
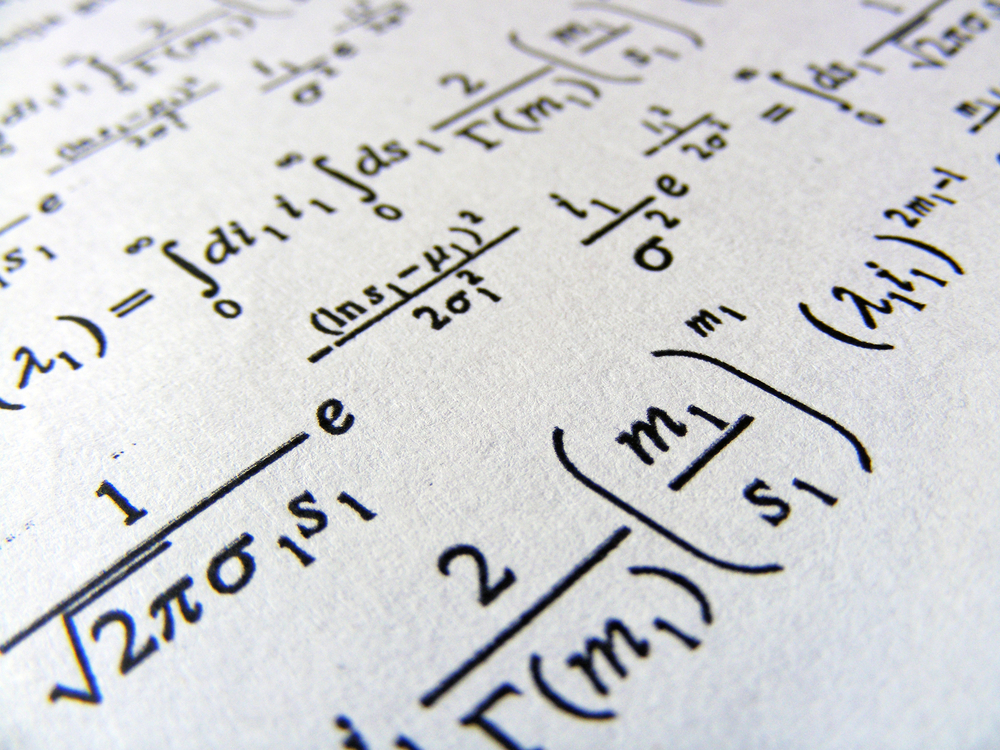
Meta heeft een nieuw AI-model ontwikkeld, Nougat genaamd, dat wetenschappelijke tekst betrouwbaar kan omzetten in machineleesbare tekst.
Als je ooit hebt geprobeerd om een wetenschappelijk onderzoekspaper te lezen, dan begin je te begrijpen waarom het moeilijk is om het elektronisch te verwerken. De huidige OCR-tools (Optical Character Recognition) analyseren tekst regel voor regel.
Dat is prima voor puur tekstgebaseerde documenten, maar wetenschappelijke papers voegen een niveau van complexiteit toe waar deze standaardtools niet mee om kunnen gaan.
Wetenschappelijke documenten bevatten wiskundige en wetenschappelijke symbolen en formules die vaak worden toegevoegd als subscript of superscript. Zelfs de beste OCR's hebben moeite om deze goed vast te leggen.
Wat het nog uitdagender maakt, is dat veel van deze onderzoekspapers slecht gescand zijn en de originelen niet meer beschikbaar zijn. Nougat, wat staat voor Neural Optical Understanding for Academic Documents, gaat de uitdaging aan.
In plaats van regel voor regel te scannen, verwerkt Nougat de hele pagina met behulp van een variant van Meta's Vision Transformer voor beeldanalyse. Het model werd getraind op een dataset van artikelen gepubliceerd op PubMed Central en arXiv met bijbehorende LaTeX broncode.
LaTeX is software die wordt gebruikt om wetenschappelijke papers te schrijven die complexe formules en wiskundige symbolen vereisen. Het model werd getraind door naar de afbeelding van de paper te kijken en deze te vergelijken met de code die de complexe tekst genereerde.
Hier is een voorbeeld van een van Meta's experimenten met het digitaliseren van een oud onderzoekspapier.

Bron: Meta
Er staan nog meer indrukwekkende voorbeelden op de Facebook Onderzoekspagina.
Nougat is niet perfect, maar het behaalde nog steeds een BLEU-score van meer dan 91% en een nauwkeurigheid van meer dan 96% met doorlopende tekst. De BLEU-score meet de gelijkenis van de machinaal vertaalde tekst met een reeks hoogwaardige referentievertalingen.
Voor formules en tabellen deed het het iets slechter met een nauwkeurigheid van iets meer dan 75%. Dat is nog steeds een stuk beter dan concurrerende modellen zoals GROBID die het slechts 11% van de tijd bij het juiste eind heeft.
Er zijn miljoenen pagina's onderzoek die niet indexeerbaar of doorzoekbaar zijn omdat ze alleen effectief door mensen gelezen kunnen worden. Nougat verandert dat door zelfs slecht gescande onderzoeks-PDF's om te zetten in machinaal leesbare tekst.
Net als veel van zijn andere nieuwe tools, heeft Meta ook deze vrij toegankelijk gemaakt. beschikbaar op GitHub. Er kan echter een zeker eigenbelang meespelen in deze ontwikkeling. Zodra oude onderzoekspapers machinaal leesbaar zijn, komen ze beschikbaar voor het trainen van andere AI-modellen.
Het zal interessant zijn om te zien welke lang verloren gewaande onderzoeksjuweeltjes worden herontdekt met Nougat.



