

Onderzoekers van DeepMind en Stanford University hebben een AI-agent ontwikkeld die LLM's op feiten controleert en benchmarking van de feitelijkheid van AI-modellen mogelijk maakt.
Zelfs de beste AI-modellen hebben nog steeds de neiging om hallucineren soms. Als je ChatGPT vraagt om je de feiten te geven over een onderwerp, hoe langer het antwoord, hoe waarschijnlijker het is dat het enkele feiten bevat die niet waar zijn.
Welke modellen zijn feitelijk nauwkeuriger dan andere bij het genereren van langere antwoorden? Het is moeilijk te zeggen omdat we tot nu toe geen benchmark hadden om de feitelijkheid van LLM lange antwoorden te meten.
DeepMind heeft eerst GPT-4 gebruikt om LongFact te maken, een set van 2.280 prompts in de vorm van vragen over 38 onderwerpen. Deze prompts vragen om lange antwoorden van de geteste LLM.
Vervolgens creëerden ze een AI-agent met GPT-3.5-turbo om Google te gebruiken om te controleren hoe feitelijk de antwoorden waren die de LLM genereerde. Ze noemden de methode Search-Augmented Factuality Evaluator (SAFE).
SAFE splitst het lange antwoord van de LLM eerst op in afzonderlijke feiten. Het stuurt vervolgens zoekopdrachten naar Google Search en beoordeelt het waarheidsgehalte van het feit op basis van informatie in de geretourneerde zoekresultaten.
Hier is een voorbeeld van de onderzoeksdocument.
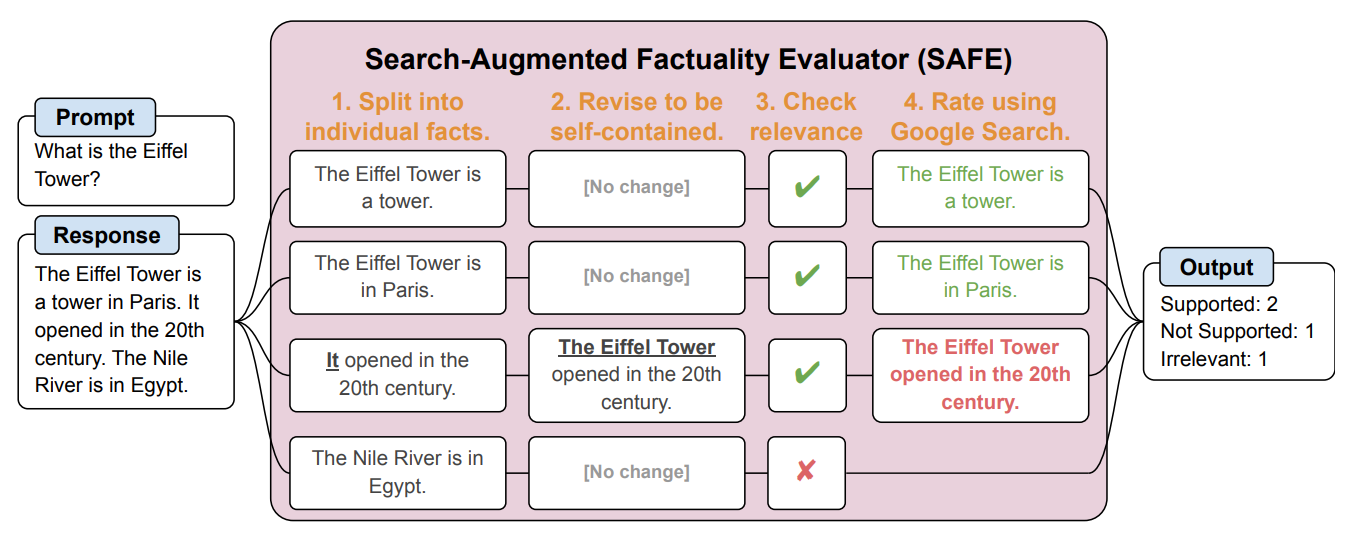
De onderzoekers zeggen dat SAFE "bovenmenselijke prestaties" levert in vergelijking met menselijke annotators die de feiten controleren.
SAFE was het eens met 72% van de menselijke annotaties, en waar het verschilde met de mensen bleek het 76% van de tijd juist te zijn. Het was ook 20 keer goedkoper dan crowdsourced menselijke annotators. LLM's zijn dus betere en goedkopere fact-checkers dan mensen.
De kwaliteit van de respons van de geteste LLM's werd gemeten aan de hand van het aantal feiten in de respons in combinatie met hoe feitelijk de afzonderlijke feiten waren.
