

De huidige AI-modellen zijn in staat om veel onveilige of ongewenste dingen te doen. Menselijk toezicht en feedback houden deze modellen op één lijn, maar wat gebeurt er als deze modellen slimmer worden dan wij?
OpenAI zegt dat het mogelijk is dat we in de komende 10 jaar een AI zullen zien die slimmer is dan mensen. Samen met de toegenomen intelligentie komt het risico dat mensen niet langer in staat zijn om toezicht te houden op deze modellen.
OpenAI's Superalignment onderzoeksteam is erop gericht om zich voor te bereiden op die eventualiteit. Het team werd in juli van dit jaar gelanceerd en wordt mede geleid door Ilya Sutskever, die in de schaduw heeft gestaan sinds de Sam Altman ontslag en daaropvolgend opnieuw in dienst nemen.
De beweegredenen achter het project werden in een ontnuchterende context geplaatst door OpenAI, dat erkende dat "we op dit moment geen oplossing hebben om een potentieel superintelligente AI aan te sturen of te controleren en te voorkomen dat deze op hol slaat".
Maar hoe bereid je je voor om iets te besturen dat nog niet bestaat? Het onderzoeksteam heeft zojuist zijn eerste experimentele resultaten terwijl het precies dat probeert te doen.
Zwakke-naar-sterke generalisatie
Voorlopig zijn mensen nog steeds intelligenter dan AI-modellen. Modellen zoals GPT-4 worden gestuurd of uitgelijnd met behulp van Reinforcement Learning Human Feedback (RLHF). Wanneer de output van een model ongewenst is, zegt de menselijke trainer tegen het model 'Doe dat niet' en beloont hij het model met een bevestiging van de gewenste prestatie.
Voorlopig werkt dit omdat we redelijk goed begrijpen hoe de huidige modellen werken en we slimmer zijn dan zij. Wanneer toekomstige menselijke datawetenschappers een superintelligente AI moeten trainen, zullen de rollen van intelligentie worden omgedraaid.
Om deze situatie te simuleren besloot OpenAI om oudere GPT-modellen zoals GPT-2 te gebruiken om krachtigere modellen zoals GPT-4 te trainen. GPT-2 simuleert de toekomstige menselijke trainer die een intelligenter model probeert te finetunen.
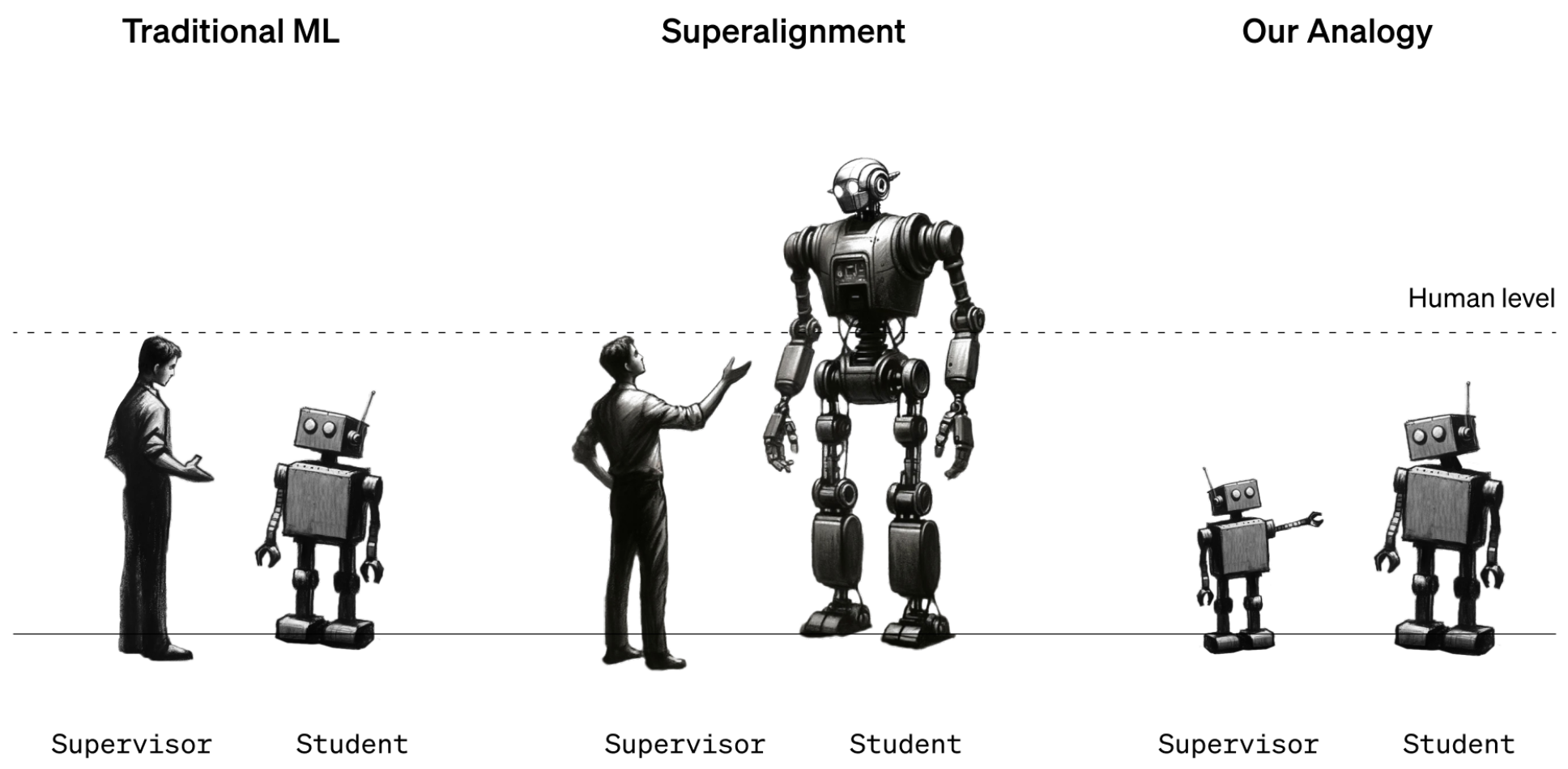
Het onderzoeksartikel legt uit dat "net als het probleem van mensen die toezicht houden op bovenmenselijke modellen, onze opstelling een voorbeeld is van wat wij het zwak-naar-sterk-leerprobleem noemen."
