

OpenAI heeft geen nieuwe modellen uitgebracht op zijn Dev Day-evenement, maar nieuwe API-functies zullen ontwikkelaars enthousiast maken die hun modellen willen gebruiken om krachtige apps te bouwen.
OpenAI heeft een paar zware weken achter de rug met zijn CTO, Mira Murati, en andere hoofdonderzoekers die zich bij de steeds langer wordende lijst van voormalige werknemers hebben gevoegd. Het bedrijf staat onder toenemende druk van andere paradepaardjes, waaronder open-source modellen die ontwikkelaars goedkopere en zeer capabele opties bieden.
De nieuwe functies die OpenAI onthulde waren de Realtime API (in bèta), vision fine-tuning en efficiëntieverhogende tools zoals prompt caching en model distillation.
Realtime API
De Realtime API is de meest opwindende nieuwe functie, zij het in bèta. Hiermee kunnen ontwikkelaars spraak-naar-spraak-ervaringen met lage latentie bouwen in hun apps zonder aparte modellen te gebruiken voor spraakherkenning en tekst-naar-spraak conversie.
Met deze API kunnen ontwikkelaars nu apps maken die realtime conversaties met AI mogelijk maken, zoals spraakassistenten of tools voor het leren van talen, allemaal via één enkele API-aanroep. Het is niet helemaal de naadloze ervaring die GPT-4o's Advanced Voice Mode biedt, maar het komt in de buurt.
Het is echter niet goedkoop, met ongeveer $0,06 per minuut audio-invoer en $0,24 per minuut audio-uitvoer.
De nieuwe Realtime API van OpenAI is ongelooflijk...
Kijk hoe het 400 aardbeien bestelt door te bellen naar de winkel met twillio. Allemaal met stem. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1 oktober 2024
Visie fijnafstemming
Met vision fine-tuning binnen de API kunnen ontwikkelaars het vermogen van hun modellen om afbeeldingen te begrijpen en ermee te interageren verbeteren. Door GPT-4o te verfijnen met behulp van afbeeldingen kunnen ontwikkelaars toepassingen maken die uitblinken in taken zoals visueel zoeken of objectdetectie.
Deze functie wordt al gebruikt door bedrijven als Grab, dat de nauwkeurigheid van zijn kaartendienst heeft verbeterd door het model te verfijnen om verkeersborden te herkennen uit beelden op straatniveau.
