
Meta heeft zijn verbeterde Llama 3.1 modellen uitgebracht in 8B, 70B en 405B versies en heeft zich gecommitteerd aan Mark Zuckerberg's open source visie voor de toekomst van AI.
De nieuwe toevoegingen aan Meta's Llama familie van modellen worden geleverd met een uitgebreide contextlengte van 128k en ondersteuning voor acht talen.
Meta zegt dat het langverwachte 405B model "ongeëvenaarde flexibiliteit, controle en state-of-the-art mogelijkheden laat zien die wedijveren met de beste closed source modellen". Het bedrijf beweert ook dat Llama 3.1 405B "'s werelds grootste en meest capabele openlijk beschikbare foundationmodel" is.
Nu er torenhoge rekenkosten worden gemaakt om steeds grotere modellen te trainen, werd er druk gespeculeerd dat Meta's vlaggenschip, de 405B, wel eens het eerste betaalde model zou kunnen zijn.
Llama 3.1 405B werd getraind op meer dan 15 biljoen tokens met behulp van 16.000 NVIDIA H100's, die waarschijnlijk honderden miljoenen dollars hebben gekost.
In een blogpostMeta CEO Mark Zuckerberg bevestigde opnieuw het standpunt van het bedrijf dat open source AI de weg vooruit is en dat de release van Llama 3.1 de volgende stap is "in de richting van open source AI die de industriestandaard wordt".
De Llama 3.1 modellen zijn gratis te downloaden en aan te passen of te verfijnen met een reeks diensten van Amazon, Databricks en NVIDIA.
De modellen zijn ook beschikbaar op cloudserviceproviders zoals AWS, Azure, Google en Oracle.
Vanaf vandaag wijst open source de weg. Maak kennis met Llama 3.1: Onze meest capabele modellen tot nu toe.
Vandaag brengen we een verzameling nieuwe Llama 3.1 modellen uit, waaronder onze langverwachte 405B. Deze modellen leveren verbeterde redeneercapaciteiten, een grotere 128K token context... pic.twitter.com/1iKpBJuReD
- AI bij Meta (@AIatMeta) 23 juli 2024
Prestaties
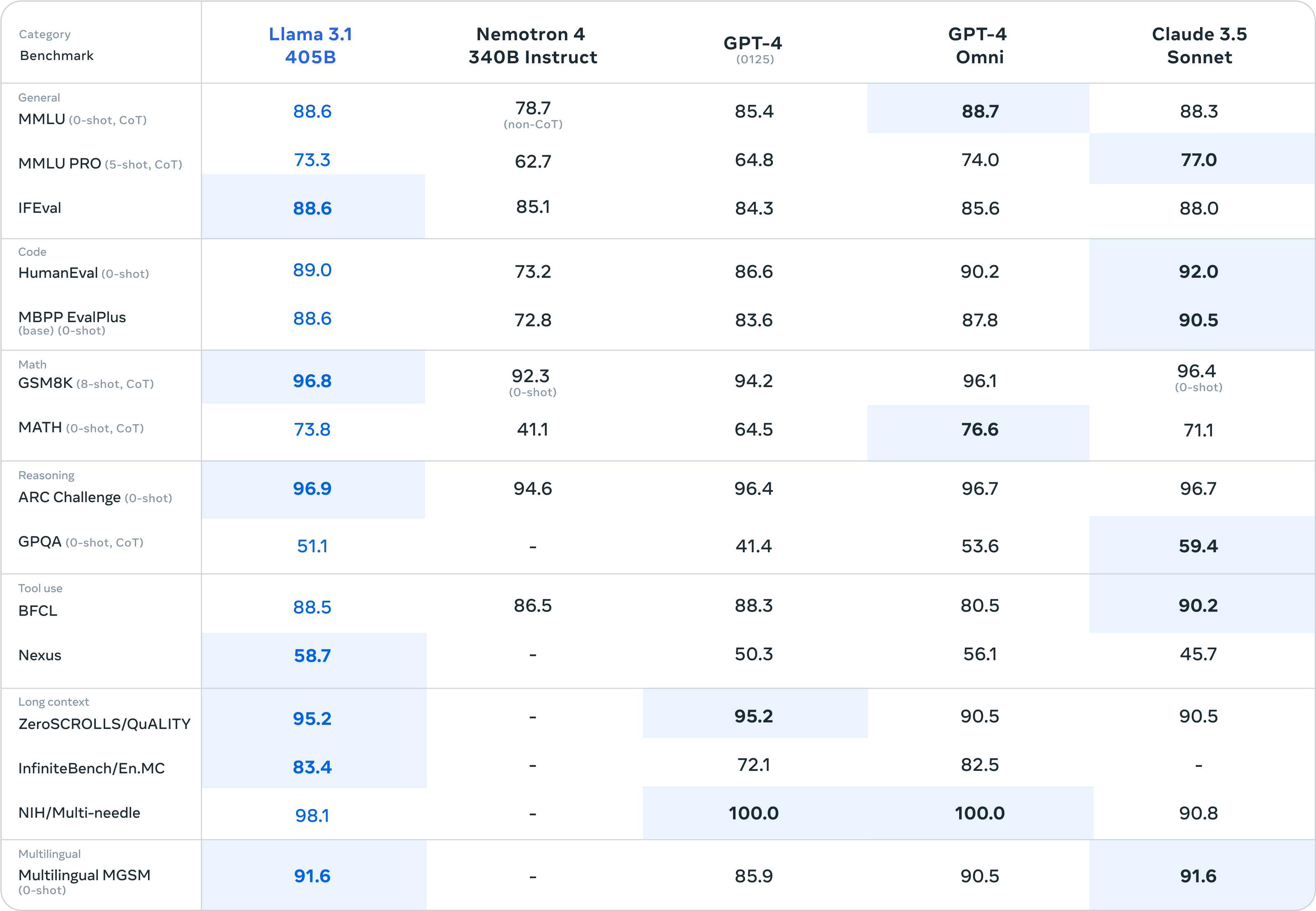
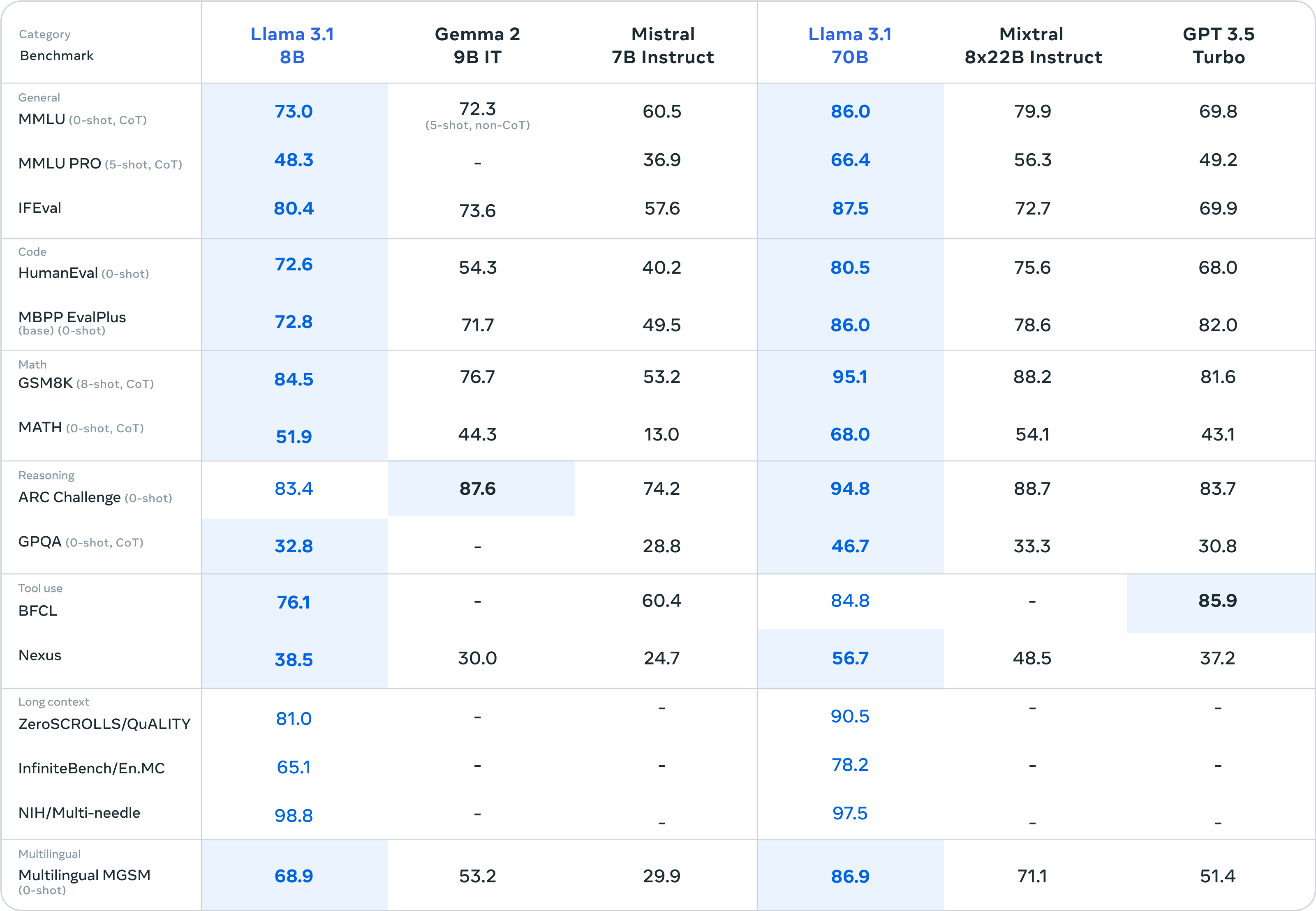
Meta zegt dat het zijn modellen heeft getest op meer dan 150 benchmarkdatasets en resultaten heeft vrijgegeven voor de meer gangbare benchmarks om te laten zien hoe zijn nieuwe modellen zich verhouden tot andere toonaangevende modellen.