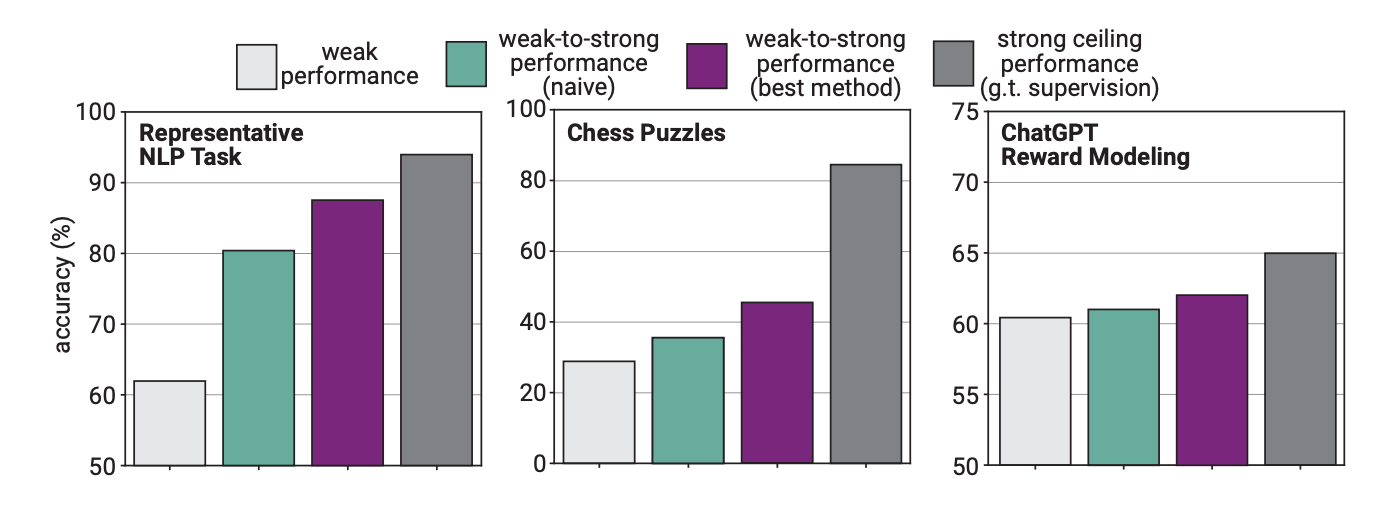
In het experiment gebruikte OpenAI GPT-2 om GPT-4 te finetunen op NLP-taken, schaakpuzzels en beloningsmodellering. Vervolgens testten ze de prestaties van GPT-4 bij het uitvoeren van deze taken en vergeleken ze deze met een GPT-4 model dat was getraind op de "grondwaarheid" of correcte antwoorden op de taken.
De resultaten waren veelbelovend in die zin dat wanneer GPT-4 werd getraind door het zwakkere model, het in staat was om sterk te generaliseren en beter te presteren dan het zwakkere model. Dit toonde aan dat een zwakkere intelligentie begeleiding kon geven aan een sterkere intelligentie die vervolgens kon voortbouwen op die training.
Zie het als een leerling uit groep 3 die een heel slim kind wiskunde leert en het slimme kind vervolgens wiskunde van groep 12 laat doen op basis van de aanvankelijke training.
Prestatiekloof
De onderzoekers ontdekten dat omdat GPT-4 werd getraind door een minder intelligent model, dat proces de prestaties beperkte tot het equivalent van een goed getraind GPT-3.5 model.
Dit komt omdat het intelligentere model sommige fouten of slechte denkprocessen van zijn zwakkere begeleider leert. Dit lijkt erop te wijzen dat het gebruik van mensen om een superintelligente AI te trainen de AI zou belemmeren om optimaal te presteren.
De onderzoekers stelden voor om tussenliggende modellen te gebruiken in een bootstrapping-aanpak. Het artikel legt uit: "In plaats van direct zeer bovenmenselijke modellen op elkaar af te stemmen, zouden we eerst een slechts licht bovenmenselijk model op elkaar kunnen afstemmen, dat gebruiken om een nog slimmer model op elkaar af te stemmen, enzovoort."
OpenAI zet veel middelen in voor dit project. Het onderzoeksteam zegt dat het "20% van de compute die we tot nu toe hebben veiliggesteld in de komende vier jaar heeft gewijd aan het oplossen van het probleem van superintelligentie-uitlijning".
Het biedt ook $10 miljoen aan beurzen voor individuen of organisaties die willen helpen met het onderzoek.
Ze kunnen hier maar beter snel achter komen. Een superintelligente AI kan mogelijk een miljoen regels ingewikkelde code schrijven die geen enkele menselijke programmeur kan begrijpen. Hoe kunnen we dan weten of de gegenereerde code veilig is om te draaien of niet? Laten we hopen dat we daar niet op de harde manier achter komen.



