

Apple moet nog officieel een AI-model uitbrengen, maar een nieuw onderzoeksartikel geeft inzicht in de voortgang van het bedrijf bij de ontwikkeling van modellen met geavanceerde multimodale mogelijkheden.
Het papiergetiteld "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", introduceert Apple's familie van MLLM's genaamd MM1.
MM1 laat indrukwekkende vaardigheden zien op het gebied van beeldondertiteling, het beantwoorden van visuele vragen (VQA) en het interpreteren van natuurlijke taal. De onderzoekers leggen uit dat ze dankzij de zorgvuldige keuze van beeld-hoofdonderschriftparen superieure resultaten hebben behaald, vooral in leerscenario's met weinig beelden.
Wat MM1 onderscheidt van andere MLLM's is zijn superieure vermogen om instructies op te volgen in meerdere beelden en om te redeneren over de complexe scènes die het voorgeschoteld krijgt.
De MM1-modellen bevatten tot 30B parameters, wat drie keer zoveel is als GPT-4V, de component die OpenAI's GPT-4 zijn vision-mogelijkheden geeft.
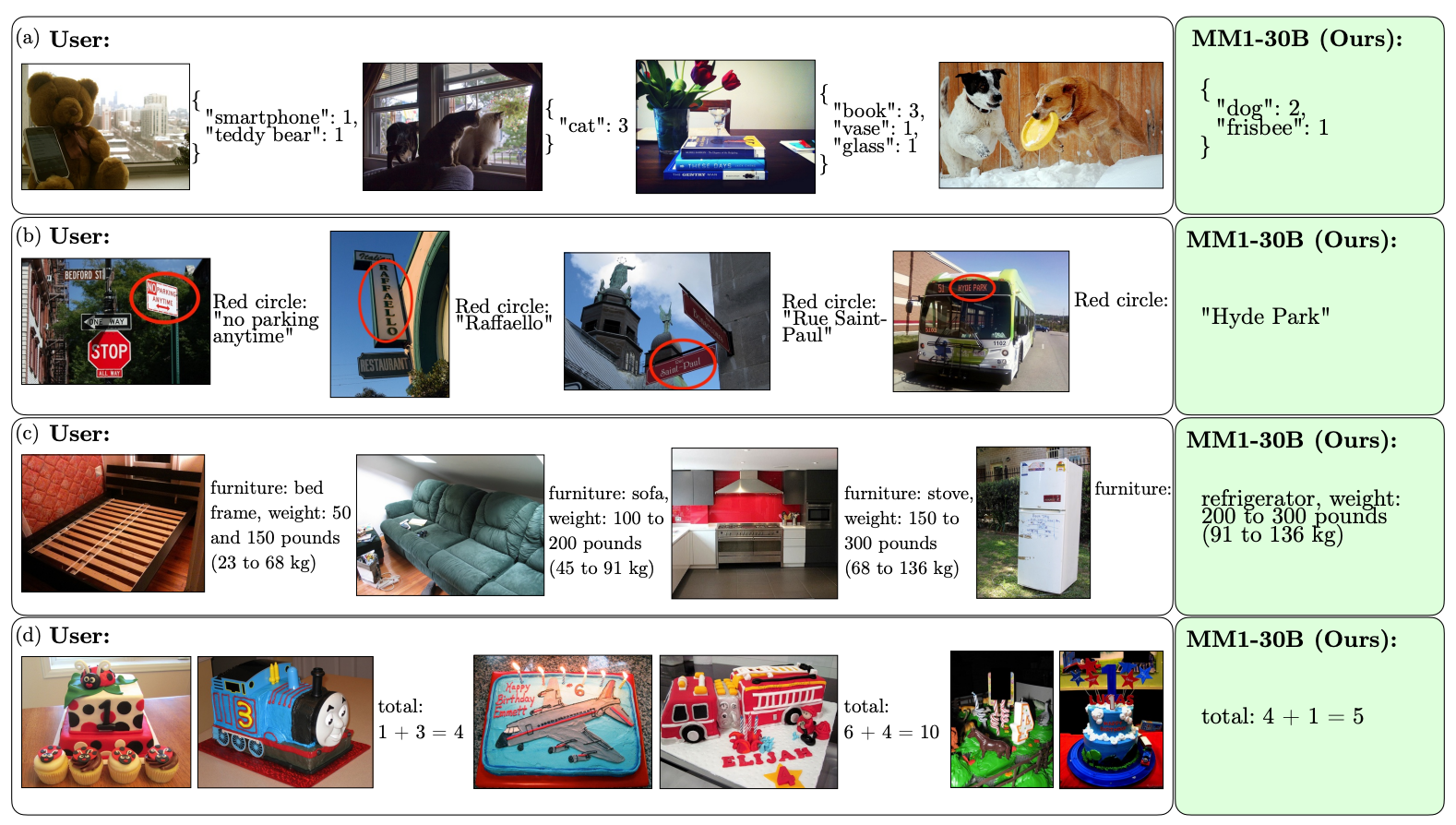
Hier zijn enkele voorbeelden van de VQA-mogelijkheden van MM1.

MM1 onderging grootschalige multimodale pre-training op "een dataset van 500M interleaved beeld-tekst documenten, met 1B afbeeldingen en 500B tekst tokens".
De schaal en diversiteit van de voortraining stellen MM1 in staat om indrukwekkende voorspellingen te doen in de context en aangepaste opmaak te volgen met een klein aantal voorbeelden. Hier zijn voorbeelden van hoe MM1 de gewenste uitvoer en opmaak leert op basis van slechts 3 voorbeelden.
Om AI-modellen te maken die kunnen "zien" en redeneren is een vision-language connector nodig die beelden en taal vertaalt in een eenduidige representatie die het model kan gebruiken voor verdere verwerking.
De onderzoekers ontdekten dat het ontwerp van de vision-taalverbinding minder bepalend was voor de prestaties van MM1. Interessant genoeg hadden de beeldresolutie en het aantal beeldpunten de grootste invloed.
Het is interessant om te zien hoe open Apple is geweest in het delen van zijn onderzoek met de bredere AI-gemeenschap. De onderzoekers stellen dat "we in dit artikel het bouwproces van MLLM documenteren en proberen ontwerplessen te formuleren, waarvan we hopen dat ze nuttig zijn voor de gemeenschap."
De gepubliceerde resultaten zullen waarschijnlijk van invloed zijn op de richting die andere MMLM-ontwikkelaars inslaan met betrekking tot de architectuur en de keuze van pre-traininggegevens.
Hoe MM1-modellen precies zullen worden geïmplementeerd in de producten van Apple valt nog te bezien. De gepubliceerde voorbeelden van de mogelijkheden van MM1 wijzen erop dat Siri een stuk slimmer wordt als ze uiteindelijk leert zien.



