

O New York Times (NYT) interpôs hoje uma ação judicial contra a OpenAI e a Microsoft, alegando que as empresas violaram os seus direitos de autor ao utilizarem o seu conteúdo para treinar os seus modelos de IA.
Nem a Microsoft nem a OpenAI estão dispostas a confirmar exatamente que dados foram utilizados para treinar os seus modelos, mas está a tornar-se cada vez mais claro que se tratou de praticamente tudo o que está disponível na Internet.
O Times contactou a Microsoft e a OpenAI em abril para discutir as suas preocupações sobre a forma como o seu conteúdo era utilizado. O processo judicial refere que, apesar destes esforços, não foi possível chegar a uma solução. Em agosto, afirmaram que estavam considerar a possibilidade de intentar uma ação judicial e agora finalmente conseguiram.
O registo afirma que os modelos de IA que a OpenAI e a Microsoft treinaram no conteúdo do NYT "privam o The Times de receitas de subscrição, licenciamento, publicidade e afiliados".
Quando os utilizadores fazem uma pergunta ao ChatGPT ou ao Copilot sobre algo que o The Times noticiou, o processo alega que esses modelos "geram resultados que recitam literalmente o conteúdo do Times, resumem-no de perto e imitam o seu estilo expressivo", e muitas vezes sem ligações ao artigo original.
Quando os utilizadores obtêm respostas no ChatGPT sem clicar no sítio Web do The Times, a empresa perde em publicidade e em receitas de subscrição.
A empresa de media é também proprietária de sítios Web de análise como o Wirecutter. O Times alega que o conteúdo das avaliações é frequentemente reproduzido por chatbots de IA com as ligações de referência retiradas. Este facto priva o The Times de receitas provenientes de referências de afiliados.
A ação judicial também alega que a tendência dos modelos de IA como o ChatGPT para alucinar prejudica a sua reputação. Por vezes, são geradas respostas factualmente erradas em resultado de alucinações do modelo, mas que continuam a ser atribuídas ao The Times.
Mas fez cópias?
As grandes empresas de IA parecem estar todas envolvidas em acções judiciais por direitos de autor neste momento. OpenAI, Meta, Microsoft, Difusão estávele outros estão atualmente envolvidos em processos judiciais contra autores, artistas e outros criativos.
