

Onderzoekers van UC San Diego en New York University ontwikkelden V*, een LLM-gestuurd zoekalgoritme dat veel beter is dan GPT-4V in contextueel begrip en het nauwkeurig richten op specifieke visuele elementen in afbeeldingen.
Multimodale Large Language Models (MLLM) zoals OpenAI's GPT-4V hebben ons vorig jaar versteld doen staan met hun vermogen om vragen over afbeeldingen te beantwoorden. Hoe indrukwekkend GPT-4V ook is, het heeft soms moeite met complexe afbeeldingen en mist vaak kleine details.
Het V*-algoritme gebruikt een Visual Question Answering (VQA) LLM om te bepalen op welk deel van de afbeelding moet worden gefocust om een visuele vraag te beantwoorden. De onderzoekers noemen deze combinatie Show, sEArch en telL (SEAL).
Als iemand je een afbeelding met een hoge resolutie zou geven en je er een vraag over zou stellen, zou je logica je leiden om in te zoomen op een gebied waar de kans het grootst is dat je het item in kwestie vindt. SEAL gebruikt V* om afbeeldingen op een vergelijkbare manier te analyseren.
Een visueel zoekmodel zou simpelweg een afbeelding in blokken kunnen verdelen, op elk blok inzoomen en het dan verwerken om het object in kwestie te vinden, maar dat is rekenkundig erg inefficiënt.
Wanneer een tekstuele vraag over een afbeelding wordt gesteld, probeert V* eerst het doelwit direct te lokaliseren. Als dat niet lukt, wordt de MLLM gevraagd op basis van gezond verstand te bepalen in welk deel van de afbeelding het doel zich waarschijnlijk bevindt.
Het richt zijn zoekopdracht dan alleen op dat gebied, in plaats van een "ingezoomde" zoekopdracht uit te voeren op de hele afbeelding.

Wanneer GPT-4V wordt gevraagd om vragen te beantwoorden over een afbeelding die uitgebreide visuele verwerking van high-res afbeeldingen vereist, heeft het het moeilijk. SEAL met V* presteert een stuk beter.

Op de vraag "Wat voor soort drank kunnen we uit die automaat kopen?" antwoordde SEAL "Coca-Cola". antwoordde SEAL "Coca-Cola" terwijl GPT-4V foutief "Pepsi" raadde.
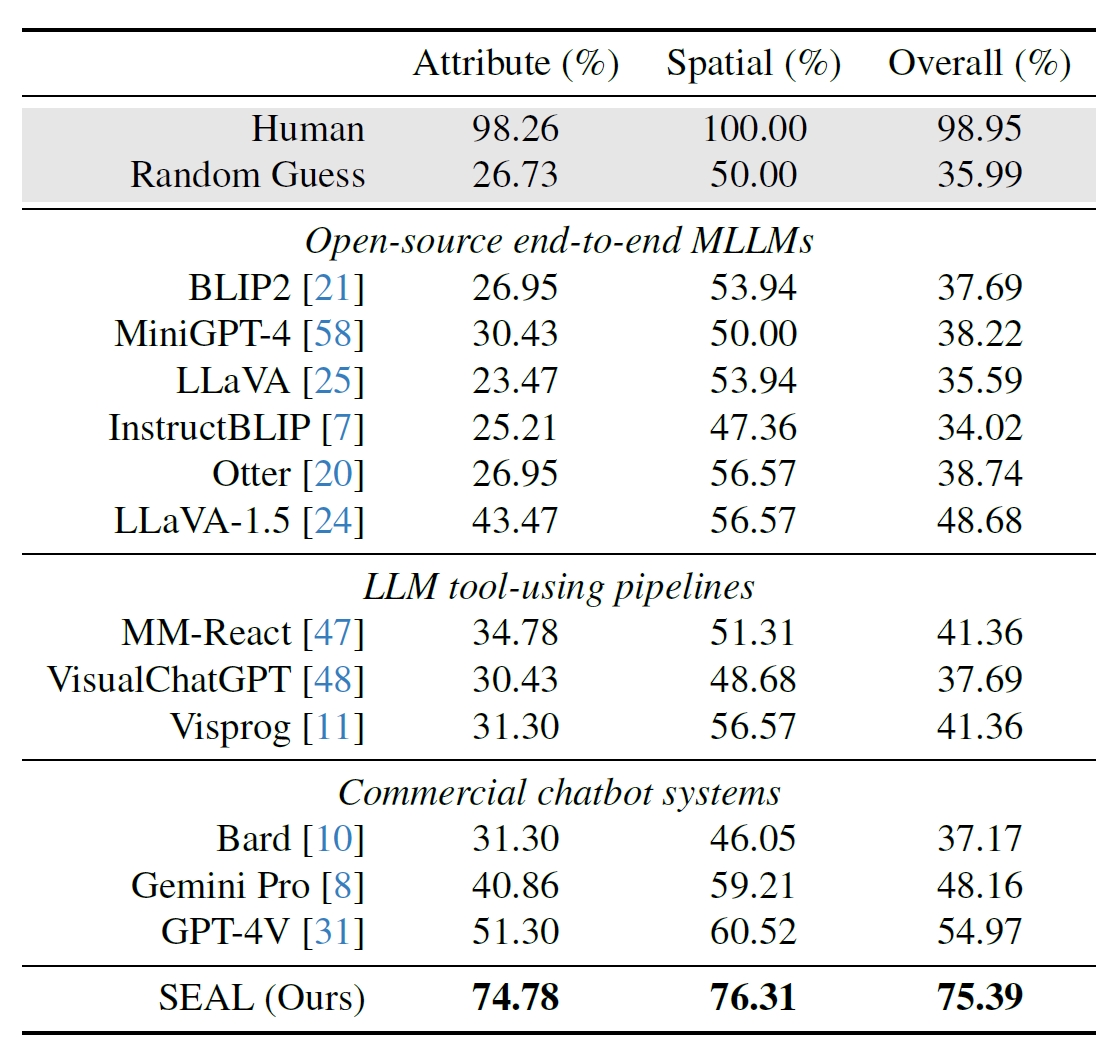
De onderzoekers gebruikten 191 afbeeldingen met een hoge resolutie uit Meta's Segment Anything (SAM) dataset en creëerden een benchmark om te zien hoe de prestaties van SEAL zich verhielden tot andere modellen. De V*Bench benchmark test twee taken: attribuutherkenning en ruimtelijke redenering.
De onderstaande figuren tonen de menselijke prestaties in vergelijking met open-source modellen, commerciële modellen zoals GPT-4V en SEAL. De boost die V* geeft aan de prestaties van SEAL is vooral indrukwekkend omdat de onderliggende MLLM die gebruikt wordt LLaVa-7b is, die een stuk kleiner is dan GPT-4V.
Deze intuïtieve benadering van het analyseren van afbeeldingen lijkt erg goed te werken met een aantal indrukwekkende voorbeelden op de samenvatting op GitHub.
Het zal interessant zijn om te zien of andere MLLM's, zoals die van OpenAI of Google, voor een vergelijkbare aanpak kiezen.
Op de vraag welke drank er werd verkocht uit de automaat op de foto hierboven, antwoordde Google's Bard: "Er staat geen automaat op de voorgrond." Misschien doet Gemini Ultra het beter.
Voorlopig lijkt het erop dat SEAL en zijn nieuwe V*-algoritme de grootste multimodale modellen ver achter zich laten als het gaat om visuele ondervraging.