OpenAI gaf ook een voorbeeld van hoe GPT-4o extra inhoud voor een website kon genereren nadat het was afgestemd om stilistisch overeen te komen met de bestaande inhoud van de site.
Prompt cachen
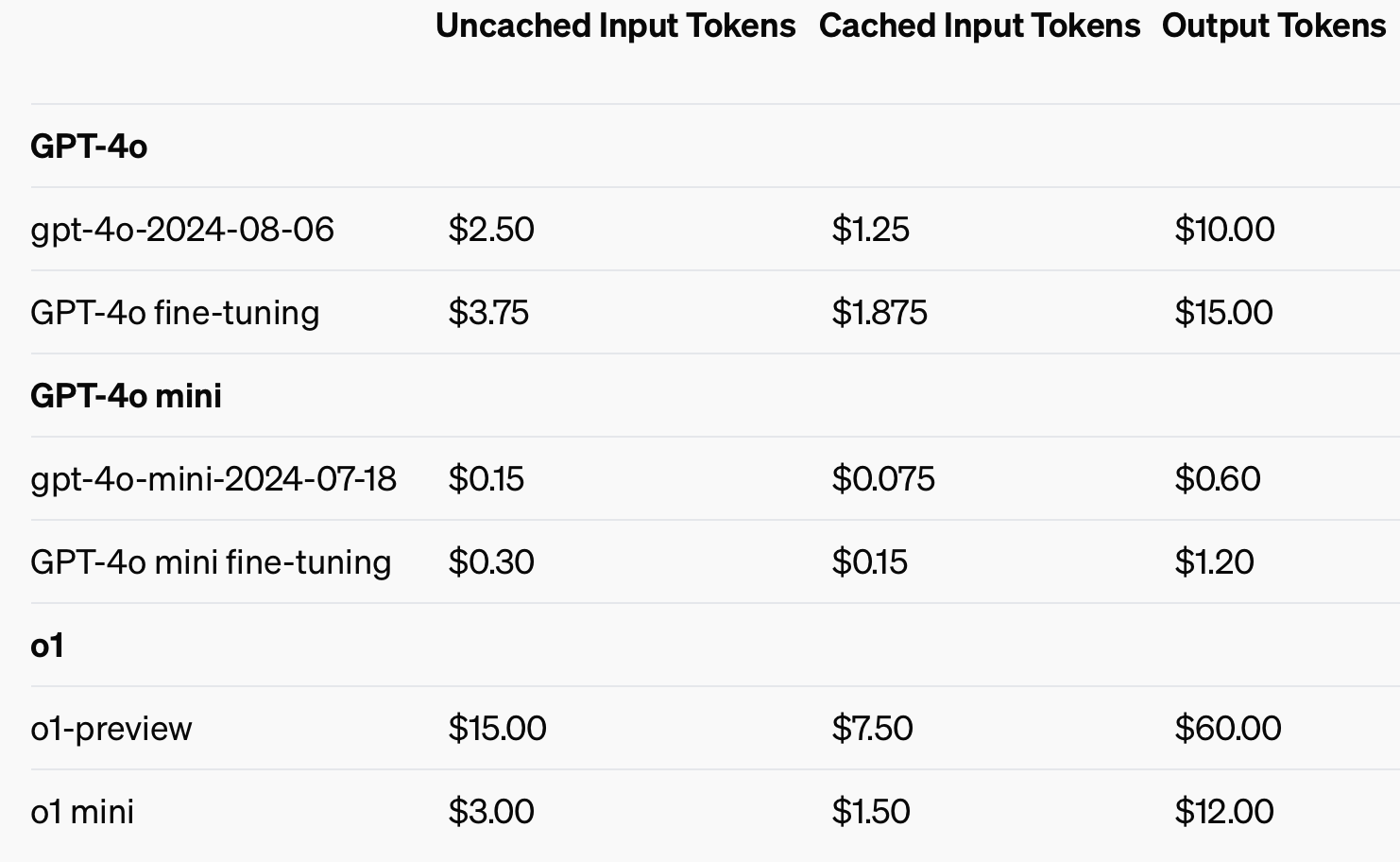
Om de kostenefficiëntie te verbeteren heeft OpenAI prompt caching geïntroduceerd, een tool die de kosten en latentie van veelgebruikte API-aanroepen verlaagt. Door recent verwerkte invoer opnieuw te gebruiken, kunnen ontwikkelaars de kosten met 50% verlagen en de responstijden verkorten. Deze functie is vooral handig voor toepassingen die lange conversaties of herhaalde context vereisen, zoals chatbots en klantenservice tools.
Door inputs in de cache te gebruiken, kan tot 50% worden bespaard op de kosten van invoertokens.
Model destillatie
Model distillatie stelt ontwikkelaars in staat om kleinere, meer kostenefficiënte modellen te verfijnen met behulp van de output van grotere, meer capabele modellen. Dit is een game-changer omdat distillatie voorheen meerdere losgekoppelde stappen en tools vereiste, waardoor het een tijdrovend en foutgevoelig proces werd.
Vóór de geïntegreerde Model Distillation functie van OpenAI moesten ontwikkelaars verschillende onderdelen van het proces handmatig orkestreren, zoals het genereren van gegevens van grotere modellen, het voorbereiden van datasets voor fijnafstemming en het meten van prestaties met verschillende tools.
Ontwikkelaars kunnen nu automatisch uitvoerparen opslaan van grotere modellen zoals GPT-4o en deze paren gebruiken om kleinere modellen zoals GPT-4o-mini te verfijnen. Het hele proces van datasets maken, fine-tunen en evalueren kan nu op een meer gestructureerde, geautomatiseerde en efficiënte manier.
Het gestroomlijnde ontwikkelaarsproces, de lagere latentie en de lagere kosten maken het GPT-4o model van OpenAI aantrekkelijk voor ontwikkelaars die snel krachtige apps willen implementeren. Het zal interessant zijn om te zien welke toepassingen de multimodale functies mogelijk maken.



