

Digitaal kolonialisme verwijst naar de dominantie van techgiganten en machtige entiteiten over het digitale landschap, waarbij ze de informatie-, kennis- en cultuurstroom vormen om hun belangen te dienen.
Deze dominantie heeft niet alleen te maken met het beheersen van de digitale infrastructuur, maar ook met het beïnvloeden van de verhalen en kennisstructuren die ons digitale tijdperk bepalen.
Digitaal kolonialisme, en nu ook AI-kolonialisme, zijn algemeen erkende termen en instellingen zoals MIT heeft onderzoek gedaan naar en geschreven over ze uitgebreid.
Toponderzoekers van Anthropic, Google, DeepMind en andere techbedrijven hebben openlijk gesproken over de beperkte reikwijdte van AI om mensen met verschillende achtergronden van dienst te zijn, in het bijzonder met betrekking tot bias in systemen voor machinaal leren.
Systemen voor machinaal leren fondamenteel de gegevens weerspiegelen waarop ze zijn getraind - gegevens die cmoet worden gezien als een product van onze digitale tijdgeest - een verzameling van heersende verhalen, beelden en ideeën die de online wereld domineren.
Maar wie krijgt deze informatiekrachten vorm? Wiens stemmen worden versterkt en wiens stemmen worden verzwakt?
Wanneer AI leert van trainingsgegevens, erft het specifieke wereldbeelden die niet noodzakelijkerwijs resoneren met of representatief zijn voor wereldwijde culturen en ervaringen. Bovendien wordt de output van generatieve AI-tools bepaald door onderliggende sociaal-culturele vectoren.
Dit heeft ontwikkelaars als Anthropic ertoe gebracht om democratische methoden zoeken van het vormgeven van AI-gedrag met behulp van publieke standpunten.
Zoals Jack Clark, Anthropic's beleidschef, een recent experiment van zijn bedrijf: "We proberen een manier te vinden om een grondwet te ontwikkelen die ontwikkeld is door een heleboel derde partijen, in plaats van door mensen die toevallig in een lab in San Francisco werken."
De huidige generatieve AI-trainingsparadigma's lopen het risico een digitale echokamer te creëren waar dezelfde ideeën, waarden en perspectieven voortdurend worden versterkt, waardoor de dominantie van degenen die al oververtegenwoordigd zijn in de gegevens, nog verder wordt versterkt.
Naarmate AI zich nestelt in complexe besluitvorming, van sociale zekerheid en werving naar financiële beslissingen en medische diagnoses, scheve vertegenwoordiging leidt tot echte vooroordelen en onrechtvaardigheden.
Datasets zijn geografisch en cultureel gesitueerd
Een recente onderzoek door het Data Provenance Initiative onderzocht 1.800 populaire datasets bedoeld voor natuurlijke taalverwerking (NLP), een discipline van AI die zich richt op taal en tekst.
NLP is de dominante machine learning-methodologie achter grote taalmodellen (LLM's), waaronder ChatGPT en Meta's Llama-modellen.
Het onderzoek onthult een westerse scheefheid in de taalrepresentatie in datasets, waarbij Engels en West-Europese talen de tekstgegevens bepalen.
Talen uit Aziatische, Afrikaanse en Zuid-Amerikaanse landen zijn duidelijk ondervertegenwoordigd.
Als gevolg daarvan kunnen LLM's niet hopen dat ze de cultureel-linguïstische nuances van deze regio's in dezelfde mate accuraat kunnen weergeven als westerse talen.
Zelfs wanneer talen uit het Zuiden vertegenwoordigd lijken, zijn de bron en het dialect van de taal voornamelijk afkomstig van Noord-Amerikaanse of Europese makers en webbronnen.

A vorig Antropisch experiment ontdekten dat het wisselen van taal in modellen zoals ChatGPT nog steeds westers georiënteerde opvattingen en stereotypen in gesprekken opleverde.
Antropische onderzoekers concludeerden: "Als een taalmodel bepaalde meningen disproportioneel vertegenwoordigt, dreigt het potentieel ongewenste effecten op te leggen, zoals het bevorderen van hegemonische wereldbeelden en het homogeniseren van de perspectieven en overtuigingen van mensen."
De Data Provenance studie ontleedde ook het geografische landschap van dataset curatie. Academische organisaties komen naar voren als de primaire drijvende krachten, die bijdragen aan 69% van de datasets, gevolgd door industriële laboratoria (21%) en onderzoeksinstellingen (17%).
