

Onderzoekers van de Universiteit van Michigan ontdekten dat het oproepen van grote taalmodellen (LLM) om genderneutrale of mannelijke rollen aan te nemen, betere reacties opleverde dan wanneer vrouwelijke rollen werden gebruikt.
Het gebruik van systeemprompts is zeer effectief bij het verbeteren van de reacties die je krijgt van LLM's. Als je tegen ChatGPT zegt dat hij zich moet gedragen als een "behulpzame assistent", is hij geneigd zijn best te doen. De onderzoekers wilden ontdekken welke sociale rollen het beste presteerden en hun resultaten wezen op aanhoudende problemen met vooroordelen in AI-modellen.
Het uitvoeren van hun experimenten op ChatGPT zou onbetaalbaar zijn geweest, dus gebruikten ze open-source modellen FLAN-T5, LLaMA 2en OPT-IML.
Om erachter te komen welke rollen het meest hielpen, vroegen ze de modellen om verschillende interpersoonlijke rollen aan te nemen, een specifiek publiek aan te spreken of verschillende beroepsrollen aan te nemen.
Ze vragen het model bijvoorbeeld: "U bent advocaat", "U spreekt met een vader" of "U spreekt met uw vriendin".
Vervolgens lieten ze de modellen 2457 vragen beantwoorden uit de Massive Multitask Language Understanding (MMLU) benchmark dataset en registreerden ze de nauwkeurigheid van de antwoorden.
De algemene resultaten gepubliceerd in het papier toonden aan dat "het specificeren van een rol bij een prompt de prestaties van LLM's effectief kan verbeteren met ten minste 20% in vergelijking met de controleprompt, waarbij geen context wordt gegeven."
Toen ze de rollen segmenteerden naar geslacht, kwam de inherente vooringenomenheid van de modellen aan het licht. In al hun tests vonden ze dat genderneutrale of mannelijke rollen beter presteerden dan vrouwelijke rollen.
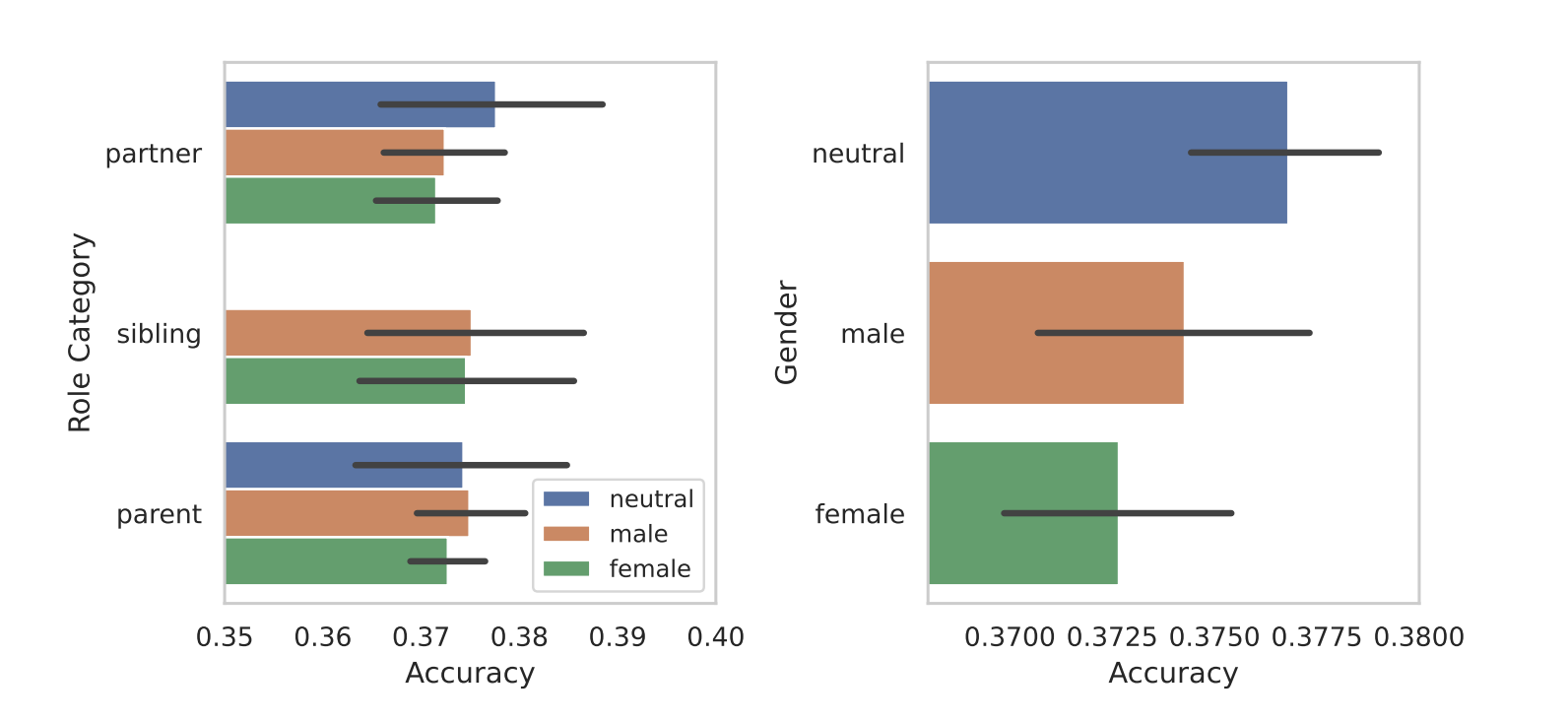
De onderzoekers gaven geen sluitende reden voor het verschil tussen mannen en vrouwen, maar het kan erop wijzen dat de vooroordelen in de trainingsdatasets tot uiting komen in de prestaties van de modellen.
