

HyperWrite-grunnlegger og administrerende direktør Matt Shumer kunngjorde at hans nye modell, Reflection 70B, bruker et enkelt triks for å løse LLM-hallusinasjoner og leverer imponerende referanseresultater som slår større og til og med lukkede modeller som GPT-4o.
Shumer samarbeidet med leverandøren av syntetiske data, Glaive, for å lage den nye modellen, som er basert på Metas Llama 3.1-70B Instruct-modell.
I lanseringsannonsen på Hugging Face sa Shumer. "Reflection Llama-3.1 70B er (for øyeblikket) verdens beste LLM med åpen kildekode, trent med en ny teknikk kalt Reflection-Tuning som lærer en LLM å oppdage feil i resonnementet sitt og korrigere kursen."
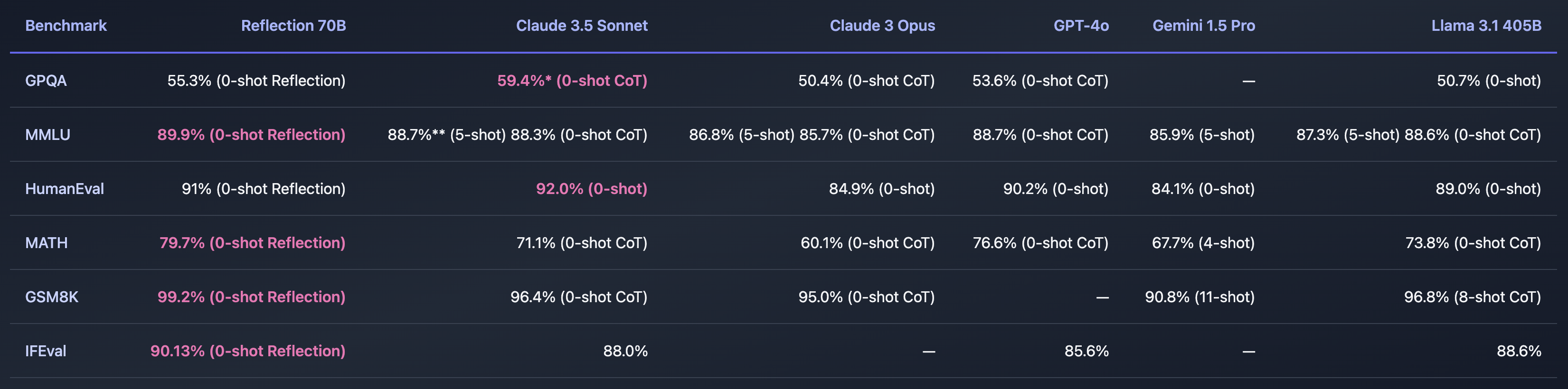
Hvis Shumer fant en måte å løse problemet med AI-hallusinasjoner på, ville det være utrolig. Referanseverdiene han delte ser ut til å indikere at Reflection 70B ligger langt foran andre modeller.
Modellens navn henspiller på dens evne til å korrigere seg selv under slutningsprosessen. Shumer røper ikke for mye, men forklarer at modellen reflekterer over det opprinnelige svaret på en ledetekst, og at den bare sender ut svaret når den er overbevist om at det er riktig.
Shumer forteller at en 405B-versjon av Reflection er på trappene, og at den vil blåse andre modeller, inkludert GPT-4o, av banen når den presenteres neste uke.
Er Reflection 70B en svindel?
Er alt dette for godt til å være sant? Reflection 70B er tilgjengelig for nedlasting på Huging Face, men de første testerne klarte ikke å duplisere den imponerende ytelsen som Shumers benchmarks viste.
Den Lekeplass for refleksjon lar deg prøve modellen, men sier at demoen er midlertidig nede på grunn av stor etterspørsel. Forslagene "Tell r-er i jordbær" og "9,11 vs. 9,9" antyder at modellen svarer riktig på disse vanskelige spørsmålene. Men noen brukere hevder at Reflection er innstilt spesielt for å svare på disse spørsmålene.
