

Ondanks de snelle vooruitgang in LLM's blijft ons begrip van hoe deze modellen omgaan met langere inputs gebrekkig.
Mosh Levy, Alon Jacoby en Yoav Goldberg van de Bar-Ilan Universiteit en het Allen Instituut voor AI onderzochten hoe de prestaties van grote taalmodellen (LLM's) variëren met veranderingen in de lengte van de invoertekst die ze te verwerken krijgen.
Ze ontwikkelden speciaal voor dit doel een redeneerraamwerk, waarmee ze de invloed van invoerlengte op LLM redeneren in een gecontroleerde omgeving konden ontleden.
Het vragenkader stelde verschillende versies van dezelfde vraag voor, die elk de nodige informatie bevatten om de vraag te beantwoorden, opgevuld met bijkomende, irrelevante tekst van verschillende lengte en type.
Dit maakt het mogelijk om de lengte van de invoer als variabele te isoleren, zodat veranderingen in de prestaties van het model direct kunnen worden toegeschreven aan de lengte van de invoer.
Belangrijkste bevindingen
Levy, Jacoby en Goldberg ontdekten dat LLM's een opmerkelijke afname in redeneerprestaties vertonen bij invoerlengtes die veel lager zijn dan wat ontwikkelaars beweren dat ze aankunnen. Ze documenteerden hun bevindingen in deze studie.
De afname werd consistent waargenomen in alle versies van de dataset, wat duidt op een systematisch probleem met het verwerken van langere invoer in plaats van een probleem dat gebonden is aan specifieke gegevensmonsters of modelarchitecturen.
Zoals de onderzoekers beschrijven: "Onze bevindingen laten een opmerkelijke achteruitgang zien in de redeneerprestaties van LLM's bij veel kortere invoerlengtes dan hun technische maximum. We laten zien dat de degradatietrend zich voordoet in elke versie van onze dataset, zij het met verschillende intensiteit."

Bovendien laat het onderzoek zien hoe traditionele meetmethoden zoals perplexiteit, die vaak worden gebruikt om LLM's te evalueren, niet correleren met de prestaties van de modellen bij redeneertaken met lange invoer.
Verder onderzoek wees uit dat de prestatieverslechtering niet alleen afhankelijk was van de aanwezigheid van irrelevante informatie (opvulling), maar ook werd waargenomen wanneer deze opvulling bestond uit dubbele relevante informatie.
Als we de twee kernoverspanningen bij elkaar houden en er tekst omheen zetten, daalt de nauwkeurigheid al. Als we alinea's tussen de spans toevoegen, dalen de resultaten nog veel meer. De daling treedt zowel op wanneer de teksten die we toevoegen lijken op de teksten van de taak, als wanneer ze totaal verschillend zijn. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26 februari 2024
Dit suggereert dat de uitdaging voor LLM's ligt in het uitfilteren van ruis en de inherente verwerking van langere tekstsequenties.
Instructies negeren
Een kritisch gebied van faalwijzen dat in het onderzoek naar voren kwam, is de neiging van LLM's om instructies te negeren die zijn ingebed in de invoer naarmate de invoerlengte toeneemt.
Modellen genereerden soms ook antwoorden die onzekerheid of een gebrek aan voldoende informatie aangaven, zoals "Er staat niet genoeg informatie in de tekst", ondanks alle noodzakelijke informatie.
Over het algemeen lijken LLM's voortdurend moeite te hebben om prioriteiten te stellen en zich te concentreren op belangrijke informatiestukken, waaronder directe instructies, naarmate de invoerlengte toeneemt.
Vertonen van vooroordelen in reacties
Een ander opmerkelijk probleem was de grotere vertekening in de antwoorden van de modellen naarmate de inputs langer werden.
De LLM's waren vooral geneigd om "Fout" te antwoorden naarmate de invoerlengte toenam. Deze vertekening duidt op een scheefgroei in de waarschijnlijkheidsschatting of het besluitvormingsproces binnen het model, mogelijk als defensief mechanisme in reactie op de toegenomen onzekerheid als gevolg van langere invoerlengtes.
De neiging om de voorkeur te geven aan "Foute" antwoorden kan ook een weerspiegeling zijn van een onderliggende onevenwichtigheid in de trainingsgegevens of een artefact van het trainingsproces van de modellen, waarbij negatieve antwoorden oververtegenwoordigd kunnen zijn of geassocieerd kunnen worden met contexten van onzekerheid en ambiguïteit.
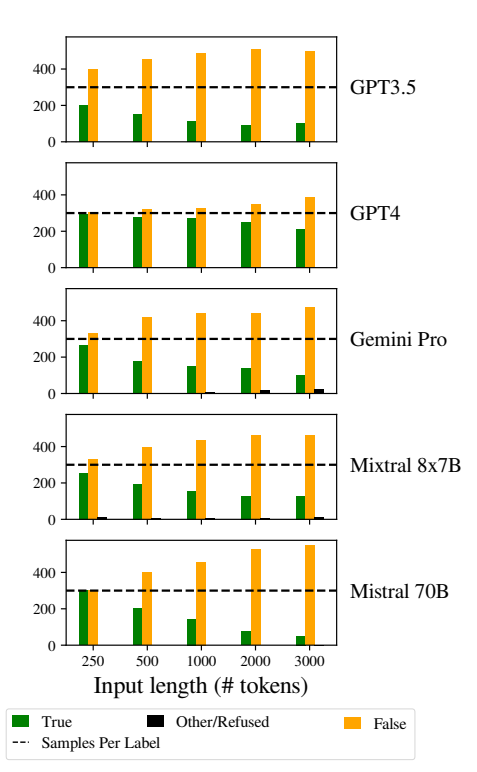
Deze vooringenomenheid beïnvloedt de nauwkeurigheid van de output van de modellen en doet twijfels rijzen over de betrouwbaarheid en eerlijkheid van LLM's in toepassingen die genuanceerd begrip en onpartijdigheid vereisen.
Het implementeren van robuuste strategieën voor biasdetectie en -mitigatie tijdens de training en fine-tuning van het model is essentieel om ongerechtvaardigde vertekeningen in de modelrespons te verminderen.
EDoor ervoor te zorgen dat de trainingsdatasets divers en evenwichtig zijn en representatief voor een breed scala aan scenario's, kunnen vertekeningen tot een minimum worden beperkt en kan de generalisatie van modellen worden verbeterd.
Dit draagt bij aan andere recente onderzoeken die op vergelijkbare wijze fundamentele problemen aan het licht brengen in hoe LLM's werken, wat leidt tot een situatie waarin die 'technische schuld' na verloop van tijd de functionaliteit en integriteit van het model kan bedreigen.



