

HyperWrite-oprichter en CEO Matt Shumer kondigde aan dat zijn nieuwe model, Reflection 70B, een eenvoudige truc gebruikt om LLM-hallucinaties op te lossen en indrukwekkende benchmarkresultaten levert die grotere en zelfs gesloten modellen zoals GPT-4o verslaan.
Shumer werkte samen met de leverancier van synthetische gegevens, Glaive, om het nieuwe model te creëren dat is gebaseerd op Meta's Llama 3.1-70B Instruct-model.
In de aankondiging van de lancering op Hugging Face zei Shumer. "Reflection Llama-3.1 70B is (momenteel) 's werelds beste open-source LLM, getraind met een nieuwe techniek genaamd Reflection-Tuning die een LLM leert om fouten in zijn redenering op te sporen en koers te corrigeren."
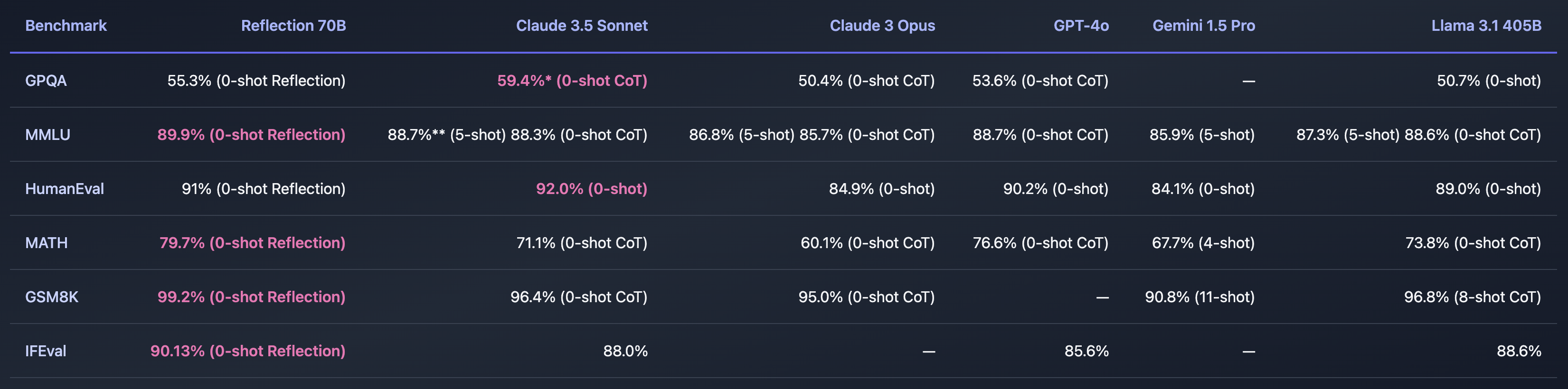
Als Shumer een manier heeft gevonden om het probleem van AI-hallucinaties op te lossen, zou dat ongelooflijk zijn. De benchmarks die hij deelde lijken aan te geven dat Reflection 70B ver voor ligt op andere modellen.
De naam van het model verwijst naar het vermogen om zichzelf te corrigeren tijdens de inferentie. Shumer verklapt niet te veel, maar legt uit dat het model nadenkt over zijn initiële antwoord op een prompt en dit pas uitvoert als het ervan overtuigd is dat het correct is.
Shumer zegt dat een 405B-versie van Reflection in de maak is en andere modellen, waaronder GPT-4o, zal wegblazen wanneer deze volgende week wordt onthuld.
Is Reflection 70B oplichterij?
Is dit allemaal te mooi om waar te zijn? Reflection 70B is beschikbaar voor download op Huging Face, maar vroege testers waren niet in staat om de indrukwekkende prestaties die Shumer's benchmarks lieten zien te evenaren.
