
Het screenen van patiënten om geschikte deelnemers te vinden voor klinische onderzoeken is een arbeidsintensieve, dure en foutgevoelige taak, maar AI kan daar binnenkort verandering in brengen.
Een team onderzoekers van Brigham and Women's Hospital, Harvard Medical School en Mass General Brigham Personalized Medicine, voerde een onderzoek uit om te zien of een AI-model medische dossiers kan verwerken om geschikte kandidaten voor klinische studies te vinden.
Ze gebruikten GPT-4V, OpenAI's LLM met beeldverwerking, mogelijk gemaakt door Retrieval-Augmented Generation (RAG) om de elektronische patiëntendossiers (EHR) en klinische notities van potentiële kandidaten te verwerken.
LLM's zijn vooraf getraind met een vaste dataset en kunnen alleen vragen beantwoorden op basis van die gegevens. RAG is een techniek waarmee een LLM gegevens kan ophalen uit externe gegevensbronnen zoals het internet of interne documenten van een organisatie.
Wanneer deelnemers worden geselecteerd voor een klinische studie, wordt hun geschiktheid bepaald aan de hand van een lijst met in- en exclusiecriteria. Normaal gesproken moet getraind personeel de EHR's van honderden of duizenden patiënten uitkammen om de patiënten te vinden die aan de criteria voldoen.
De onderzoekers verzamelden gegevens van een proef waarbij patiënten met symptomatisch hartfalen werden gerekruteerd. Ze gebruikten die gegevens om te zien of GPT-4V met RAG het werk efficiënter kon doen dan studiepersoneel met behoud van nauwkeurigheid.
De gestructureerde gegevens in de EHR's van potentiële kandidaten kunnen gebruikt worden om 5 van de 6 inclusie- en 5 van de 17 exclusiecriteria voor het klinische onderzoek te bepalen. Dat is het makkelijke deel.
De overige 13 criteria moesten worden bepaald door ongestructureerde gegevens in de klinische aantekeningen van elke patiënt te bestuderen, en dat is het arbeidsintensieve deel waarvan de onderzoekers hoopten dat AI daarbij kon helpen.
Kan @Microsoft @Azure @OpenAI's #GPT4 beter presteren dan een mens voor het screenen van klinische proeven? Die vraag stelden we ons in ons meest recente onderzoek en ik ben zeer verheugd om onze resultaten in preprint te kunnen delen:https://t.co/lhOPKCcudP
GPT4 integreren in klinische...- Ozan Unlu (@OzanUnluMD) 9 februari 2024
Resultaten
De onderzoekers verkregen eerst gestructureerde beoordelingen die waren ingevuld door het studiepersoneel en klinische aantekeningen van de afgelopen twee jaar.
Ze ontwikkelden een workflow voor een op klinische aantekeningen gebaseerd vraag-antwoordsysteem op basis van RAG-architectuur en GPT-4V en noemden deze workflow RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Notities van 100 patiënten werden gebruikt als ontwikkelingsdataset, 282 patiënten als validatiedataset en 1894 patiënten als testset.
Een deskundige arts bekeek geblindeerd de patiëntendossiers om de geschiktheidsvragen te beantwoorden en de "gouden standaard" antwoorden te bepalen. Deze werden vervolgens vergeleken met de antwoorden van het onderzoekspersoneel en RECTIFIER op basis van de volgende criteria:
- Gevoeligheid - Het vermogen van een test om correct patiënten te identificeren die in aanmerking komen voor het onderzoek (echte positieven).
- Specificiteit - Het vermogen van een test om correct patiënten te identificeren die niet in aanmerking komen voor het onderzoek (echte negatieven).
- Nauwkeurigheid - De totale proportie correcte classificaties (zowel ware positieven als ware negatieven).
- Matthews correlatiecoëfficiënt (MCC) - Een metriek die gebruikt wordt om te meten hoe goed het model was in het selecteren of uitsluiten van een persoon. Een waarde van 0 is hetzelfde als een munt opgooien en 1 staat voor 100% van de tijd goed hebben.
