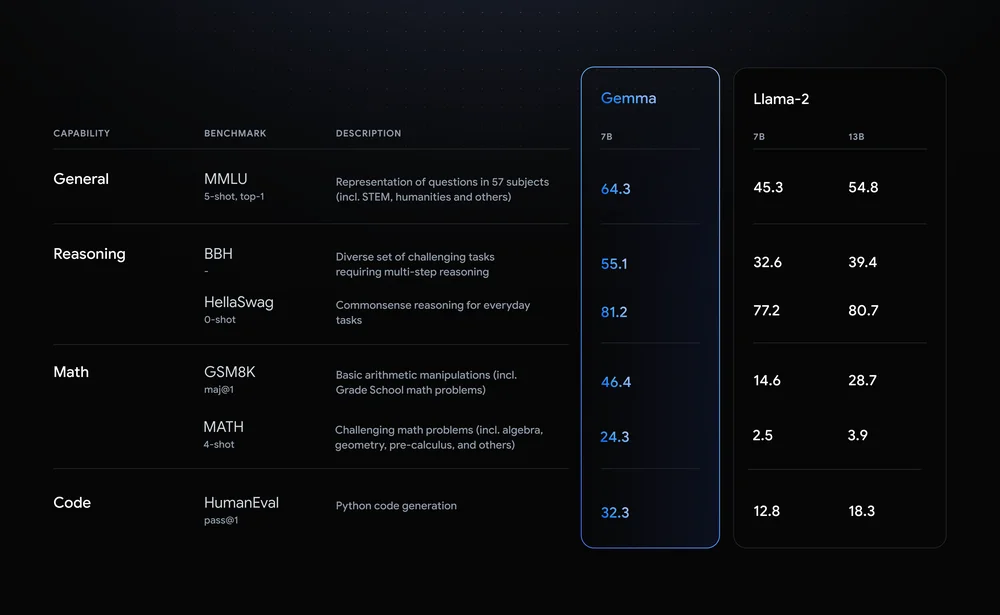
Os resultados do benchmark mostram que o Gemma bate até mesmo a versão maior de 12B do Llama 2 em todas as quatro capacidades.
O que é realmente excitante no Gemma é a perspetiva de o executar localmente. A Google estabeleceu uma parceria com a NVIDIA para otimizar o Gemma para as GPUs NVIDIA. Se tiver um PC com uma das GPUs RTX da NVIDIA, pode executar o Gemma no seu dispositivo.
A NVIDIA afirma ter uma base instalada de mais de 100 milhões de GPUs NVIDIA RTX. Isto torna a Gemma uma opção atractiva para os programadores que estão a tentar decidir qual o modelo leve a utilizar como base para os seus produtos.
A NVIDIA também irá adicionar suporte para o Gemma nas suas Conversar com RTX facilitando a execução de LLMs em PCs RTX.
Embora não seja tecnicamente de código aberto, são apenas as restrições de utilização no contrato de licença que impedem que os modelos Gemma possuam esse rótulo. Críticos dos modelos abertos apontam para os riscos inerentes ao facto de os manter alinhados, mas a Google afirma que efectuou um trabalho de equipa extensivo para garantir que Gemma estava segura.
A Google afirma que utilizou "uma extensa afinação e aprendizagem por reforço a partir de feedback humano (RLHF) para alinhar os nossos modelos afinados com instruções com comportamentos responsáveis". Também lançou um kit de ferramentas de IA generativa responsável para ajudar os programadores a manter o Gemma alinhado após o ajuste fino.
Modelos leves e personalizáveis como o Gemma podem oferecer aos programadores mais utilidade do que modelos maiores como o GPT-4 ou o Gemini Pro. A capacidade de executar LLMs localmente sem o custo de computação em nuvem ou chamadas de API está se tornando mais acessível a cada dia.
Com o Gemma abertamente disponível para os programadores, será interessante ver a gama de aplicações alimentadas por IA que poderão em breve ser executadas nos nossos PCs.



