

Het Technology Innovation Institute (TII) van de Verenigde Arabische Emiraten heeft vorige week zijn Falcon 180B LLM op Hugging Face losgelaten en deze leverde indrukwekkende prestaties tijdens de eerste tests.
Het model, dat vrij toegankelijk is voor onderzoekers en commerciële gebruikers, is het product van een ontluikende AI-industrie in het Midden-Oosten.
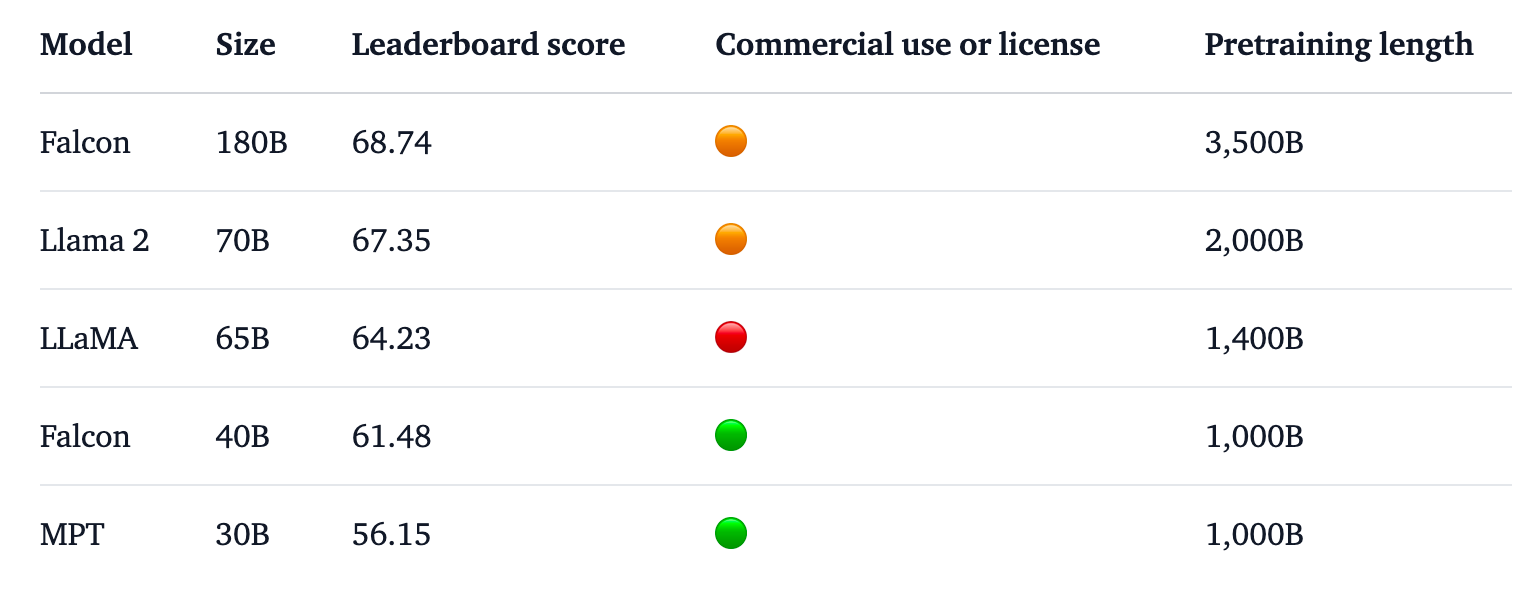
Falcon 180B is 2,5 keer groter dan Meta's Lama 2 en werd getraind met 4 keer meer rekenkracht. De TII trainde het model op een enorme 3,5 biljoen tokens. Het is de unieke benadering van de dataset die grotendeels verantwoordelijk is voor de indrukwekkende prestaties van het model.
Om een model te trainen heb je niet alleen veel gegevens nodig, maar ook veel gecureerde gegevens van goede kwaliteit. Dat kost veel geld om te produceren en er zijn niet veel echt grote gecureerde datasets die openbaar beschikbaar zijn. TII besloot een nieuwe aanpak te proberen om de noodzaak van curatie te vermijden.
In juni gebruikten onderzoekers zorgvuldige filtering en ontdubbeling van openbaar beschikbare CommonCrawl-gegevens om de RefinedWeb dataset te maken. Deze dataset was niet alleen eenvoudiger te produceren, maar levert ook betere prestaties dan wanneer alleen gecureerde corpora of webgegevens worden gebruikt.
Falcon 180B werd getraind op een enorme 3,5 biljoen tokens van de RefinedWeb dataset, aanzienlijk meer dan de 2 biljoen tokens van Llama 2's pre-training dataset.
Prestaties Falcon 180B
Falcon 180B staat bovenaan de Hugging Face ranglijst voor open access LLM's. Het model presteert beter dan Llama 2, de vorige leider, op een aantal benchmarks waaronder redeneren, coderen, vaardigheid en kennistests.
Falcon 180B scoort zelfs hoog in vergelijking met closed source, propriëtaire modellen. Hij staat net achter GPT-4 en op gelijke hoogte met Google's PaLM 2 Large, die twee keer zo groot is als Falcon 180B.
Bron: Knuffelend Gezicht
De TII zegt dat ondanks de al indrukwekkende prestaties met het voorgetrainde model, het van plan is om "in de toekomst steeds geschiktere versies van Falcon te leveren, gebaseerd op verbeterde datasets en RLHF/RLAIF".
Je kunt een chatversie van het model uitproberen met dit Demonstratie Falcon 180B op Knuffelgezicht.
De chatversie is verfijnd en gezuiverd, maar het basismodel heeft nog geen uitlijningsrails. De TII zei dat het "problematische" antwoorden kon geven omdat het nog niet door een fijnafstemmings- of afstemmingsproces was gegaan.
Het zal wat tijd kosten om het op het punt te krijgen waarop het met vertrouwen commercieel kan worden ingezet.
Desondanks laten de indrukwekkende prestaties van dit model zien dat er meer mogelijkheden voor verbetering zijn dan alleen het schalen van computermiddelen.
Falcon 180B laat zien dat kleinere modellen getraind op datasets van goede kwaliteit een meer kosteneffectieve en efficiënte richting kunnen zijn voor AI-ontwikkeling.
De release van dit indrukwekkende model onderstreept de razendsnelle groei in AI-ontwikkeling in het Midden-Oostenondanks recente exportbeperkingen van GPU's naar de regio.
Nu TII en Meta hun krachtige modellen onder open access licenties blijven uitbrengen, zal het interessant zijn om te zien wat Google en OpenAI doen om de adoptie van hun gesloten modellen te stimuleren.
De prestatiekloof tussen open access en propriëtaire modellen lijkt zeker kleiner te worden.



