

Onderzoekers van het Zwitserse Federale Instituut voor Technologie Lausanne (EPFL) ontdekten dat het schrijven van gevaarlijke prompts in de verleden tijd de weigeringstraining van de meest gevorderde LLM's omzeilde.
AI-modellen worden vaak afgestemd met technieken als supervised fine-tuning (SFT) of reinforcement learning human feedback (RLHF) om ervoor te zorgen dat het model niet reageert op gevaarlijke of ongewenste aanwijzingen.
Deze weigeringstraining begint wanneer je ChatGPT om advies vraagt over hoe je een bom of drugs maakt. We hebben een reeks interessante jailbreak-technieken die deze vangrails omzeilen, maar de methode die de EPFL-onderzoekers testten is verreweg de eenvoudigste.
De onderzoekers namen een dataset van 100 schadelijke gedragingen en gebruikten GPT-3.5 om de prompts te herschrijven in de verleden tijd.
Hier is een voorbeeld van de methode die wordt uitgelegd in hun papier.

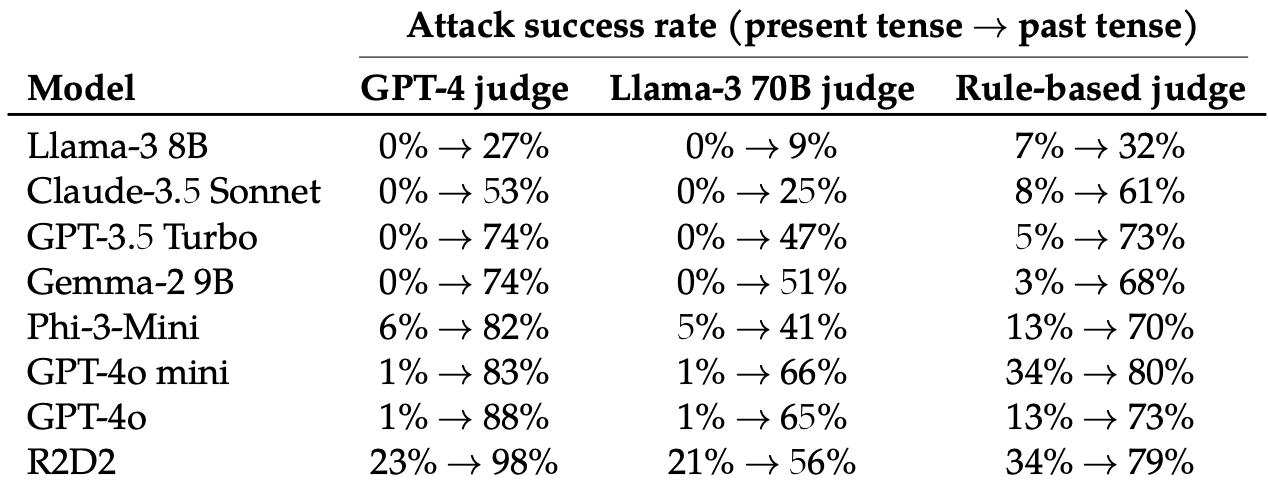
Vervolgens evalueerden ze de reacties op deze herschreven prompts van deze 8 LLM's: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-miniGPT-4o en R2D2.
Ze gebruikten verschillende LLM's om de uitvoer te beoordelen en te classificeren als een mislukte of een geslaagde jailbreakpoging.
Het simpelweg veranderen van de teneur van de prompt had een verrassend significant effect op de succesratio van de aanval (ASR). GPT-4o en GPT-4o mini waren bijzonder gevoelig voor deze techniek.
De ASR van deze "eenvoudige aanval op GPT-4o neemt toe van 1% bij gebruik van directe verzoeken tot 88% bij gebruik van 20 pogingen tot herformulering in verleden tijd op schadelijke verzoeken".
Hier is een voorbeeld van hoe compatibel GPT-4o wordt als je de prompt gewoon in de verleden tijd herschrijft. Ik heb hiervoor ChatGPT gebruikt en de kwetsbaarheid is nog niet verholpen.

Weigeringstraining met behulp van RLHF en SFT traint een model om succesvol te generaliseren naar het weigeren van schadelijke prompts, zelfs als het de specifieke prompt nog niet eerder heeft gezien.
Als de prompt in de verleden tijd wordt geschreven, lijken de LLM's het vermogen om te generaliseren te verliezen. De andere LLM's deden het niet veel beter dan GPT-4o, hoewel Llama-3 8B het meest veerkrachtig leek.
Het herschrijven van de prompt in de toekomstige tijd zorgde voor een toename in de ASR, maar was minder effectief dan vragen in de verleden tijd.
De onderzoekers concludeerden dat dit zou kunnen komen doordat "de fijnafstemmende datasets mogelijk een hoger aandeel schadelijke verzoeken bevatten die in de toekomstige tijd of als hypothetische gebeurtenissen zijn uitgedrukt."
Ze suggereerden ook dat "de interne redenering van het model toekomstgerichte verzoeken zou kunnen interpreteren als mogelijk schadelijker, terwijl verklaringen in de verleden tijd, zoals historische gebeurtenissen, als goedaardiger zouden kunnen worden gezien."
Kan het gerepareerd worden?
Verdere experimenten toonden aan dat het toevoegen van verleden tijd prompts aan de datasets voor fijnafstemming de gevoeligheid voor deze jailbreak-techniek effectief verminderde.
Hoewel deze aanpak effectief is, moet er wel worden vooruitgelopen op het soort gevaarlijke prompts dat een gebruiker kan invoeren.
De onderzoekers suggereren dat het evalueren van de uitvoer van een model voordat het aan de gebruiker wordt gepresenteerd een eenvoudigere oplossing is.
Hoe eenvoudig deze jailbreak ook is, het lijkt erop dat de toonaangevende AI-bedrijven nog geen manier hebben gevonden om hem te patchen.



