

Onderzoekers hebben FANToM geïntroduceerd, een nieuwe benchmark die is ontworpen om het begrip en de toepassing van Theory of Mind (ToM) van grote taalmodellen (LLM's) rigoureus te testen en te evalueren.
Theory of Mind verwijst naar het vermogen om overtuigingen, verlangens en kennis toe te schrijven aan jezelf en anderen, en te begrijpen dat anderen overtuigingen en perspectieven hebben die verschillen van de eigen overtuigingen en perspectieven.
ToM wordt gezien als de basis van het bewustzijn dat intelligente dieren bezitten. Naast mensen worden primaten zoals orang-oetangs, gorilla's en chimpansees beschouwd als dieren met ToM, evenals sommige niet-primaten zoals papegaaien en leden van de familie van de kauwachtigen (kraaien).
Nu AI-modellen complexer worden, zijn AI-onderzoekers op zoek naar nieuwe methoden om vaardigheden zoals ToM te evalueren.
Een nieuwe benchmark genaamd FANToM, gemaakt door onderzoekers van het Allen Institute for AI, de Universiteit van Washington, de Carnegie Mellon University en de Seoul National University, onderwerpt modellen voor machinaal leren aan dynamische scenario's die levensechte interacties weerspiegelen.
In FANToM gaan personages gesprekken aan en weer uit, waardoor AI-modellen worden uitgedaagd om nauwkeurig bij te houden wie wat weet op een bepaald moment.
Het onderwerpen van grote taalmodellen (LLM's) aan FANToM liet zien dat zelfs de meest geavanceerde modellen moeite hebben met het handhaven van een consistente ToM.
De prestaties van de modellen waren significant lager dan die van menselijke deelnemers, wat de beperkingen van AI benadrukt bij het begrijpen van en navigeren door complexe sociale interacties.
In feite domineerden mensen elke categorie, zoals hieronder te zien is.
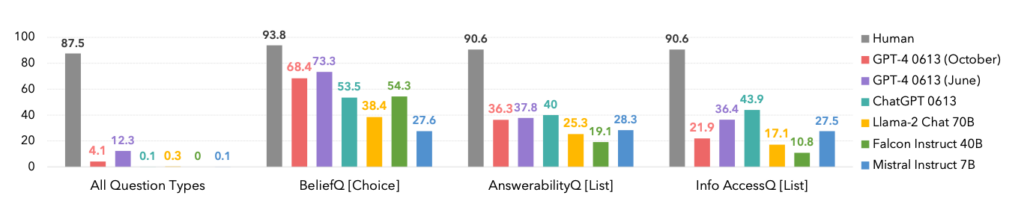
Een interessante bijkomstigheid is dat de oktoberversie van de GPT-4 model iteratie beter presteerde dan een eerdere juni, wat recente anekdotes onder gebruikers zou kunnen bevestigen dat ChatGPT wordt slechter.
FANToM onthulde ook technieken om LLM ToM te verbeteren, zoals chain-of-thought redeneringen en andere fine-tuning methoden.
De kloof tussen AI en menselijke ToM-vaardigheden blijft echter groot.
AI maakt sprong naar mensachtige taalvaardigheid
In een enigszins verwante maar afzonderlijke studie gepubliceerd in Natureontwikkelden wetenschappers een neuraal netwerk dat in staat is om taal te generaliseren zoals mensen dat doen.
Dit nieuwe neurale netwerk toonde een indrukwekkend vermogen om nieuw geleerde woorden te integreren in zijn bestaande woordenschat. Het kon deze woorden vervolgens in verschillende contexten gebruiken, een cognitieve vaardigheid die bekend staat als systematische generalisatie.
Mensen vertonen van nature systematische generalisatie en nemen nieuwe woordenschat naadloos op in hun repertoire.
Als iemand bijvoorbeeld eenmaal de term 'photobomb' kent, kan hij of zij deze vrijwel onmiddellijk toepassen in verschillende situaties. Er duikt voortdurend nieuw jargon op en mensen nemen het op natuurlijke wijze op in hun woordenschat.
De onderzoekers onderwierpen zowel hun eigen aangepaste neurale netwerk als ChatGPT aan een reeks tests en ontdekten dat ChatGPT qua prestaties achterbleef bij het aangepaste model.
Hoewel LLM's zoals ChatGPT uitblinken in veel gespreksscenario's, vertonen ze opvallende inconsistenties en hiaten in andere, een probleem dat dit nieuwe neurale netwerk aanpakt.
Om dit aspect van linguïstische communicatie te onderzoeken, voerden onderzoekers een experiment uit met 25 menselijke deelnemers om hun vermogen om nieuw geleerde woorden toe te passen in verschillende contexten te beoordelen. De proefpersonen maakten kennis met een pseudotaal die bestond uit onzinwoorden die verschillende acties en regels voorstelden.
Na een trainingsfase blonken de deelnemers uit in het toepassen van deze abstracte regels op nieuwe situaties.
Toen het nieuw ontwikkelde neurale netwerk werd blootgesteld aan deze taak, weerspiegelde het de menselijke prestaties. Toen ChatGPT echter aan dezelfde uitdaging werd onderworpen, had het aanzienlijk meer moeite en faalde het tussen 42 en 86% van de tijd, afhankelijk van de specifieke taak.
Dit is om twee redenen belangrijk. Ten eerste zou je kunnen stellen dat dit nieuwe neurale netwerk het beter deed dan GPT-4 in deze specifieke taak - wat al indrukwekkend genoeg is. Ten tweede legt dit onderzoek nieuwe methoden bloot om AI-modellen te leren nieuwe taal te generaliseren zoals mensen.
Zoals Elia Bruni, een specialist in natuurlijke taalverwerking aan de Universiteit van Osnabrück in Duitsland, beschrijft: "Systematiek in neurale netwerken inbouwen is een hele klus."
Samen bieden deze twee onderzoeken nieuwe benaderingen voor het trainen van intelligentere AI-modellen die kunnen wedijveren met mensen op cruciale gebieden zoals taalkunde en Theory of Mind.



