

Luke Farritor, en 21 år gammel informatikkstudent fra University of Nebraska-Lincoln, har avslørt teksten i en karbonisert skriftrull fra antikkens Herculaneum.
Denne rullen har vært uleselig siden vulkanutbruddet i år 79 e.Kr. som også oppslukte Pompeii. Farritors maskinlæringsalgoritme klarte å finne greske bokstaver på den sammenrullede papyrusen, inkludert ordet πορϕυρας (porphyras), som betyr "purpur".
Teknikken hans gikk ut på å identifisere små, nyanserte forskjeller i overflatestruktur for å trene opp det nevrale nettverket til å oppdage blekk, og dermed leterring.
"Da jeg så det første bildet, ble jeg sjokkert." sa Federica Nicolardi, papyrolog fra universitetet i Napoli. "Det var en drøm", fortsetter hun, "jeg kan faktisk se noe fra innsiden av en skriftrull."
Rullene, som ble begravd av Vesuvs utbrudd i år 79 e.Kr., har stort sett vært utilgjengelige på grunn av deres skjøre tilstand.
Når de forkullede rullene rulles ut manuelt, flasser de fra hverandre, og de lærde fryktet at innholdet ville forbli et mysterium for alltid.

Som Nicolardi forklarte: "Dette er så sprø gjenstander. De er krøllete og knuste."
I erkjennelsen av utfordringen med å tyde skriftrullene, ble Vesuvius-utfordringen ble opprettet, med ulike priser, blant annet en hovedpremie på US$700 000 for å dechiffrere flere passasjer fra en skriftrull.
Den 12. oktober ble det kunngjort at Farritor hadde vunnet en premie på $40 000 for å ha identifisert over 10 tegn i et lite utsnitt av papyrusen.
En annen deltaker, Youssef Nader fra Freie Universität Berlin, mottok $10 000 for andreplassen.
Historikeren Thea Sommerschield, som forsker på antikkens Hellas og Roma, beskriver det som "ekstremt spennende" å endelig kunne skjelne bokstaver og ord inne i rullene.
Sommerschield nevnte at tolkningen av disse kan "revolusjonere vår kunnskap om antikkens historie og litteratur" fra regionen.
Det er ikke første gang forskere har forsøkt å lese disse gamle karboniserte rullene. I 2019 forsøkte Brent Seales, professor i informatikk som spesialiserer seg på virtuell lesing og bevaring av gamle skriftruller, å "pakke opp" rullene virtuelt ved hjelp av røntgentomografi (CT).
I 2016 lyktes Seales med et gammelt hebraisk pergament som ble funnet i 1970 i Ein Gedi i Israel, og som avslørte deler av Tredje Mosebok.
Herculaneum-rullene bød imidlertid på en annen utfordring: Blekket, som var laget av kull og vann, skilte seg ikke ut i skanningene.
Det var her Farritor lyktes ved å fokusere på en bestemt subtil tekstur, kalt "crackle", for spor av blekk.
Farritor sier: "Jeg hoppet opp og ned", etter at algoritmen hans avslørte fem bokstaver fra et nylig utgitt segment. "Herregud, dette kommer faktisk til å fungere", innså han.
Kort tid etter videreutviklet han modellen sin og identifiserte de ti bokstavene som krevdes for prisen, og ordet "purpur" var ikke tidligere identifisert i Herculaneum-rullene.
Hovedpremien i Vesuvius Challenge er ennå ikke offentliggjort, og fristen er satt til 31. desember.
AI for avkoding av gamle språk
For seks årtusener siden bosatte sumererne seg i Mesopotamia, landet som strekker seg over elvene Tigris og Eufrat.
Denne regionen, som dekker dagens Irak, Kuwait, Tyrkia og Syria, var vitne til utviklingen fra små jordbrukssamfunn til store urbane sivilisasjoner. Byer som Uruk blomstret opp, med intrikate kanaler, vanningsanlegg og styringssentra. Det var en avgjørende tid for menneskehetens fremgang og utvikling.
Sumererne skrev med en skrift som kalles kileskrift. Dette skriftsystemet krevde at man presset siv inn i leire, noe som genererte komplekse logo-syllabiske inskripsjoner. Kileskrift er ikke et språk - det er en skrift som omfatter rundt 15 språk gjennom tre årtusener.