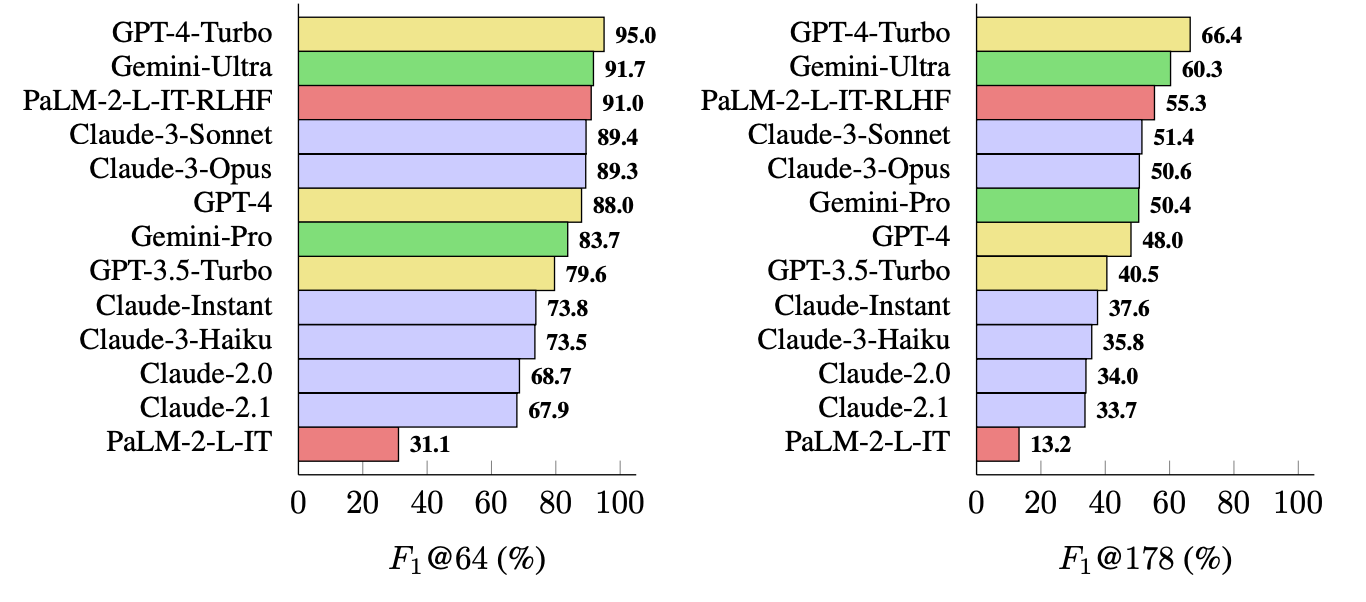
De metriek die ze gebruikten (F1@K) schat het door mensen geprefereerde "ideale" aantal feiten in een antwoord. De benchmarktests gebruikten 64 als mediaan voor K en 178 als maximum.
Simpel gezegd is F1@K een maatstaf voor "Gaf het antwoord me zoveel feiten als ik wilde?" gecombineerd met "Hoeveel van die feiten waren waar?".
Welke LLM is het meest feitelijk?
De onderzoekers gebruikten LongFact om 13 LLM's uit de Gemini, GPT, Claude en PaLM-2 families te vragen. Daarna gebruikten ze SAFE om de feitelijkheid van hun antwoorden te evalueren.
GPT-4-Turbo staat bovenaan de lijst als het meest feitelijke model bij het genereren van lange antwoorden. Het werd op de voet gevolgd door Gemini-Ultra en PaLM-2-L-IT-RLHF. De resultaten toonden aan dat grotere LLM's feitelijker zijn dan kleinere.
De F1@K-berekening zou datawetenschappers waarschijnlijk enthousiast maken, maar voor de eenvoud laten deze benchmarkresultaten zien hoe feitelijk elk model is bij het retourneren van gemiddelde lengte en langere antwoorden op de vragen.
SAFE is een goedkope en effectieve manier om LLM long-form factuality te kwantificeren. Het is sneller en goedkoper dan mensen om feiten te controleren, maar het is nog steeds afhankelijk van de waarheidsgetrouwheid van de informatie die Google retourneert in de zoekresultaten.
DeepMind gaf SAFE vrij voor openbaar gebruik en suggereerde dat het zou kunnen helpen de feitelijkheid van LLM's te verbeteren via betere training vooraf en fijnafstemming. Het zou een LLM ook in staat kunnen stellen zijn feiten te controleren voordat de uitvoer aan een gebruiker wordt gepresenteerd.
OpenAI zal blij zijn om te zien dat onderzoek van Google laat zien dat GPT-4 Gemini verslaat in weer een andere benchmark.