Er is niet veel verschil tussen Llama 3.1 405B en GPT-4o en Claude 3.5 Sonnet. Hier zijn de cijfers voor het 405B model en de kleinere 8B en 70B versies.
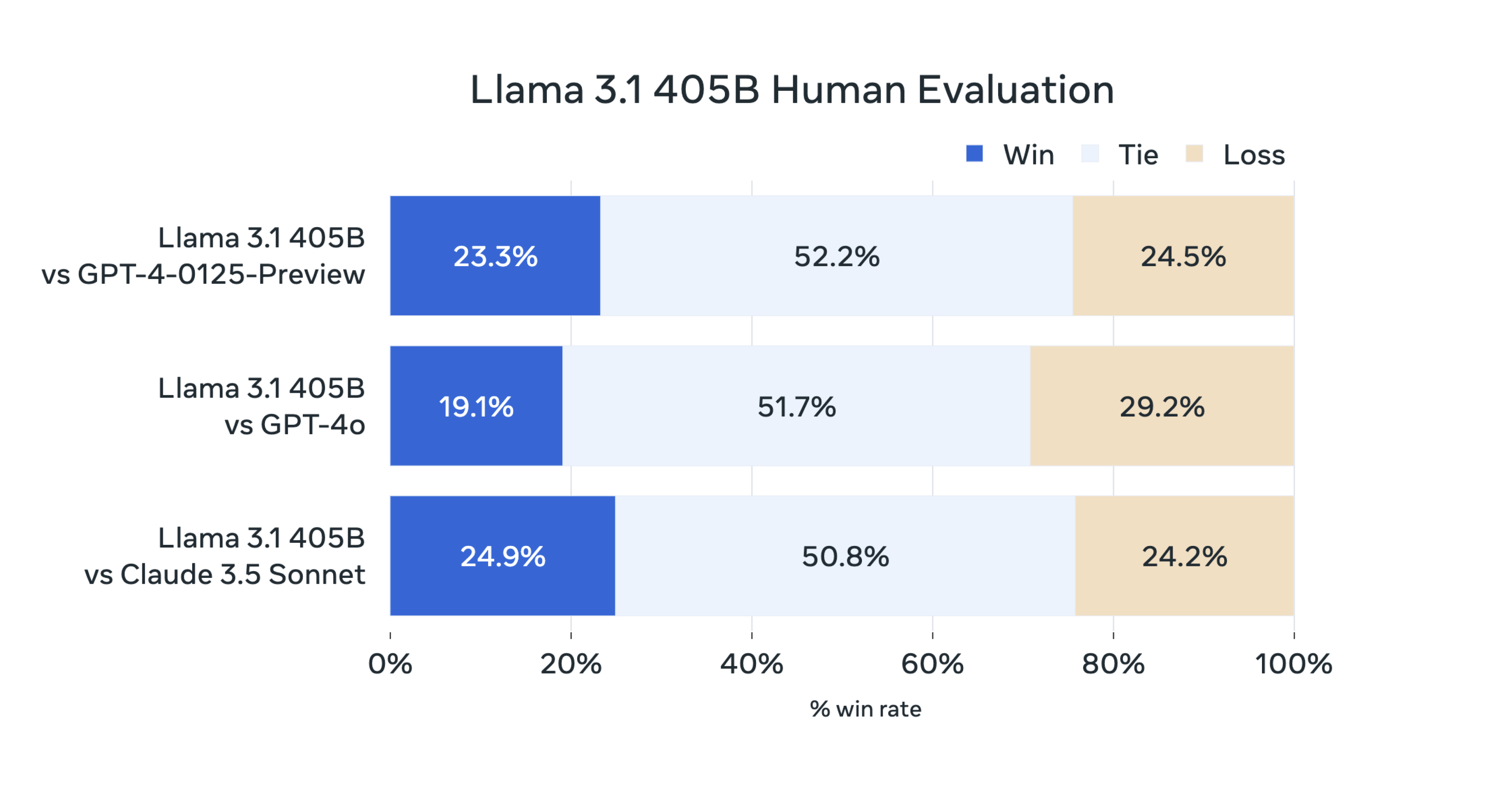
Meta voerde ook "uitgebreide menselijke evaluaties uit die Llama 3.1 vergelijken met concurrerende modellen in real-world scenario's".
Deze cijfers zijn afhankelijk van gebruikers die beslissen of ze de voorkeur geven aan de respons van het ene of het andere model.
De menselijke evaluatie van Llama 3.1 405B weerspiegelt dezelfde gelijkwaardigheid die de benchmarkcijfers laten zien.
Meta zegt dat zijn model echt open is, aangezien Llama 3.1 modelgewichten ook beschikbaar zijn om te downloaden, hoewel de trainingsgegevens niet zijn gedeeld. Het bedrijf heeft ook zijn licentie aangepast zodat Llama-modellen gebruikt kunnen worden om andere AI-modellen te verbeteren.
De vrijheid om Llama-modellen te verfijnen, aan te passen en te gebruiken zonder beperkingen heeft critici van open source AI doet alarmbellen rinkelen.
Zuckerberg stelt dat een open source aanpak de beste manier is om onbedoelde schade te voorkomen. Als een AI-model openstaat voor onderzoek, is het volgens hem minder waarschijnlijk dat het gevaarlijk opkomend gedrag ontwikkelt dat we anders zouden missen in gesloten modellen.
Als het gaat om het potentieel voor opzettelijke schade zegt Zuckerberg: "Zolang iedereen toegang heeft tot vergelijkbare generaties modellen - wat open source bevordert - dan zullen overheden en instellingen met meer rekenkracht in staat zijn om slechte actoren met minder rekenkracht te controleren."
Zuckerberg zegt over het risico dat staatsvijanden zoals China toegang krijgen tot de modellen van Meta dat pogingen om deze uit Chinese handen te houden niet zullen werken.
"Onze tegenstanders zijn goed in spionage, het stelen van modellen die op een USB-stick passen is relatief eenvoudig, en de meeste techbedrijven opereren bij lange na niet op een manier die dit moeilijker zou maken," legde hij uit.
De opwinding over een open source AI-model als Llama 3.1 405B dat het opneemt tegen de grote gesloten modellen is terecht.
Maar met geruchten over GPT-5 en Claude 3.5 Opus in de coulissen, zouden deze benchmarkresultaten wel eens niet erg oud kunnen worden.



