

OpenAI lanserte ingen nye modeller på Dev Day-arrangementet, men nye API-funksjoner vil begeistre utviklere som ønsker å bruke modellene deres til å bygge kraftige apper.
OpenAI har hatt noen tøffe uker, og selskapets teknologidirektør, Mira Murati, og andre ledende forskere har sluttet seg til den stadig voksende listen over tidligere ansatte. Selskapet er under økende press fra andre flaggskipmodeller, inkludert modeller med åpen kildekode, som tilbyr utviklere billigere og svært effektive alternativer.
De nye funksjonene OpenAI presenterte, var Realtime API (i betaversjon), finjustering av synet og effektivitetsøkende verktøy som hurtigbufring og modelldestillasjon.
API i sanntid
Realtime API er den mest spennende nye funksjonen, om enn i betaversjon. Den gjør det mulig for utviklere å bygge tale-til-tale-opplevelser med lav latenstid i appene sine uten å bruke separate modeller for talegjenkjenning og tekst-til-tale-konvertering.
Med dette API-et kan utviklere nå lage apper som muliggjør sanntidssamtaler med kunstig intelligens, for eksempel stemmeassistenter eller språklæringsverktøy, alt gjennom ett enkelt API-anrop. Det er ikke helt den sømløse opplevelsen som GPT-4os Advanced Voice Mode tilbyr, men det er i nærheten.
Den er imidlertid ikke billig, med en pris på ca. $0,06 per minutt med lydinngang og $0,24 per minutt med lydutgang.
Det nye sanntids-API-et fra OpenAI ...er utrolig...
Se den bestille 400 jordbær ved å faktisk RINGE butikken med twillio. Alt med stemmen. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1. oktober 2024
Finjustering av synet
Med visuell finjustering i API-et kan utviklere forbedre modellenes evne til å forstå og samhandle med bilder. Ved å finjustere GPT-4o ved hjelp av bilder kan utviklere lage applikasjoner som utmerker seg i oppgaver som visuelt søk eller objektdeteksjon.
Denne funksjonen utnyttes allerede av selskaper som Grab, som har forbedret nøyaktigheten til karttjenesten sin ved å finjustere modellen for å gjenkjenne trafikkskilt fra bilder på gatenivå.
