

Eerder deze maand kondigde Google trots aan dat zijn krachtigste Gemini model GPT-4 versloeg in de Massive Multitask Language Understanding MMLU benchmarktests. Met de nieuwe prompting-techniek van Microsoft herovert GPT-4 de toppositie, zij het met een fractie van een procent.
Naast het drama rond de marketingvideo is Google's Gemini een grote aanwinst voor het bedrijf en zijn de MMLU-benchmarkresultaten indrukwekkend. Maar Microsoft, OpenAI's grootste investeerder, wachtte niet lang om Google's inspanningen in een kwaad daglicht te stellen.
De kop is dat Microsoft GPT-4 de MMLU-resultaten van Gemini Ultra heeft laten verslaan. In werkelijkheid versloeg het Gemini's score van 90.04% met slechts 0.06%.
De achtergronden van wat dit mogelijk heeft gemaakt zijn spannender dan de incrementele one-upmanship die we op deze ranglijsten zien. Microsofts nieuwe prompttechnieken zouden de prestaties van oudere AI-modellen kunnen verbeteren.
Weet je nog hoe Google's nog niet uitgebrachte Gemini Ultra net GPT-4 versloeg om de beste AI te worden?
Nou, Microsoft heeft zojuist aangetoond dat GPT-4, met de juiste aanwijzingen, Gemini verslaat in de benchmarks.
Zelfs bij oudere modellen is er nog veel ruimte voor verbetering. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12 december 2023
Medprompt
Als je mensen hoort spreken over het "sturen" van een model, bedoelen ze alleen dat je met een voorzichtige opdracht een model zo kunt sturen dat het een uitvoer geeft die beter overeenkomt met wat je wilde.
Microsoft ontwikkelde een combinatie van herinneringstechnieken die hier erg goed in bleken te zijn. Medprompt begon als een project om GPT-4 betere antwoorden te laten geven op benchmarks voor medische uitdagingen, zoals de MultiMedQA testsuite.
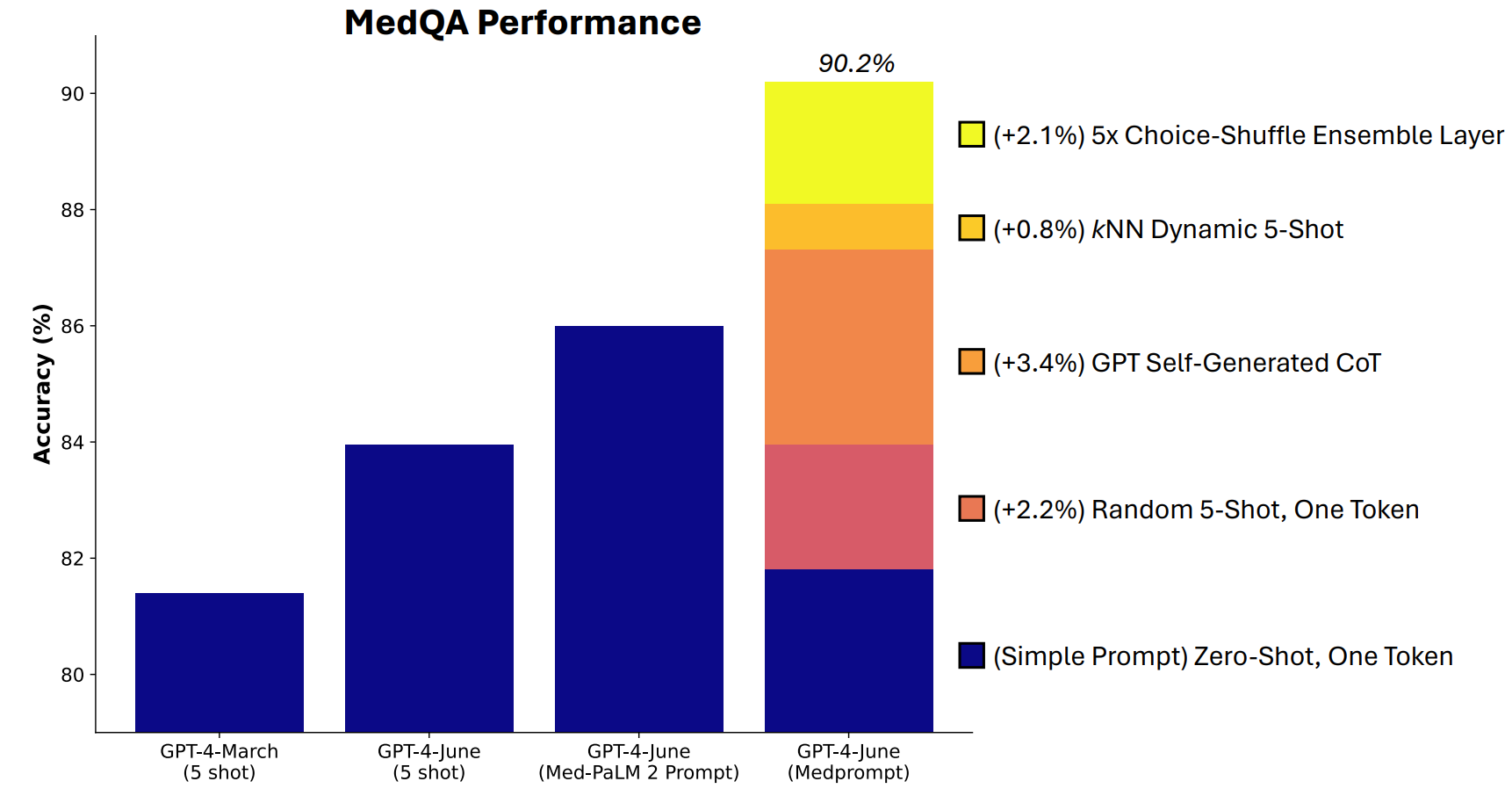
De onderzoekers van Microsoft bedachten dat als Medprompt goed werkte in specialistische medische tests, het ook de generalistische prestaties van GPT-4 zou kunnen verbeteren. En dus kregen Microsoft en OpenAI met GPT-4 weer het recht om op te scheppen ten opzichte van Gemini Ultra.
Hoe werkt Medprompt?
Medprompt is een combinatie van slimme prompttechnieken. Het is gebaseerd op drie hoofdtechnieken.
Dynamisch leren met weinig schotten (DFSL)
"Few-shot learning" verwijst naar het geven van een paar voorbeelden aan GPT-4 voordat je het vraagt om een soortgelijk probleem op te lossen. Als je "5-shot" ziet, betekent dit dat het model 5 voorbeelden heeft gekregen. "Zero-shot' betekent dat het model moest antwoorden zonder voorbeelden.
