

Grote taalmodellen (LLM) worden vaak misleid door vertekening of irrelevante context in een prompt. Onderzoekers van Meta hebben een schijnbaar eenvoudige manier gevonden om dat op te lossen.
Naarmate de contextvensters groter worden, kunnen de aanwijzingen die we aan een LLM geven langer en gedetailleerder worden. LLM's zijn beter geworden in het oppikken van de nuances of kleinere details in onze prompts, maar soms kan dit ze verwarren.
In het begin gebruikte machine learning een "harde aandacht" benadering die het meest relevante deel van een input eruit pikte en alleen daarop reageerde. Dit werkt prima als je een afbeelding probeert te ondertitelen, maar slecht bij het vertalen van een zin of het beantwoorden van een vraag met meerdere lagen.
De meeste LLM's gebruiken nu een "zachte aandacht"-benadering die de hele prompt toekent en aan elke prompt een gewicht toekent.
Meta stelt een aanpak voor die Systeem 2 Aandacht (S2A) om het beste van beide werelden te krijgen. S2A maakt gebruik van de natuurlijke taalverwerking van een LLM om je vraag te verwerken en vooroordelen en irrelevante informatie te verwijderen voordat je aan de slag gaat met een antwoord.
Hier is een voorbeeld.

S2A verwijdert de info met betrekking tot Max omdat die irrelevant is voor de vraag. S2A regenereert een geoptimaliseerde prompt voordat er aan wordt gewerkt. LLM's zijn notoir slecht in wiskunde dus het minder verwarrend maken van de prompt is een grote hulp.
LLM's zijn 'people pleasers' en geven je graag gelijk, zelfs als je het mis hebt. S2A verwijdert elke vooringenomenheid in een prompt en verwerkt vervolgens alleen de relevante delen van de prompt. Dit vermindert wat AI-onderzoekers "sycophancy" noemen, of de neiging van een AI-model om te slijmen.

S2A is eigenlijk gewoon een systeemvraag die de LLM instrueert om de oorspronkelijke vraag wat te verfijnen voordat hij ermee aan de slag gaat. De resultaten die de onderzoekers behaalden met wiskundige, feitelijke en lange vragen waren indrukwekkend.
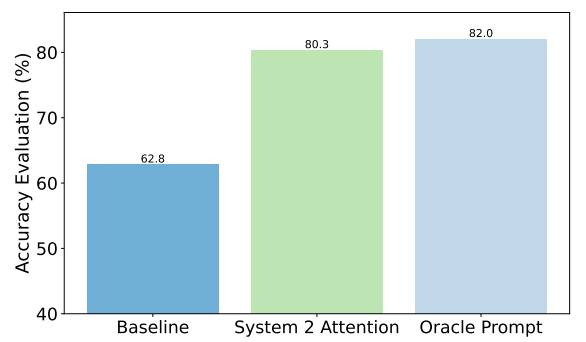
Hier zijn bijvoorbeeld de verbeteringen die S2A behaalde op feitelijke vragen. De basislijn waren antwoorden op vragen die vooringenomenheid bevatten, terwijl de Oracle prompt een door mensen verfijnde ideale prompt was.
S2A komt heel dicht in de buurt van de Oracle prompt resultaten en levert bijna 50% verbetering in nauwkeurigheid ten opzichte van de basislijn prompt.
Dus wat is het addertje onder het gras? Het voorbewerken van de oorspronkelijke prompt voordat deze wordt beantwoord, voegt extra rekenkracht toe aan het proces. Als de prompt lang is en veel relevante informatie bevat, kan het opnieuw genereren van de prompt aanzienlijke kosten met zich meebrengen.
Het is onwaarschijnlijk dat gebruikers beter worden in het schrijven van goed geformuleerde prompts, dus S2A kan een goede manier zijn om dat te omzeilen.
Zal Meta S2A inbouwen in zijn Lama model? We weten het niet, maar je kunt de S2A-aanpak zelf gebruiken.
Als je voorzichtig bent met het weglaten van meningen of leidende suggesties uit je vragen, is de kans groter dat je accurate antwoorden krijgt van deze modellen.