De grootste bijdragers zijn AI2 (12,3%), de Universiteit van Washington (8,9%) en Facebook AI Research (8,4%).
A afzonderlijke studie 2020 benadrukt dat de helft van de datasets die zijn gebruikt voor AI-evaluatie in ongeveer 26.000 onderzoeksartikelen afkomstig zijn van slechts 12 topuniversiteiten en techbedrijven.
Opnieuw bleken geografische gebieden zoals Afrika, Zuid- en Midden-Amerika en Centraal-Azië zwaar ondervertegenwoordigd, zoals hieronder te zien is.
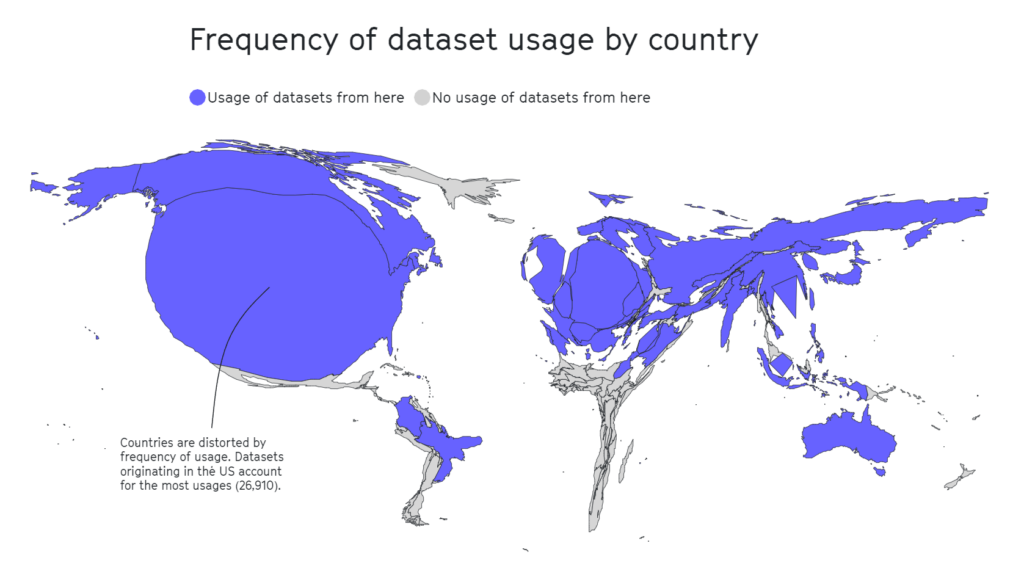
In ander onderzoek bevatten invloedrijke datasets zoals MIT's Tiny Images of Labeled Faces in the Wild voornamelijk blanke westerse mannen, met ongeveer 77,5% mannen en 83,5% blanke individuen in het geval van Labeled Faces in the Wild.
In het geval van Tiny Images is een 2020-analyse door The Register ontdekte dat veel Tiny Images obscene, racistische en seksistische labels bevatten.
Antonio Torralba van MIT zei dat ze niet op de hoogte waren van de labels en dat de dataset werd verwijderd. Torralba zei: "Het is duidelijk dat we ze handmatig hadden moeten screenen."
Engels domineert het AI-ecosysteem
Pascale Fung, computerwetenschapper en directeur van het Center for AI Research aan de Hong Kong University of Science and Technology, besprak de problemen die gepaard gaan met hegemoniale AI.
Fung verwijst naar meer dan 15 onderzoeksartikelen waarin de meertalige vaardigheden van LLM's worden onderzocht en waarin consequent wordt vastgesteld dat ze tekortschieten, met name bij het vertalen van Engels naar andere talen. Zo leggen talen met een niet-Latijns schrift, zoals Koreaans, de beperkingen van LLM's bloot.
Naast de slechte meertalige ondersteuning, andere onderzoeken suggereren dat de meeste benchmarks en maatregelen voor vertekening zijn ontwikkeld met Engelse taalmodellen in gedachten.
Benchmarks voor niet-Engelse bias zijn schaars, wat leidt tot een aanzienlijke kloof in ons vermogen om bias in meertalige taalmodellen te beoordelen en te corrigeren.
Er zijn tekenen van verbetering, zoals de inspanningen van Google met zijn PaLM 2-taalmodel en Meta's Massaal Meertalige Spraak (MMS) dat meer dan 4.000 gesproken talen kan identificeren, 40 keer meer dan andere benaderingen. MMS blijft echter experimenteel.
