

Elon Musk kondigde de bètalancering aan van xAI's chatbot Grok en de eerste statistieken geven ons een idee van hoe deze zich verhoudt tot andere modellen.
De Grok chatbot is gebaseerd op xAI's grensverleggende model Grok-1, dat het bedrijf de afgelopen vier maanden heeft ontwikkeld. xAI heeft niet gezegd met hoeveel parameters het is getraind, maar plaagde wel met wat cijfers voor zijn voorganger.
Grok-0, het prototype voor het huidige model, werd getraind op 33 miljard parameters, dus we kunnen waarschijnlijk aannemen dat Grok-1 op minstens evenveel parameters werd getraind.
Dat klinkt niet als veel, maar xAI beweert dat de prestaties van Grok-0 "de mogelijkheden van LLaMA 2 (70B) op standaard LM-benchmarks benaderen", ondanks dat het de helft van de trainingsbronnen gebruikte.
Bij gebrek aan een parametercijfer moeten we het bedrijf op zijn woord geloven wanneer het Grok-1 omschrijft als "state-of-the-art" en dat het "aanzienlijk krachtiger" is dan Grok-0.
Grok-1 werd op de proef gesteld door het te evalueren op deze standaard machine-learning benchmarks:
- GSM8k: Wiskunde woordproblemen op de middelbare school
- MMLU: Multidisciplinaire meerkeuzevragen
- HumanEval: Python-code voltooiingstaak
- MATH: wiskundeproblemen voor middelbare scholen en middelbare scholen, geschreven in LaTeX
Hier is een samenvatting van de resultaten.
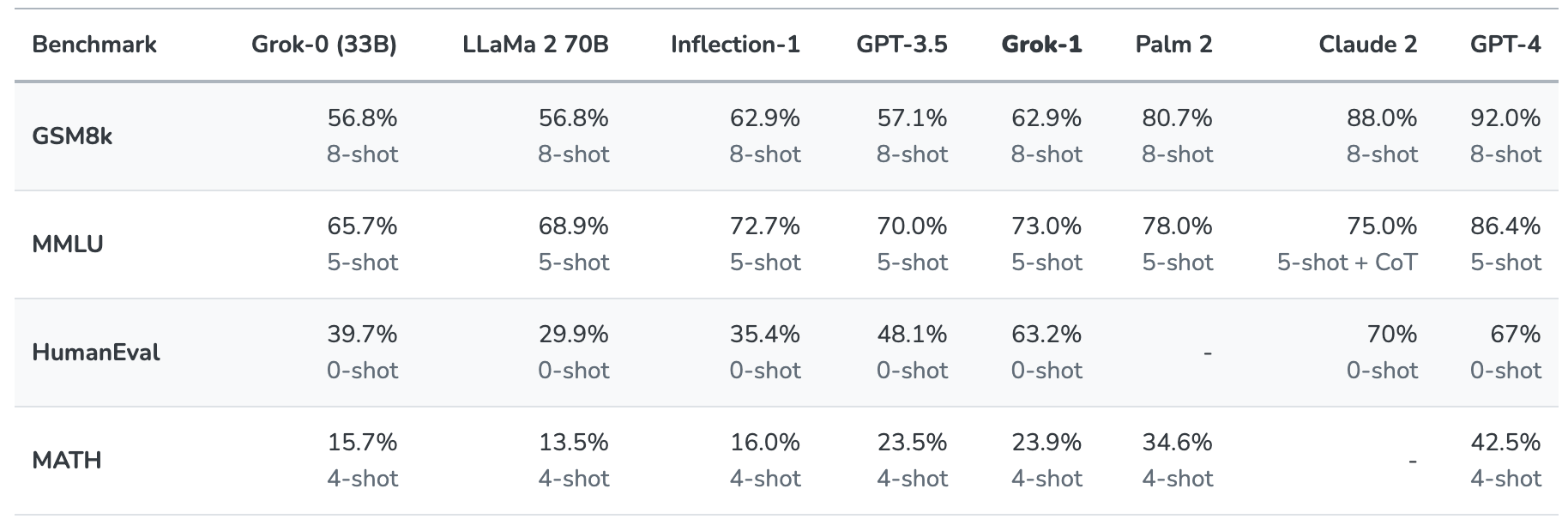
De resultaten zijn interessant omdat ze ons op zijn minst een idee geven van hoe Grok zich verhoudt tot andere frontier-modellen.
xAI zegt dat deze cijfers laten zien dat Grok-1 "alle andere modellen in zijn computerklasse" verslaat en alleen werd verslagen door modellen die waren getraind met een "aanzienlijk grotere hoeveelheid trainingsgegevens en computermiddelen".
GPT-3.5 heeft 175 miljard parameters, dus we kunnen aannemen dat Grok-1 minder dan dat heeft, maar waarschijnlijk meer dan de 33 miljard van zijn prototype.
De Grok chatbot is bedoeld voor taken als het beantwoorden van vragen, het ophalen van informatie, creatief schrijven en hulp bij codering. Hij zal eerder worden gebruikt voor kortere interacties dan super prompt use cases vanwege het kleinere contextvenster.
Met een contextlengte van 8.192 heeft Grok-1 maar de helft van de context die GPT-3.5 heeft. Dit is een indicatie dat xAI Grok-1 waarschijnlijk heeft bedoeld om een langere context in te ruilen voor een betere efficiëntie.
Het bedrijf zegt dat een deel van het huidige onderzoek is gericht op "long-context understanding and retrieval", dus de volgende versie van Grok zou wel eens een groter contextvenster kunnen hebben.
De exacte dataset die werd gebruikt om Grok-1 te trainen is niet duidelijk, maar het bevatte vrijwel zeker jouw tweets op X, en de Grok chatbot heeft ook real-time toegang tot het internet.
We zullen moeten wachten op meer feedback van bètatesters om een goed beeld te krijgen van hoe goed het model eigenlijk is.
Zal Grok ons helpen de mysteries van het leven, het universum en alles te ontrafelen? Misschien nog niet helemaal, maar het is een vermakelijk begin.



