

Een onderzoek van de Universiteit van Oxford heeft een manier ontwikkeld om te testen wanneer taalmodellen "onzeker" zijn over hun output en het risico lopen te hallucineren.
AI "hallucinaties" verwijzen naar een fenomeen waarbij grote taalmodellen (LLM's) vloeiende en plausibele antwoorden genereren die niet waarheidsgetrouw of consistent zijn.
Hallucinaties zijn moeilijk - zo niet onmogelijk - te scheiden van AI-modellen. AI-ontwikkelaars zoals OpenAI, Google en Anthropic hebben allemaal toegegeven dat hallucinaties waarschijnlijk een bijproduct zullen blijven van interactie met AI.
Zoals Dr. Sebastian Farquhar, een van de auteurs van het onderzoek, legt uit in een blogpost"LLM's zijn zeer goed in staat om hetzelfde op veel verschillende manieren te zeggen, waardoor het moeilijk kan zijn om te zeggen wanneer ze zeker zijn van een antwoord en wanneer ze letterlijk gewoon iets verzinnen."
Het Cambridge Woordenboek heeft zelfs een AI-gerelateerde definitie van het woord in 2023 en noemde het "Woord van het Jaar".
Deze universiteit van Oxford onderzoekgepubliceerd in Nature, probeert te beantwoorden hoe we kunnen detecteren wanneer die hallucinaties het meest waarschijnlijk zullen optreden.
Het introduceert een concept genaamd "semantische entropie", dat de onzekerheid van de uitvoer van een LLM meet op betekenisniveau in plaats van alleen de specifieke woorden of zinnen die zijn gebruikt.
Door de semantische entropie van de reacties van een LLM te berekenen, kunnen de onderzoekers het vertrouwen van het model in zijn output schatten en gevallen identificeren waarin het waarschijnlijk hallucineert.
Semantische entropie in LLM's uitgelegd
Semantische entropie, zoals gedefinieerd in het onderzoek, meet de onzekerheid of inconsistentie in de betekenis van de antwoorden van een LLM. Het helpt detecteren wanneer een LLM aan het hallucineren is of onbetrouwbare informatie genereert.
Eenvoudiger gezegd, meet semantische entropie hoe "verward" de uitvoer van een LLM is.
De LLM zal waarschijnlijk betrouwbare informatie geven als de betekenis van de output nauw verwant en consistent is. Maar als de betekenissen verspreid en inconsistent zijn, is dat een teken dat de LLM misschien hallucineert of onjuiste informatie genereert.
Zo werkt het:
- De onderzoekers hebben de LLM actief gevraagd om meerdere mogelijke antwoorden op dezelfde vraag te genereren. Dit werd bereikt door de vraag meerdere keren aan de LLM te stellen, elke keer met een andere random seed of kleine variatie in de invoer.
- Semantische entropie onderzoekt reacties en groepeert die met dezelfde onderliggende betekenis, zelfs als ze verschillende woorden of formuleringen gebruiken.
- Als de LLM zelfverzekerd is over het antwoord, zouden zijn antwoorden vergelijkbare betekenissen moeten hebben, wat resulteert in een lage score voor semantische entropie. Dit suggereert dat de LLM de informatie duidelijk en consistent begrijpt.
- Als de LLM echter onzeker of verward is, zullen zijn antwoorden een grotere verscheidenheid aan betekenissen hebben, waarvan sommige inconsistent kunnen zijn of geen verband houden met de vraag. Dit resulteert in een hoge semantische entropiescore, wat aangeeft dat de LLM mogelijk hallucineert of onbetrouwbare informatie genereert.
Om de effectiviteit te evalueren, pasten de onderzoekers semantische entropie toe op een diverse set van vraag-antwoord taken. Dit omvatte benchmarks zoals triviavragen, begrijpend lezen, woordproblemen en biografieën.
Over de hele linie presteerde semantische entropie beter dan bestaande methoden voor het detecteren wanneer een LLM waarschijnlijk een onjuist of inconsistent antwoord zou genereren.