OpenAI ga også et eksempel på hvordan GPT-4o kunne generere tilleggsinnhold til et nettsted etter å ha blitt finjustert slik at det stilmessig samsvarte med nettstedets eksisterende innhold.
Be om hurtigbufring
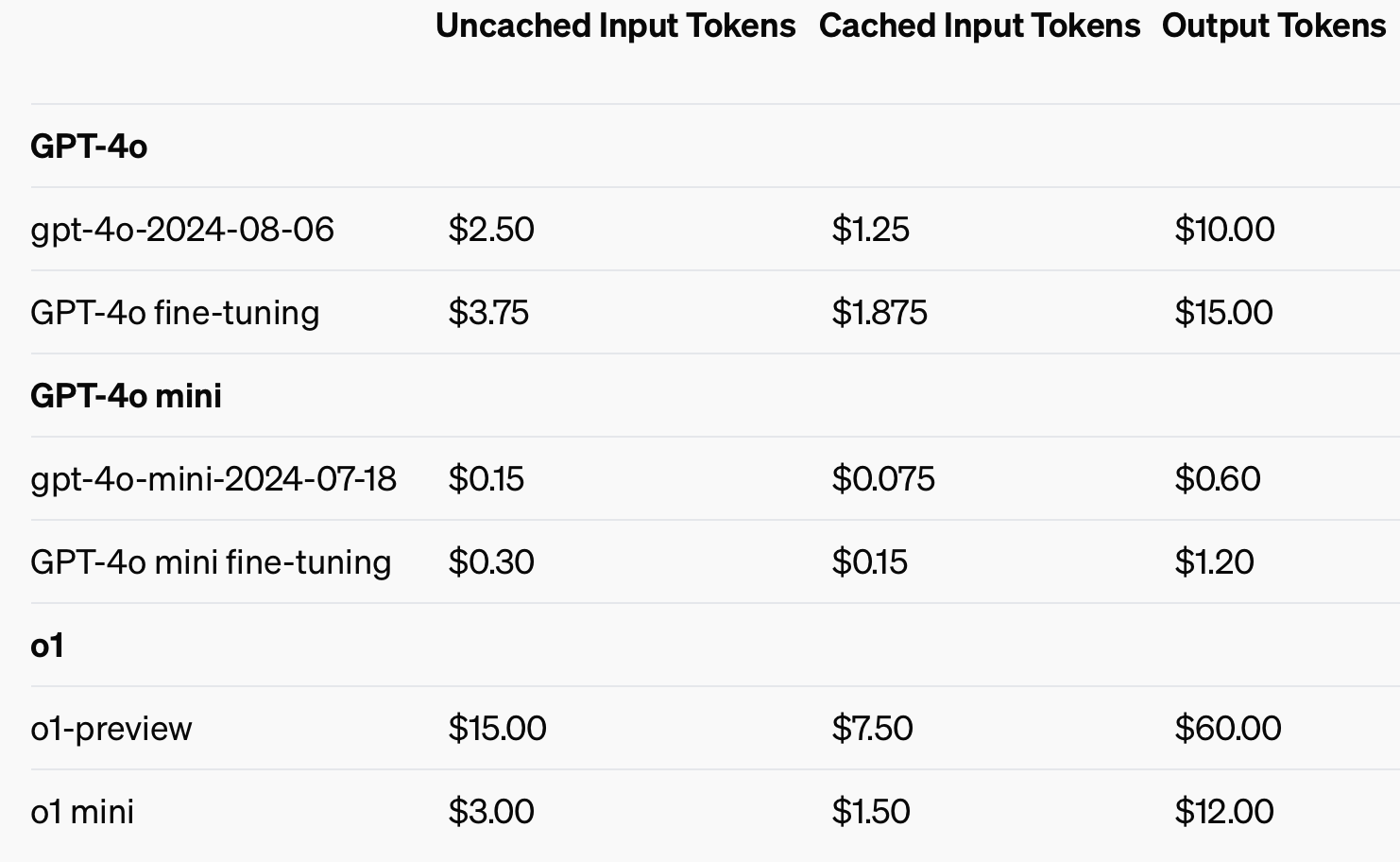
For å forbedre kostnadseffektiviteten introduserte OpenAI hurtigbufring, et verktøy som reduserer kostnadene og ventetiden for API-anrop som brukes ofte. Ved å gjenbruke nylig behandlede inndata kan utviklere kutte kostnadene med 50% og redusere responstidene. Denne funksjonen er spesielt nyttig for applikasjoner som krever lange samtaler eller gjentatte kontekster, for eksempel chatboter og kundeserviceverktøy.
Ved å bruke hurtigbufrede inndata kan man spare opptil 50% i kostnader for inndatatoken.
Modell destillasjon
Modelldestillasjon gjør det mulig for utviklere å finjustere mindre, mer kostnadseffektive modeller ved hjelp av resultatene fra større, mer kapable modeller. Dette er en game-changer, fordi destillasjon tidligere krevde flere frakoblede trinn og verktøy, noe som gjorde det til en tidkrevende og feilutsatt prosess.
Før OpenAIs integrerte Model Distillation-funksjon måtte utviklere manuelt orkestrere ulike deler av prosessen, som å generere data fra større modeller, forberede finjusterte datasett og måle ytelsen med ulike verktøy.
Utviklere kan nå automatisk lagre utdatapar fra større modeller som GPT-4o og bruke disse parene til å finjustere mindre modeller som GPT-4o-mini. Hele prosessen med å opprette datasett, finjustere og evaluere kan gjøres på en mer strukturert, automatisert og effektiv måte.
Den strømlinjeformede utviklerprosessen, lavere ventetid og reduserte kostnader vil gjøre OpenAIs GPT-4o-modell til et attraktivt alternativ for utviklere som ønsker å distribuere kraftige apper raskt. Det blir interessant å se hvilke applikasjoner de multimodale funksjonene muliggjør.



