

Microsoft heeft Phi-3 Mini gelanceerd, een piepklein taalmodel dat deel uitmaakt van de strategie van het bedrijf om lichtgewicht, functiespecifieke AI-modellen te ontwikkelen.
Bij de ontwikkeling van taalmodellen zijn de parameters, trainingsdatasets en contextvensters steeds groter geworden. Het opschalen van deze modellen leverde krachtigere mogelijkheden op, maar tegen een prijs.
De traditionele aanpak voor het trainen van een LLM is om deze enorme hoeveelheden gegevens te laten verbruiken, waarvoor enorme rekenkracht nodig is. Het trainen van een LLM zoals GPT-4 heeft naar schatting ongeveer 3 maanden geduurd en meer dan $21m gekost.
GPT-4 is een geweldige oplossing voor taken die complexe redeneringen vereisen, maar overkill voor eenvoudigere taken zoals het maken van content of een verkoopchatbot. Het is alsof je een Zwitsers zakmes gebruikt terwijl je alleen een eenvoudige briefopener nodig hebt.
Met slechts 3,8B parameters is de Phi-3 Mini piepklein. Toch is het volgens Microsoft een ideale lichtgewicht, goedkope oplossing voor taken als het samenvatten van een document, het extraheren van inzichten uit rapporten en het schrijven van productbeschrijvingen of berichten in sociale media.
De MMLU benchmark cijfers laten zien dat de Phi-3 Mini en de nog uit te brengen grotere Phi modellen grotere modellen verslaan zoals Mistral 7B en Gemma 7B.
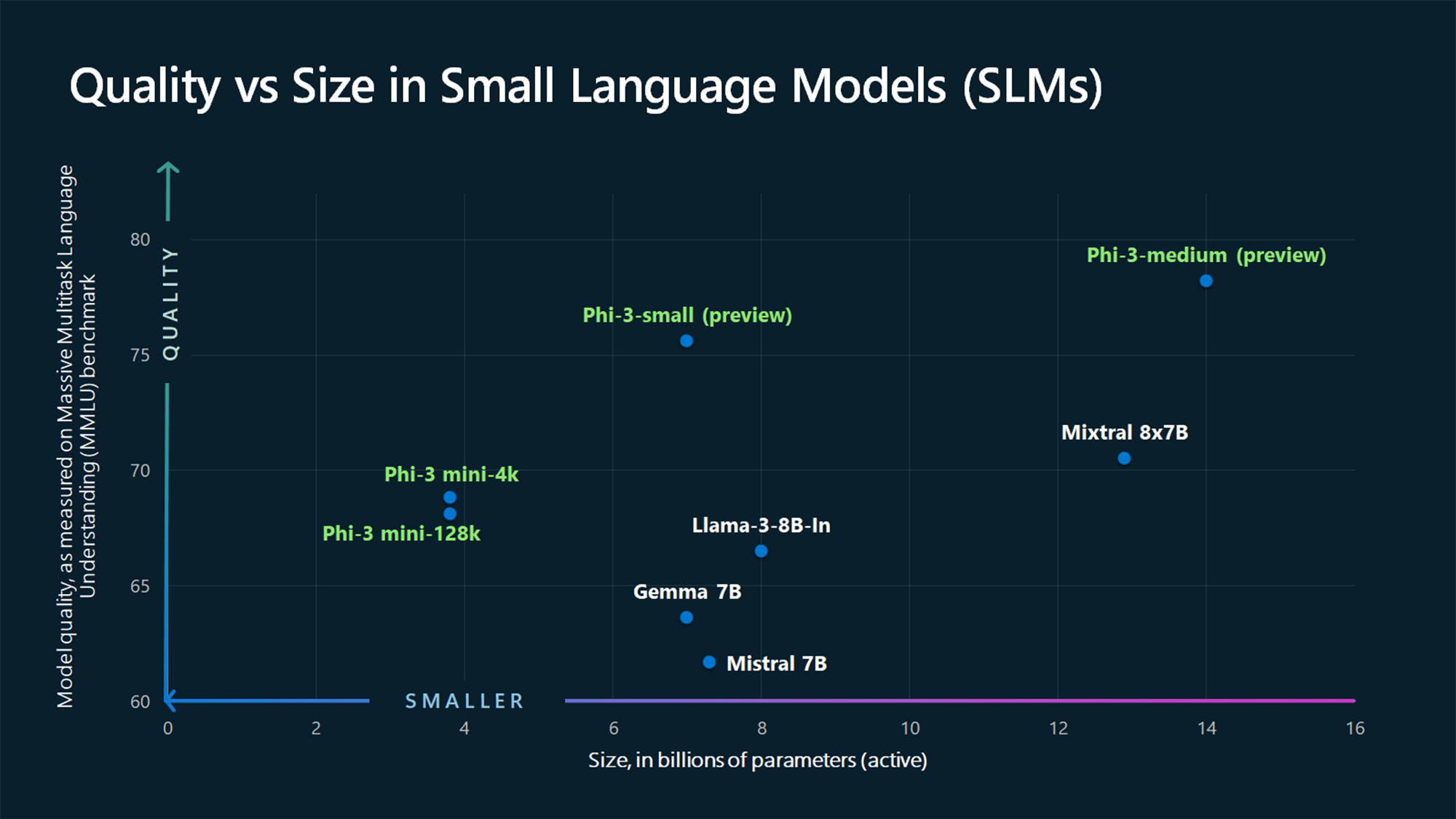
Microsoft zegt dat Phi-3-small (7B parameters) en Phi-3-medium (14B parameters) "binnenkort" beschikbaar zullen zijn in de Azure AI Model Catalog.