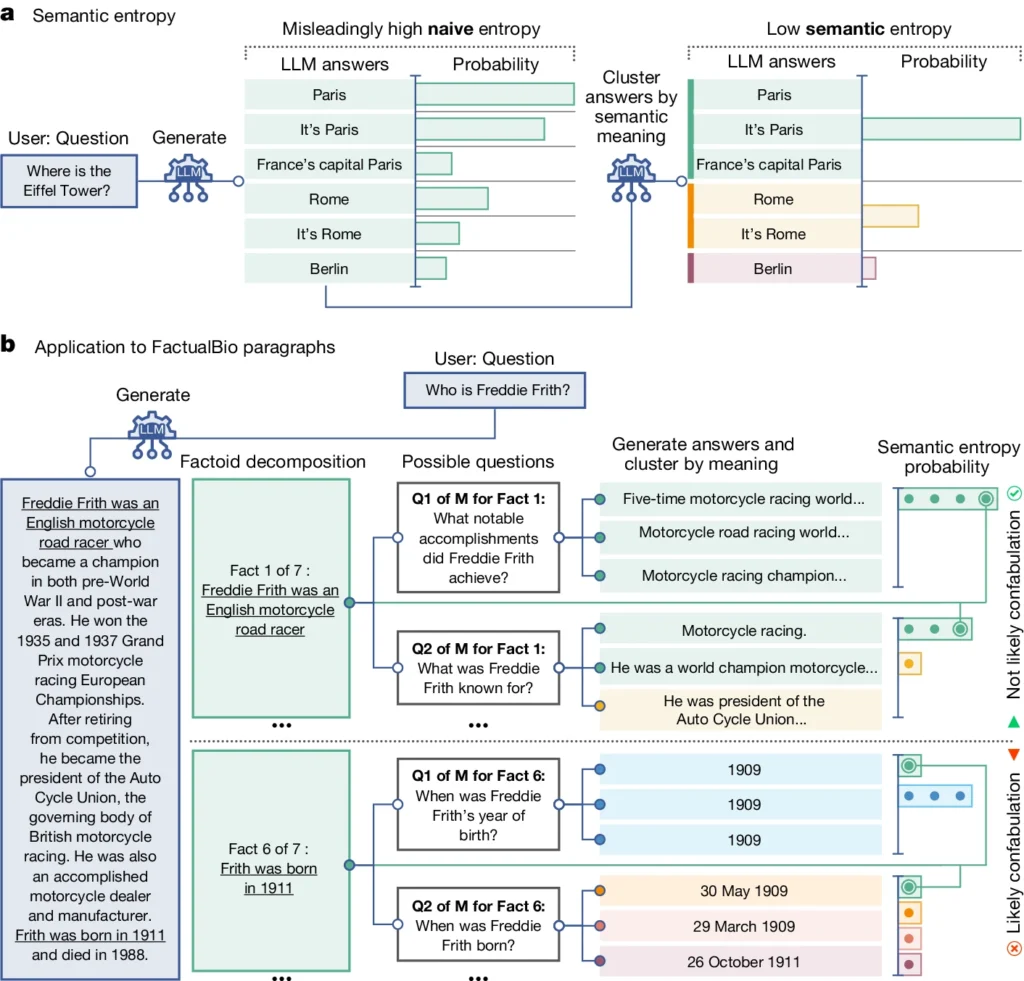
In het bovenstaande diagram kun je zien hoe sommige prompts de LLM aanzetten tot het genereren van een geconfabuleerd (onnauwkeurig, hallucinerend) antwoord. Er wordt bijvoorbeeld een geboortedag en -maand gegenereerd voor vragen onder aan het diagram wanneer de informatie die nodig is om deze vragen te beantwoorden, niet is opgenomen in de oorspronkelijke informatie.
Implicaties van het opsporen van hallucinaties
Dit werk kan hallucinaties helpen verklaren en LLM's betrouwbaarder en betrouwbaarder maken.
Door een manier te bieden om te detecteren wanneer een LLM onzeker is of geneigd is tot hallucinatie, maakt semantische entropie de weg vrij voor het inzetten van deze AI-tools in domeinen waar veel op het spel staat en waar feitelijke nauwkeurigheid cruciaal is, zoals gezondheidszorg, recht en financiën.
Foutieve resultaten kunnen mogelijk catastrofale gevolgen hebben wanneer ze van invloed zijn op situaties waarin veel op het spel staat, zoals blijkt uit sommige mislukt voorspellend politiewerk en gezondheidszorgsystemen.
Het is echter ook belangrijk om te onthouden dat hallucinaties slechts één soort fout zijn die LLM's kunnen maken.
Zoals Dr. Farquhar uitlegt: "Als een LLM consequent fouten maakt, zal deze nieuwe methode dat niet opvangen. De gevaarlijkste fouten van AI komen wanneer een systeem iets slechts doet, maar zelfverzekerd en systematisch is. Er is nog veel werk te doen."
Niettemin betekent de semantische entropiemethode van het Oxford-team een grote stap voorwaarts in ons vermogen om de beperkingen van AI-taalmodellen te begrijpen en te beperken.
Een objectieve manier om ze te detecteren brengt ons dichter bij een toekomst waarin we het potentieel van AI kunnen benutten en er tegelijkertijd voor kunnen zorgen dat het een betrouwbaar hulpmiddel blijft in dienst van de mensheid.