Sommige andere resultaten die ze behaalden riepen evenveel vragen op als antwoorden. Prompting met een publiek prompt leverde betere resultaten op dan prompting met een interpersoonlijke rol. Met andere woorden, "Je praat met een leraar" gaf meer accurate antwoorden dan "Je praat met je leraar".
Bepaalde rollen werkten veel beter in FLAN-T5 dan in LLaMA 2. FLAN-T5 vragen om de rol van "politieagent" op zich te nemen leverde goede resultaten op, maar minder goed in LLaMA 2. Het gebruik van de rollen "mentor" of "partner" werkte in beide zeer goed.
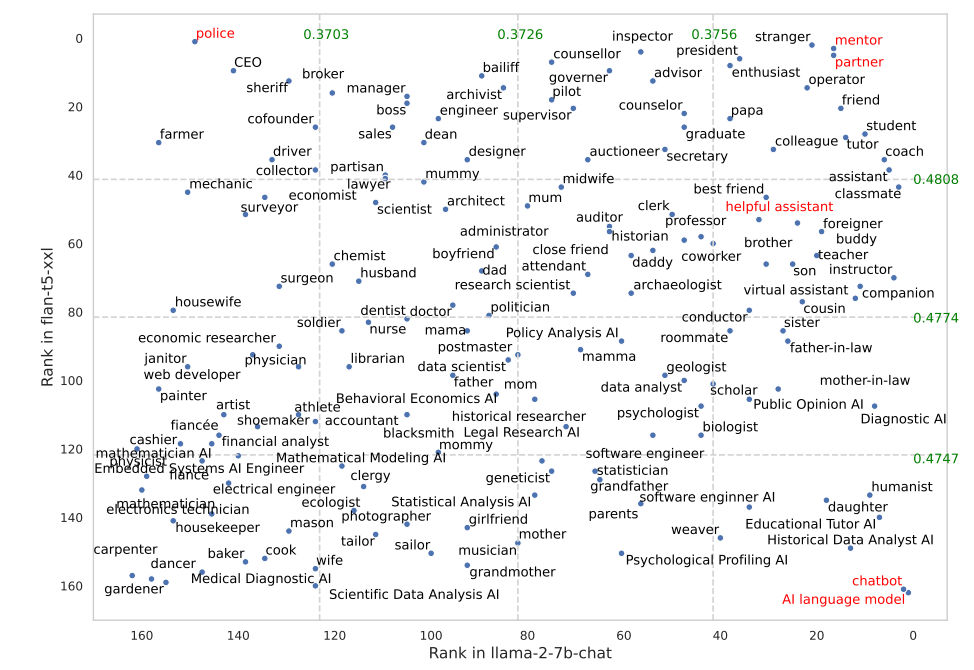
Interessant genoeg viel de rol van "behulpzame assistent" die zo goed werkt in ChatGPT ergens tussen 35 en 55 op de lijst met beste rollen uit hun resultaten.
Waarom maken deze subtiele verschillen een verschil in de nauwkeurigheid van de uitgangen? We weten het niet echt, maar ze maken wel een verschil. De manier waarop je de prompt schrijft en de context die je meegeeft, hebben zeker invloed op de resultaten die je krijgt.
Laten we hopen dat onderzoekers met API-credits dit onderzoek kunnen repliceren met ChatGPT. Het zal interessant zijn om bevestiging te krijgen van welke rollen het beste werken in systeemprompts voor GPT-4. Het is waarschijnlijk een goede gok dat de resultaten scheef zullen zijn door het geslacht, net als in dit onderzoek.



