
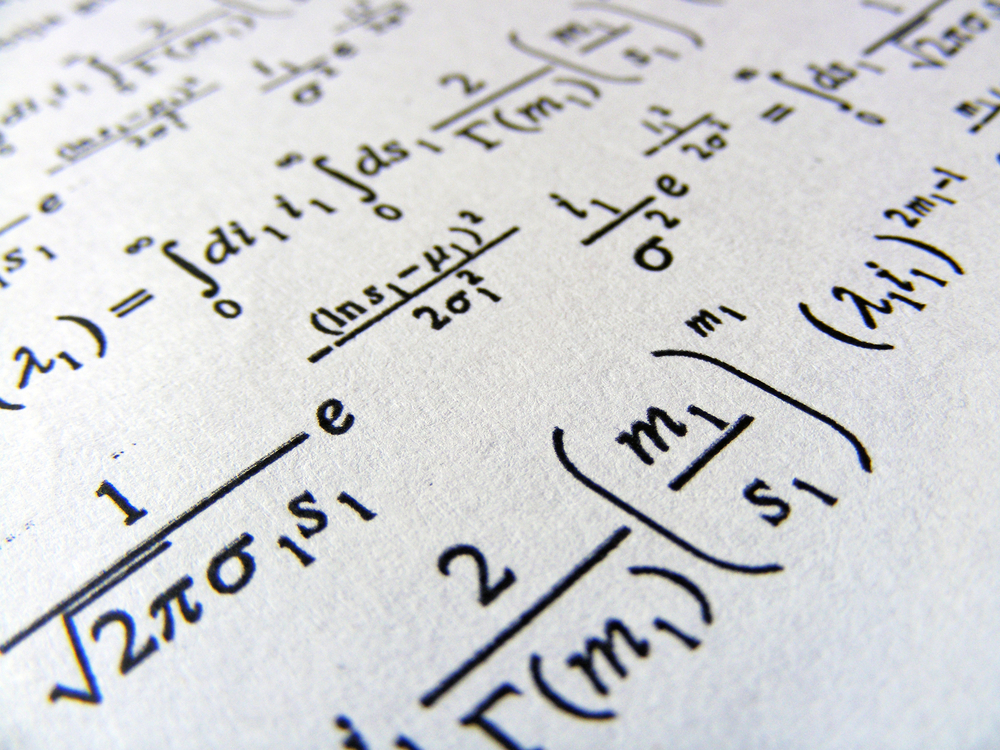
Meta har utviklet en ny AI-modell kalt Nougat, som på en pålitelig måte kan gjøre vitenskapelig tekst om til maskinlesbar tekst.
Hvis du noen gang har prøvd å lese en vitenskapelig forskningsartikkel, skjønner du hvorfor det er vanskelig å behandle den elektronisk. Dagens OCR-verktøy (Optical Character Recognition) analyserer tekst linje for linje.
Det er greit nok for rent tekstbaserte dokumenter, men vitenskapelige artikler tilfører et nivå av kompleksitet som disse standardverktøyene ikke kan håndtere.
Vitenskapelige artikler inneholder matematiske og vitenskapelige symboler og formler som ofte er lagt til som subskript eller superscript. Selv de beste OCR-programmene har problemer med å fange opp disse på riktig måte.
Det som gjør det enda mer utfordrende, er at mange av disse forskningsartiklene er dårlig skannet, og at originalene ikke lenger er tilgjengelige. Nougat, som står for Neural Optical Understanding for Academic Documents, er klar for utfordringen.
I stedet for å skanne linje for linje behandler Nougat hele siden ved hjelp av en variant av Meta's Vision Transformer for bildeanalyse. Modellen ble trent opp på et datasett med artikler publisert på PubMed Central og arXiv som hadde tilsvarende LaTeX-kildekode.
LaTeX er en programvare som brukes til å skrive vitenskapelige artikler som krever komplekse formler og matematiske symboler. Modellen ble trent opp ved å se på bildet av artikkelen og sammenligne det med koden som genererte den komplekse teksten.
Her er et eksempel på et av Metas eksperimenter med å digitalisere en gammel forskningsartikkel.

Kilde: Meta
Det finnes flere imponerende eksempler på Forskningsside på Facebook.
Nougat er ikke perfekt, men den oppnådde likevel en BLEU-poengsum på over 91% og en nøyaktighet på over 96% med sammenhengende tekst. BLEU-poengsummen måler likheten mellom den maskinoversatte teksten og et sett med referanseoversettelser av høy kvalitet.
For formler og tabeller gikk det litt dårligere med en nøyaktighet på drøyt 75%. Det er likevel mye bedre enn konkurrerende modeller som GROBID, som bare klarer å treffe riktig 11% av gangene.
Det finnes millioner av forskningssider som ikke kan indekseres eller søkes i, fordi de bare kan leses effektivt av mennesker. Nougat endrer dette ved å gjøre det mulig å konvertere selv dårlig skannede forsknings-PDF-er til maskinlesbar tekst.
Som med så mange av de andre nye verktøyene, har Meta gjort dette fritt tilgjengelig tilgjengelig på GitHub. Det kan imidlertid være en viss grad av egeninteresse i denne utviklingen. Når gamle forskningsartikler er maskinlesbare, blir de tilgjengelige for opplæring av andre AI-modeller.
Det blir interessant å se hvilke for lengst tapte forskningsperler som gjenoppdages ved hjelp av Nougat.