Onderzoekers creëren diverse meertalige datasets, maar de overweldigende hoeveelheid Engelse tekstgegevens, vaak gratis en gemakkelijk toegankelijk, maakt het de facto de keuze voor ontwikkelaars.
Verder dan gegevens: structurele kwesties in AI-arbeid
MIT's uitgebreide overzicht van AI-kolonialisme vestigde de aandacht op een relatief verborgen aspect van AI-ontwikkeling - uitbuitende arbeidspraktijken.
AI heeft de vraag naar gegevenslabelingdiensten enorm doen toenemen. Bedrijven als Appen en Sama zijn belangrijke spelers geworden en bieden diensten aan voor het taggen van tekst, afbeeldingen en video's, het sorteren van foto's en het transcriberen van audio om modellen voor machinaal leren te voeden.
Menselijke gegevensspecialisten labelen inhoudstypen ook handmatig, vaak om gegevens te sorteren die illegale, ongeoorloofde of onethische inhoud bevatten, zoals beschrijvingen van seksueel misbruik, schadelijk gedrag of andere illegale activiteiten.
Hoewel AI-bedrijven sommige van deze processen automatiseren, is het nog steeds van vitaal belang om 'mensen in de loop' te houden om de nauwkeurigheid van het model en de naleving van de veiligheidsvoorschriften te garanderen.
De marktwaarde van dit "spookwerk", zoals genoemd door antropologe Mary Gray en sociaal wetenschapper Siddharth Suri, wordt geschat op omhoogschieten naar $13,7 miljard in 2030.
Bij spookwerk wordt vaak gebruik gemaakt van goedkope arbeidskrachten, vooral uit economisch kwetsbare landen. Venezuela, bijvoorbeeld, is door de economische crisis een primaire bron van AI-gerelateerde arbeid geworden.
Terwijl het land worstelde met de ergste economische ramp in vredestijd en een astronomische inflatie, wendde een aanzienlijk deel van de goed opgeleide en op internet aangesloten bevolking zich tot crowd-working platforms om te overleven.
De combinatie van een goed opgeleide beroepsbevolking en economische wanhoop maakte van Venezuela een aantrekkelijke markt voor bedrijven die gegevenslabels maken.
Dit is geen controversieel punt - wanneer MIT artikelen publiceert met titels als "Kunstmatige intelligentie creëert een nieuwe koloniale wereldorde," verwijzend naar scenario's als deze, is het duidelijk dat sommigen in de industrie het gordijn van deze achterbakse arbeidspraktijken willen optrekken.
Zoals MIT rapporteert, is de opkomende AI-industrie voor veel Venezolanen een tweesnijdend zwaard geweest. Hoewel het een economische reddingslijn is temidden van wanhoop, stelt het mensen ook bloot aan uitbuiting.
Julian Posada, een promovendus aan de Universiteit van Toronto, benadrukt de "enorme machtsverschillen" in deze werkafspraken. De platforms dicteren de regels, waardoor werknemers weinig te zeggen hebben en een beperkte financiële compensatie ontvangen, ondanks de uitdagingen op het werk zoals blootstelling aan verontrustende inhoud.
Deze dynamiek doet griezelig veel denken aan historische koloniale praktijken waarbij imperia de arbeid van kwetsbare landen uitbuitten, winsten opstreken en hen in de steek lieten zodra de mogelijkheden afnamen, vaak omdat elders 'betere waar' te krijgen was.
Vergelijkbare situaties zijn waargenomen in Nairobi, Kenia, waar een groep voormalige inhoudsmoderatoren die werkten aan ChatGPT een verzoekschrift ingediend met de Keniaanse regering.
Ze beweerden dat er sprake was van "uitbuitende omstandigheden" tijdens hun dienstverband met Sama, een in de VS gevestigd bedrijf voor data annotatiediensten dat onder contract staat bij OpenAI. De indieners beweerden dat ze werden blootgesteld aan verontrustende inhoud zonder adequate psychosociale ondersteuning, wat leidde tot ernstige psychische problemen, waaronder PTSS, depressie en angst.

Documenten beoordeeld door TIME gaf aan dat OpenAI contracten had getekend met Sama ter waarde van ongeveer $200,000. Deze contracten hadden betrekking op het labelen van beschrijvingen van seksueel misbruik, haatzaaiende taal en geweld.