Grotere modellen zoals GPT-4 zijn nog steeds de gouden standaard en we kunnen waarschijnlijk verwachten dat GPT-5 nog groter zal zijn.
SLM's zoals de Phi-3 Mini bieden een aantal belangrijke voordelen die grotere modellen niet hebben. SLM's zijn goedkoper om nauwkeurig af te stellen, vereisen minder rekenkracht en kunnen on-device draaien, zelfs in situaties waar geen internettoegang beschikbaar is.
Het inzetten van een SLM aan de rand resulteert in minder latency en maximale privacy omdat er geen gegevens heen en weer hoeven te worden gestuurd naar de cloud.
Hier is Sebastien Bubeck, VP van GenAI onderzoek bij Microsoft AI met een demo van de Phi-3 Mini. Het is supersnel en indrukwekkend voor zo'n klein model.
phi-3 is er, en het is... goed :-).
Ik heb een korte demo gemaakt om je een idee te geven van wat phi-3-mini (3.8B) kan doen. Blijf kijken voor de open weights release en meer aankondigingen morgenochtend!
(En natuurlijk zou dit niet compleet zijn zonder de gebruikelijke tabel met benchmarks!) pic.twitter.com/AWA7Km59rp
- Sebastien Bubeck (@SebastienBubeck) 23 april 2024
Samengestelde synthetische gegevens
Phi-3 Mini is het resultaat van het loslaten van het idee dat enorme hoeveelheden gegevens de enige manier zijn om een model te trainen.
Sebastien Bubeck, vicepresident generatief AI-onderzoek bij Microsoft, vroeg: "In plaats van te trainen op alleen ruwe webdata, waarom zoek je niet naar data van extreem hoge kwaliteit?"
Microsoft Research machine learning expert Ronen Eldan las verhaaltjes voor het slapen gaan voor aan zijn dochter toen hij zich afvroeg of een taalmodel kon leren door alleen woorden te gebruiken die een 4-jarige kon begrijpen.
Dit leidde tot een experiment waarbij ze een dataset creëerden die begon met 3.000 woorden. Met alleen deze beperkte woordenschat lieten ze een LLM miljoenen korte kinderverhalen maken die werden samengevoegd in een dataset met de naam TinyStories.
De onderzoekers gebruikten vervolgens TinyStories om een extreem klein model met 10M parameters te trainen dat vervolgens in staat was om "vloeiende verhalen met een perfecte grammatica" te genereren.
Ze bleven deze aanpak voor het genereren van synthetische gegevens itereren en opschalen om geavanceerdere, maar zorgvuldig gecureerde en gefilterde synthetische datasets te maken die uiteindelijk werden gebruikt om Phi-3 Mini te trainen.
Het resultaat is een piepklein model dat betaalbaarder zal zijn om te gebruiken terwijl het prestaties biedt die vergelijkbaar zijn met GPT-3.5.
Kleinere maar meer capabele modellen zullen ervoor zorgen dat bedrijven niet meer standaard kiezen voor grote LLM's zoals GPT-4. We zouden ook snel oplossingen kunnen zien waarbij een LLM het zware werk doet, maar eenvoudigere taken delegeert aan lichtgewicht modellen.