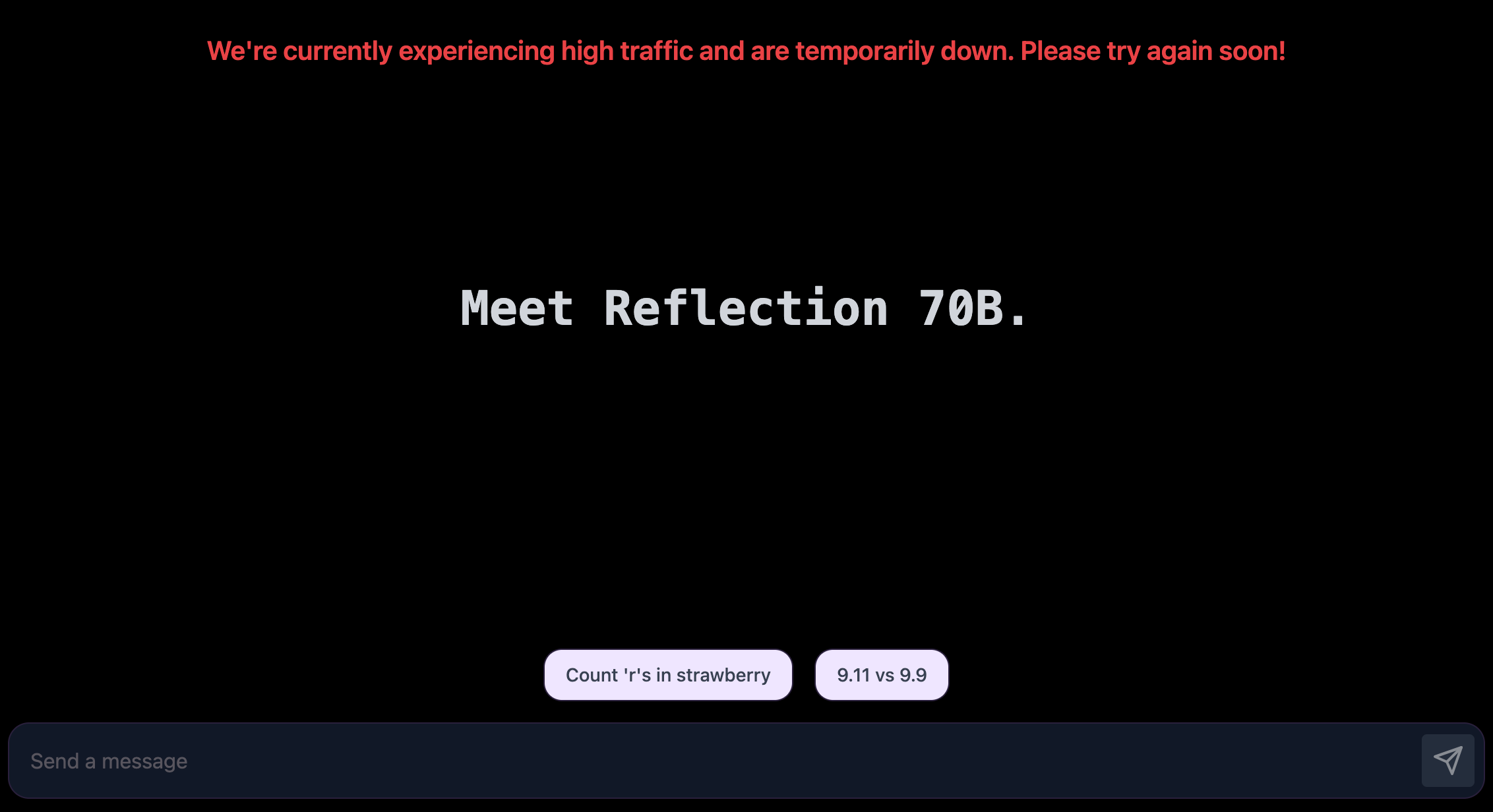
De Reflectiespeelplaats laat je het model uitproberen, maar zegt dat de demo tijdelijk niet beschikbaar is vanwege de grote vraag. De promptsuggesties "Tel de 'r' in aardbei" en "9,11 vs 9,9" geven aan dat het model deze lastige prompts goed begrijpt. Maar sommige gebruikers beweren dat Reflection speciaal is afgestemd om deze prompts te beantwoorden.