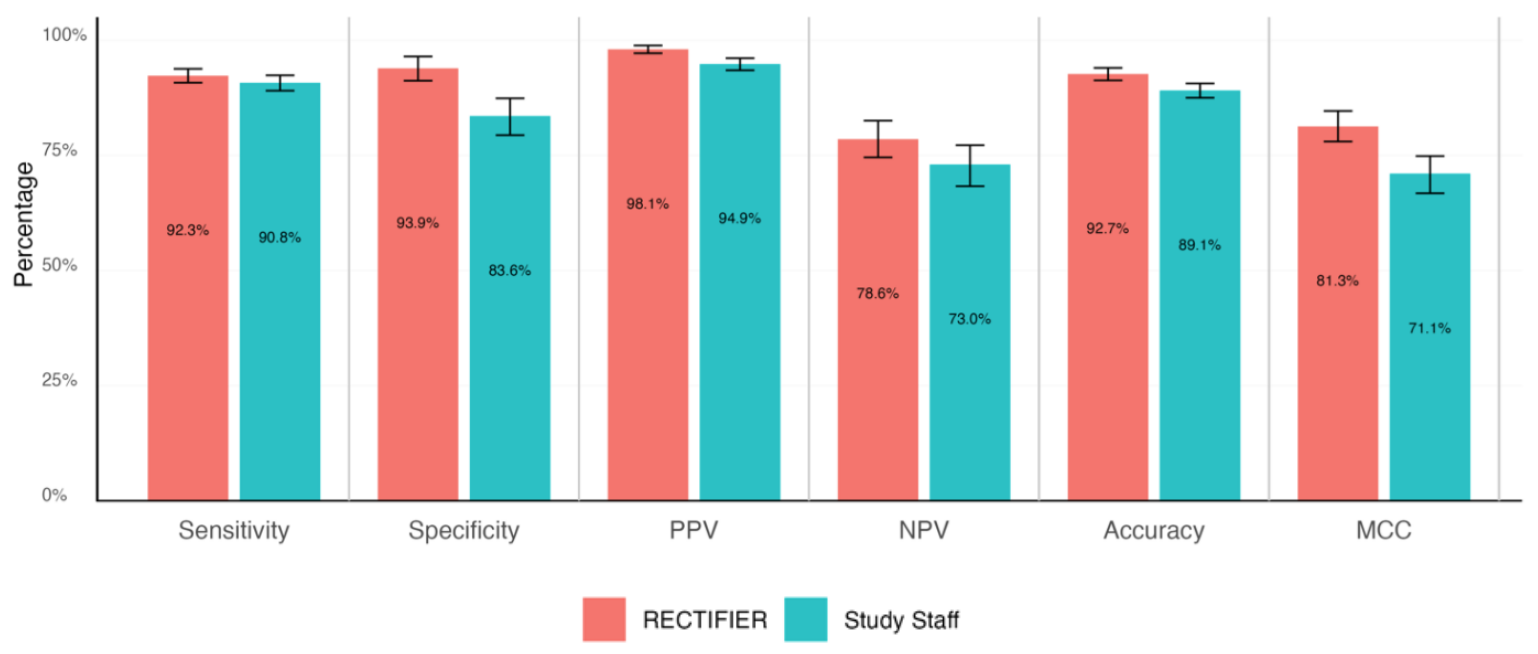
RECTIFIER presteerde net zo goed, en in sommige gevallen beter, dan het onderzoekspersoneel. Het belangrijkste resultaat van het onderzoek kwam waarschijnlijk voort uit de kostenvergelijking.
Hoewel er geen cijfers werden gegeven voor de vergoeding van het studiepersoneel, moet dit aanzienlijk meer zijn geweest dan de kosten voor het gebruik van GPT-4V, die varieerden tussen $0,02 en $0,10 per patiënt. Het gebruik van AI om een pool van 1000 potentiële kandidaten te evalueren zou een kwestie van minuten zijn en ongeveer $100 kosten.
De onderzoekers concludeerden dat het gebruik van een AI-model zoals GPT-4V met RAG de nauwkeurigheid bij het identificeren van kandidaten voor klinische proeven kan behouden of verbeteren, en dat dit efficiënter en veel goedkoper kan dan het inzetten van menselijk personeel.
Ze merkten wel op dat voorzichtigheid geboden is bij het overdragen van medische zorg aan geautomatiseerde systemen, maar het lijkt erop dat AI beter werk zal leveren dan wij als we het goed aansturen.