De Medprompt-paper legde uit dat "omwille van de eenvoud en efficiëntie, de voorbeelden van een paar shots die worden gebruikt bij het vragen om een bepaalde taak meestal vastliggen; ze blijven onveranderd in de verschillende testvoorbeelden".
Het resultaat is dat de voorbeelden die modellen krijgen vaak slechts globaal relevant of representatief zijn.
Als je trainingsset groot genoeg is, kun je het model door alle voorbeelden laten kijken en die voorbeelden kiezen die semantisch lijken op het probleem dat het moet oplossen. Het resultaat is dat de paar voorbeelden die je leert specifieker zijn afgestemd op een bepaald probleem.
Zelfgegenereerde gedachteketen (CoT)
Chain of Thought (CoT) prompting is een geweldige manier om een LLM te sturen. Als je het vraagt met "denk goed na" of "los het stap voor stap op" zijn de resultaten veel beter.
Je kunt veel specifieker zijn in de manier waarop je de gedachtegang van het model stuurt, maar daar komt handmatige prompt engineering bij kijken.
De onderzoekers ontdekten dat ze "GPT-4 simpelweg konden vragen om een gedachteketen te genereren voor de trainingsvoorbeelden." Hun aanpak vertelt GPT-4 in feite: 'Hier is een vraag, de antwoordkeuzen en het juiste antwoord. Welke CoT moeten we opnemen in een prompt die tot dit antwoord zou leiden?
Keuze Shuffle Ensembling
De meeste MMLU benchmarktests zijn meerkeuzevragen. Wanneer een AI-model deze vragen beantwoordt, kan het ten prooi vallen aan positionele bias. Met andere woorden, het kan optie B de voorkeur geven, ook al is dat niet altijd het goede antwoord.
Choice Shuffle Ensembling schudt de posities van de antwoordopties en laat GPT-4 de vraag opnieuw beantwoorden. Dit wordt een aantal keer gedaan, waarna het meest consequent gekozen antwoord wordt geselecteerd als het uiteindelijke antwoord.
Het combineren van deze drie prompt technieken is wat Microsoft de kans gaf om een beetje schaduw te werpen op de resultaten van Gemini. Het zal interessant zijn om te zien welke resultaten Gemini Ultra zou behalen als het een soortgelijke aanpak zou gebruiken.
Medprompt is spannend omdat het laat zien dat oudere modellen nog beter kunnen presteren dan we dachten als we ze op slimme manieren vragen. De extra rekenkracht die nodig is voor deze extra stappen maakt het echter misschien geen haalbare aanpak in de meeste scenario's.