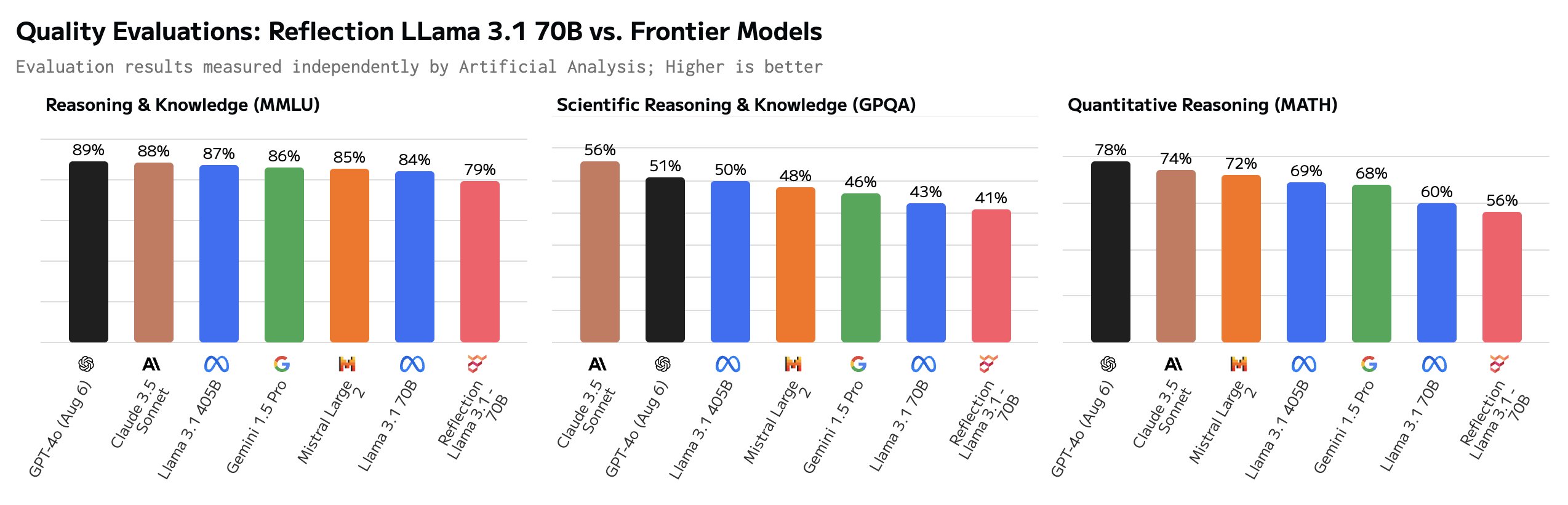
Sommige gebruikers zetten vraagtekens bij de indrukwekkende benchmarks. Vooral de GSM8K van meer dan 99% zag er verdacht uit.
Hey Matt! Dit is super interessant, maar ik ben nogal verbaasd om een GSM8k score van meer dan 99% te zien. Ik heb begrepen dat het waarschijnlijk is dat meer dan 1% van GSM8k verkeerd gelabeld is (het goede antwoord is eigenlijk fout)!
- Hugh Zhang (@hughbzhang) 5 september 2024
Sommige van de ground truth antwoorden in de GSM8K dataset zijn eigenlijk fout. Met andere woorden, de enige manier om hoger te scoren dan 99% op de GSM8K was door dezelfde foute antwoorden te geven op die problemen.
Na wat testen zeggen gebruikers dat Reflection eigenlijk slechter is dan Llama 3.1 en dat het eigenlijk gewoon Llama 3 was met LoRA-tuning toegepast.
In reactie op de negatieve feedback plaatste Shumer een uitleg op X met de volgende tekst: "Snelle update - we hebben de gewichten opnieuw geüpload, maar er is nog steeds een probleem. We zijn net opnieuw begonnen met trainen om elk mogelijk probleem te elimineren. Zou binnenkort klaar moeten zijn."
Shumer legde uit dat er een probleem was met de API en dat er aan gewerkt werd. Ondertussen gaf hij toegang tot een geheime, privé API zodat twijfelaars Reflection konden uitproberen terwijl ze aan de oplossing werkten.
En dat is waar de wielen los lijken te komen, aangezien voorzichtig vragen lijkt aan te tonen dat de API eigenlijk gewoon een Claude 3.5 Sonnet wrapper is.
"Reflection API" is een sonnet 3.5 wrapper met prompt. En ze verbergen het momenteel door de string 'claude' eruit te filteren.https://t.co/c4Oj8Y3Ol1 https://t.co/k0ECeo9a4i pic.twitter.com/jTm2Q85Q7b
- Joseph (@EchteJosephus) 8 september 2024
Latere tests toonden aan dat de API uitvoer van Llama en GPT-4o terugstuurde. Shumer houdt vol dat de originele resultaten accuraat zijn en dat er gewerkt wordt aan het repareren van het downloadbare model.
Zijn de sceptici een beetje voorbarig door Shumer een oplichter te noemen? Misschien was de release gewoon slecht geregeld en is Reflection 70B echt een baanbrekend open-source model. Of misschien is het weer een voorbeeld van een AI-hype om durfkapitaal op te halen bij investeerders die op zoek zijn naar het volgende grote ding in AI.
We zullen een dag of twee moeten wachten om te zien hoe dit afloopt.