Kileskriften ble først og fremst brukt som et administrativt verktøy, for eksempel til å registrere husdyr og transaksjoner, men rundt 2700 f.Kr. oppstod det en lang rekke mer filosofiske og kreative skrifter.
Et av de mest bemerkelsesverdige av disse skriftene er Gilgamesj-eposetsom strekker seg over tolv tavler.
Enrique Jiménez fra Ludwig-Maximilians-universitetet i München sier: "Halvparten av menneskehetens historie ligger innkapslet i disse kileskrifttavlene."
Imidlertid er det bare 75 personer, i henhold til New Scientistkan dekode kileskrift til tross for titusenvis av uoversatte tavler verden over.
Maskinlæring hjelper nå forskere med å nøste opp i historiene som er risset inn i steintavlene, og hjelper dem med å fylle hull og ordne tekstene kronologisk for å finne ut mer om hvordan de gamle sumererne levde.
Maskinlæringens rolle i dekryptering av eldgammel tekst
Enrique Jiménez og teamet hans grunnla Elektronisk babylonsk litteratur, et samarbeid mellom arkeologer, dataforskere og historikere.
For å analysere kileskrifttavlene brukte teamet en maskinlæringsteknikk som opprinnelig ble utviklet for sammenligning av gensekvenser. Denne AI-en forutsier innholdet i manglende seksjoner og grensene der fragmentene stemmer overens.
Denne teknikken førte til oppdagelser som manglende deler av Gilgamesj-eposet og en nyoppdaget mesopotamisk sjanger som beskriver pedagogiske parodier og vitser for barn.
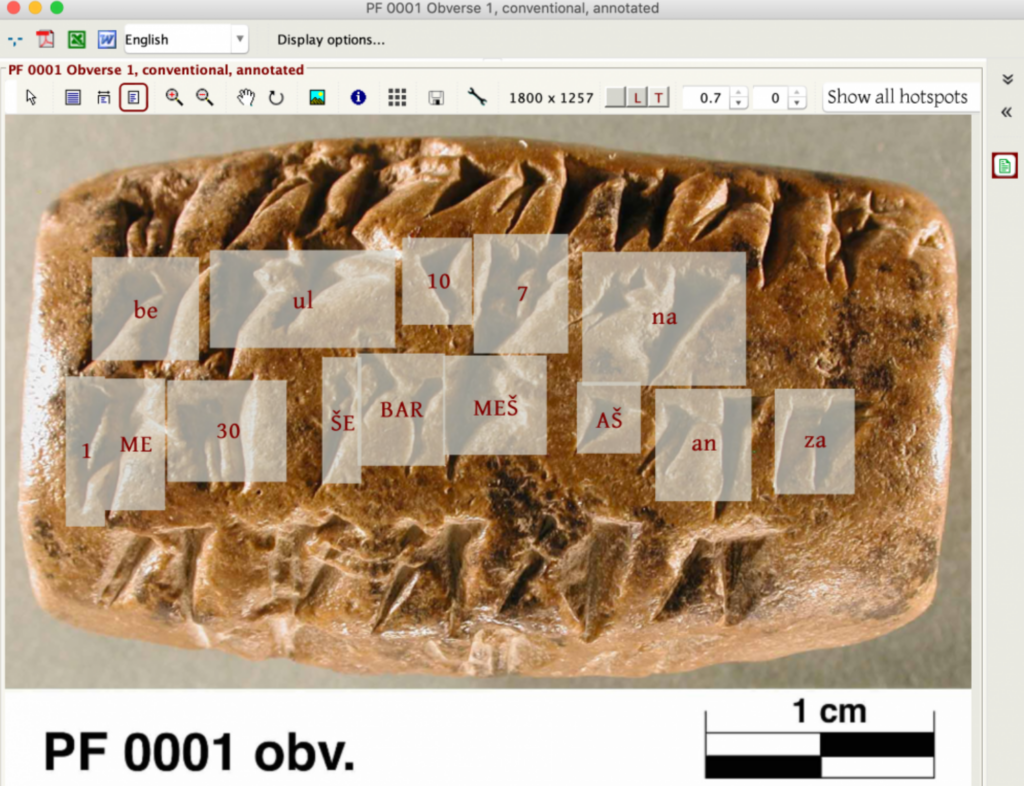
I 2020, en egen modell, DeepScribeble trent på 6000 annoterte bilder fra Persepolis befestningsarkiv, som spesifiserer omtrent 100 000 symboler fra det elamittiske språket (fra dagens Iran), datert rundt 500 f.Kr.
Ved hjelp av ressurser fra UChicago Research Computing Center har Krishnan og Eddie Williams trent opp en modell som er i stand til å dekode disse tegnene med en imponerende nøyaktighet på 80%.
Teamet har til hensikt å utvikle DeepScribe til et allsidig dechiffreringsverktøy som kan omskoleres til andre språk enn elamitt.
DeepMind har også undersøkt avkoding av eldgamle språk ved hjelp av maskinlæring - i dette tilfellet ødelagte antikke greske tavler.
Navngitt IthacaDenne modellen gjenopprettet tekster med 72% presisjon, anslo deres alder med tre tiårs nøyaktighet og antydet til og med deres opprinnelse med 71% nøyaktighet.

Ithacas opplæring omfattet 60 000 tekster fra 700 f.Kr. til 500 e.Kr. som var merket med data om tid og sted i 84 antikke territorier.
Møtet mellom eldgamle tekster og banebrytende kunstig intelligens viser at selv årtusengamle mysterier ikke er immune mot fremskritt innen moderne teknologi.
Ved å blande det gamle med det nye, tar forskerne både vare på historien og kartlegger tidligere ukjente arkeologisk kunnskap.
Disse gjennombruddene understreker de ubegrensede mulighetene som finnes når vi forener menneskelig nysgjerrighet med teknologisk dyktighet, og viser at det finnes en ny måte å betrakte vår kollektive fortids underverker på.



{kind=link}