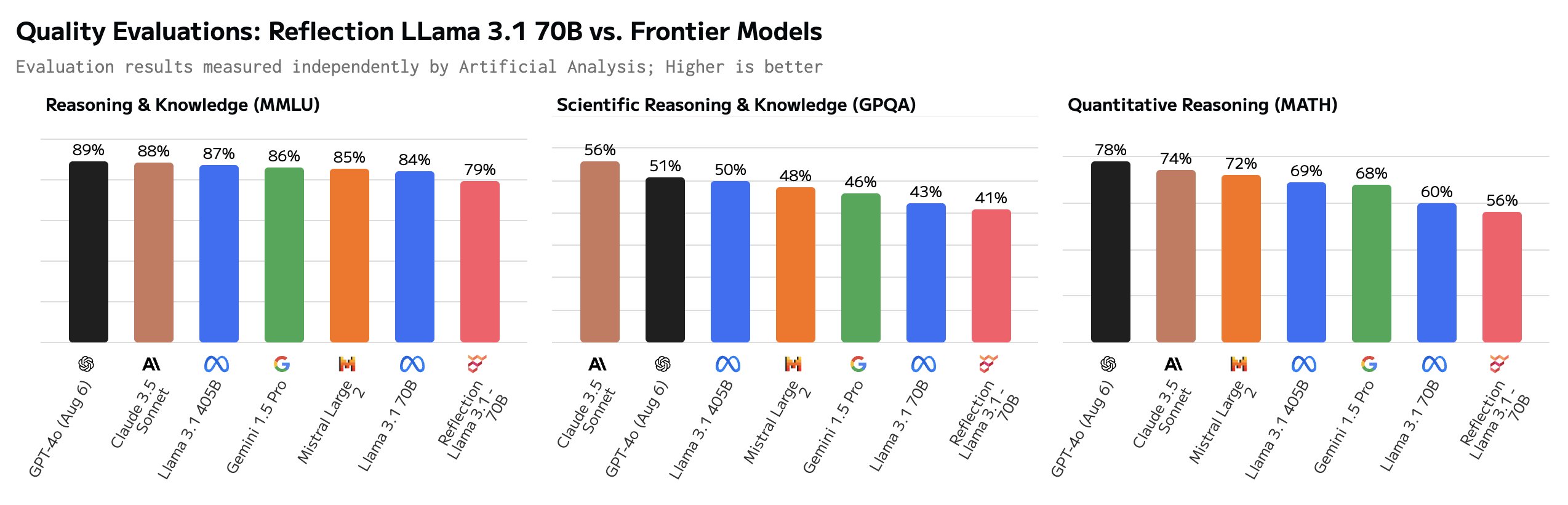
Noen brukere satte spørsmålstegn ved de imponerende referansene. GSM8K på over 99% så spesielt mistenkelig ut.
Hei, Matt! Dette er superinteressant, men jeg er ganske overrasket over å se en GSM8k-poengsum på over 99%. Min forståelse er at det er sannsynlig at mer enn 1% av GSM8k er feilmerket (det riktige svaret er faktisk feil)!
- Hugh Zhang (@hughbzhang) 5. september 2024
Noen av de riktige svarene i GSM8K-datasettet er faktisk feil. Med andre ord var den eneste måten å oppnå høyere poengsum enn 99% på GSM8K å gi de samme feilaktige svarene på disse oppgavene.
Etter å ha testet Reflection, sier brukerne at den faktisk er dårligere enn Llama 3.1, og at den egentlig bare var Llama 3 med LoRA-tuning.
Som svar på den negative tilbakemeldingen la Shumer ut en forklaring på X og sa: "Rask oppdatering - vi lastet opp vektene på nytt, men det er fortsatt et problem. Vi har nettopp begynt å trene på nytt for å eliminere eventuelle problemer. Burde være ferdig snart."
Shumer forklarte at det var en feil med API-et, og at de jobbet med saken. I mellomtiden ga han tilgang til et hemmelig, privat API, slik at tvilere kunne prøve Reflection mens de jobbet med å fikse feilen.
Og det er her hjulene ser ut til å løsne, ettersom en forsiktig spørring ser ut til å vise at API-et egentlig bare er en Claude 3.5 Sonnet-innpakning.
"Reflection API" er en Sonnet 3.5 wrapper med prompt. Og de skjuler den for øyeblikket ved å filtrere bort strengen "claude".https://t.co/c4Oj8Y3Ol1 https://t.co/k0ECeo9a4i pic.twitter.com/jTm2Q85Q7b
- Joseph (@RealJosephus) 8. september 2024
Etterfølgende tester skal ha vist at API-et returnerte resultater fra Llama og GPT-4o. Shumer insisterer på at de opprinnelige resultatene er nøyaktige, og at de jobber med å fikse den nedlastbare modellen.
Er skeptikerne litt for tidlig ute med å kalle Shumer en svindler? Kanskje lanseringen bare var dårlig håndtert, og Reflection 70B virkelig er en banebrytende åpen kildekode-modell. Eller kanskje det er nok et eksempel på AI-hype for å skaffe risikokapital fra investorer som leter etter den neste store tingen innen AI.
Vi må vente en dag eller to for å se hvordan dette utvikler seg.