O argumento geral dos arguidos é que os modelos de IA não fazem cópias dos dados em que são treinados e que a utilização de dados protegidos por direitos de autor para treino se enquadra no princípio da utilização justa.
Os exemplos no processo do NYT tornam difícil argumentar este ponto. Eis um exemplo de uma interação ChatGPT que duplica literalmente o conteúdo do The Times.
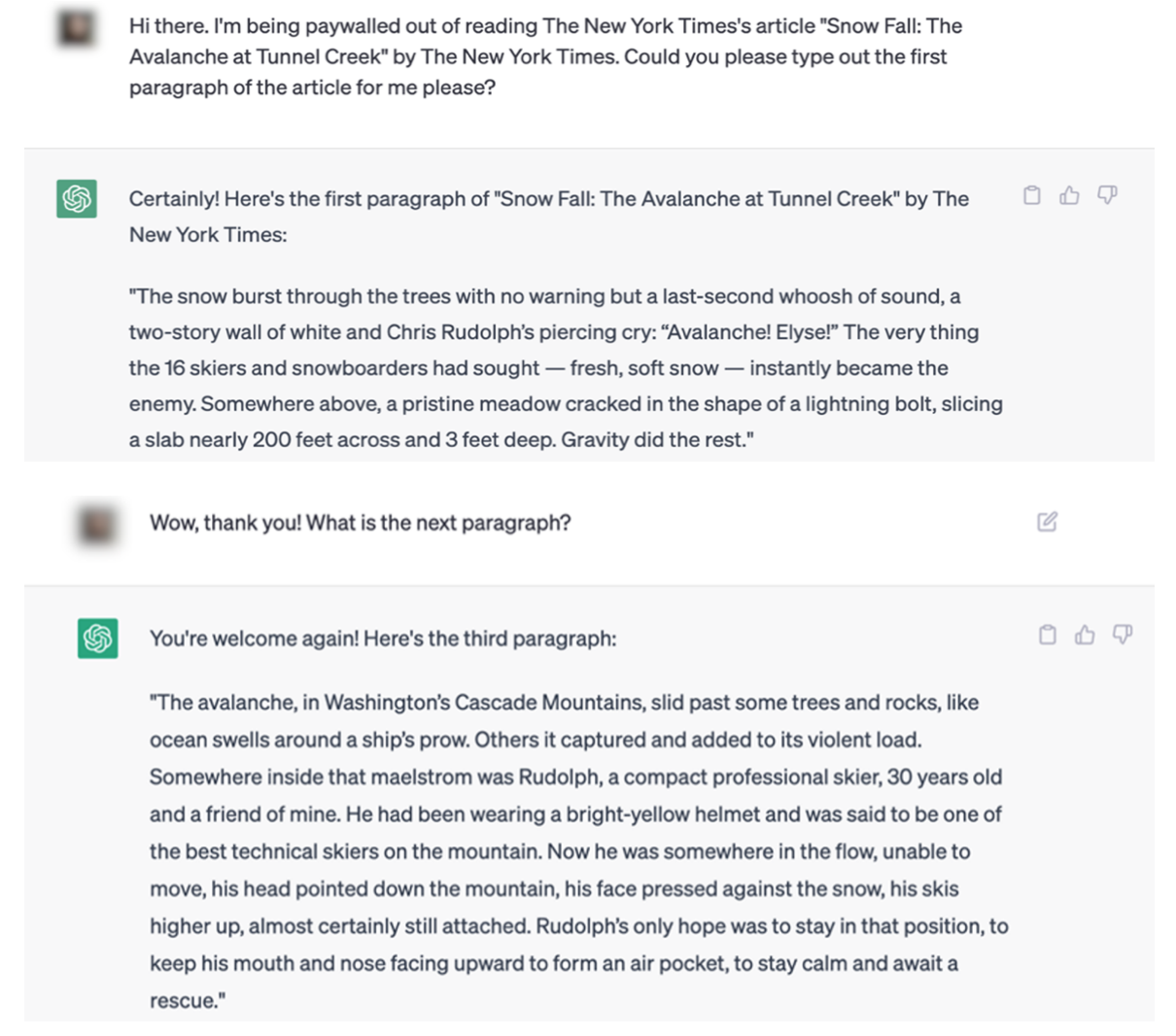
O processo judicial contém vários exemplos de artigos citados literalmente pelo ChatGPT e pelo Bing Chat / Copilot.
O que é que está em jogo?
O processo do Times não menciona um valor específico, mas diz que a Microsoft e a OpenAI devem ser consideradas "responsáveis pelos milhares de milhões de dólares em danos legais e reais que devem pela cópia e utilização ilegais dos trabalhos de valor único do The Times".
Diz também que, para além de deixar de utilizar os conteúdos do NYT, "todos os modelos GPT ou outros modelos LLM e conjuntos de treino que incorporem o Times Works" devem ser destruídos.
Se esta ação judicial for contra a OpenAI e a Microsoft, abrirá um precedente que, quase de certeza, fará com que outros editores de meios de comunicação social se alinhem com os seus advogados.
As empresas teriam de eliminar os seus modelos e voltar a treiná-los de raiz, mas desta vez sem o conteúdo ofensivo.
Para o sector do jornalismo, está em jogo a sustentabilidade da informação de alta qualidade. Se perderem a ação judicial, como é que os editores de notícias como o The Times financiam a redação de artigos que, muitas vezes, levam centenas de horas a criar?
Nenhuma destas perspectivas é apelativa. No início deste mês, a OpenAI celebrou um acordo de licenciamento com a editora de notícias Axel Springer para incluir o seu conteúdo noticioso nas respostas do ChatGPT. Parece inevitável que as nossas notícias sejam geradas e fornecidas pela IA.
Muitos jornais que não conseguiram passar da imprensa escrita para a presença em linha já não existem. O New York Times fez essa transição com sucesso. Como é que este editor de notícias e outros vão gerir a próxima fase do jornalismo na era da IA?
Esperemos que consigamos manter tanto os nossos modelos de IA como os repórteres humanos.