De impact op de geestelijke gezondheid van de werknemers was ingrijpend. Mophat Okinyi, een voormalige moderator, sprak over de psychologische tol en beschreef hoe blootstelling aan grafische inhoud leidde tot paranoia, isolatie en aanzienlijk persoonlijk verlies.
De lonen voor zulk schrijnend werk waren schrikbarend laag - een woordvoerder van Sama onthulde dat arbeiders tussen de $1,46 en $3,74 per uur verdienden.
Verzet tegen digitaal kolonialisme
Als de AI-industrie een nieuwe grens van digitaal kolonialisme is geworden, dan wordt het verzet al samenhangender.
Activisten, vaak gesteund door AI-onderzoekers, pleiten voor verantwoording, beleidsveranderingen en de ontwikkeling van technologieën die prioriteit geven aan de behoeften en rechten van lokale gemeenschappen.
Nanjala Nyabola's Project digitale rechten Kiswahili biedt een innovatief voorbeeld van hoe grassroots projecten op lokale schaal de infrastructuur kunnen installeren die nodig is om gemeenschappen te beschermen tegen digitale hegemonie.
Het project houdt rekening met de hegemonie van westerse regelgeving bij het bepalen van de digitale rechten van een groep, omdat niet iedereen beschermd wordt door de wetten op intellectueel eigendom, auteursrecht en privacy die voor velen van ons vanzelfsprekend zijn. Hierdoor wordt een aanzienlijk deel van de wereldbevolking blootgesteld aan uitbuiting door technologiebedrijven.
Nyabola en haar team erkenden dat discussies over digitale rechten worden afgeremd als mensen niet in hun moedertaal kunnen communiceren, en vertaalden daarom belangrijke termen over digitale rechten en technologie in het Kiswahili, dat voornamelijk wordt gesproken in Tanzania, Kenia en Mozambique.
Nyabola beschreven van het project"Tijdens dat proces [van het Huduma Namba initiatief] hadden we niet echt de taal en de middelen om aan niet-gespecialiseerde of niet-Engelssprekende gemeenschappen in Kenia uit te leggen wat de implicaties van het initiatief waren."
In een soortgelijk grassroots project bezat Te Hiku Media, een non-profit radiostation dat voornamelijk in de Māori taal uitzond, een enorme database aan opnames die tientallen jaren besloegen en waarin vaak de stemmen weerklonken van voorouderlijke zinnen die niet meer gesproken werden.
Mainstream spraakherkenningsmodellen, vergelijkbaar met LLM's, hebben de neiging om te weinig te presteren wanneer er in verschillende talen of Engelse dialecten wordt gevraagd.
De Te Hiku Media werkte samen met onderzoekers en open-source technologieën om een spraakherkenningsmodel te trainen dat op maat gemaakt is voor de Māori taal. Māori activist Te Mihinga Komene droeg zo'n 4.000 zinnen bij aan talloze anderen die deelnamen aan het project.
De resulterend model en gegevens worden beschermd onder de Licentie Kaitiakitanga - Kaitiakitanga is een Māori woord zonder specifieke Engelse definitie, maar lijkt op "voogd" of "bewaarder".
Keoni Mahelona, een medeoprichter van Te Hiku Media, merkte indringend op: "Data is de laatste grens van kolonisatie."
Deze projecten hebben andere inheemse en autochtone gemeenschappen geïnspireerd die onder druk staan van digitaal kolonialisme en andere vormen van sociale onrust, zoals de Mohawk-volkeren in Noord-Amerika en de inheemse Hawaïanen.
Naarmate open-source AI goedkoper en toegankelijker wordt, zou het herhalen en verfijnen van modellen met behulp van unieke gelokaliseerde datasets eenvoudiger moeten worden, waardoor de technologie beter toegankelijk wordt voor verschillende culturen.
Hoewel de AI-industrie nog jong is, is het nu tijd om deze uitdagingen onder de aandacht te brengen zodat mensen gezamenlijk oplossingen kunnen ontwikkelen.
Oplossingen kunnen zowel op macroniveau liggen, in de vorm van regelgeving, beleid en trainingsmethoden voor machinaal leren, als op microniveau, in de vorm van lokale en grassroots projecten.
Samen kunnen onderzoekers, activisten en lokale gemeenschappen methoden vinden om ervoor te zorgen dat AI iedereen ten goede komt.



