

Benchmarks sliter med å holde tritt med utviklingen av AI-modeller, og prosjektet Humanity's Last Exam ønsker din hjelp til å løse dette problemet.
Prosjektet er et samarbeid mellom Center for AI Safety (CAIS) og AI-dataselskapet Scale AI. Prosjektet har som mål å måle hvor nær vi er å oppnå AI-systemer på ekspertnivå, noe eksisterende referanseverdier ikke er i stand til.
OpenAI og CAIS utviklet den populære MMLU-referansen (Massive Multitask Language Understanding) i 2021. På den tiden, sier CAIS, "presterte AI-systemer ikke bedre enn tilfeldig."
Den imponerende ytelsen til OpenAIs o1-modell har "knust de mest populære resonneringsbenchmarkene", ifølge Dan Hendrycks, administrerende direktør i CAIS.
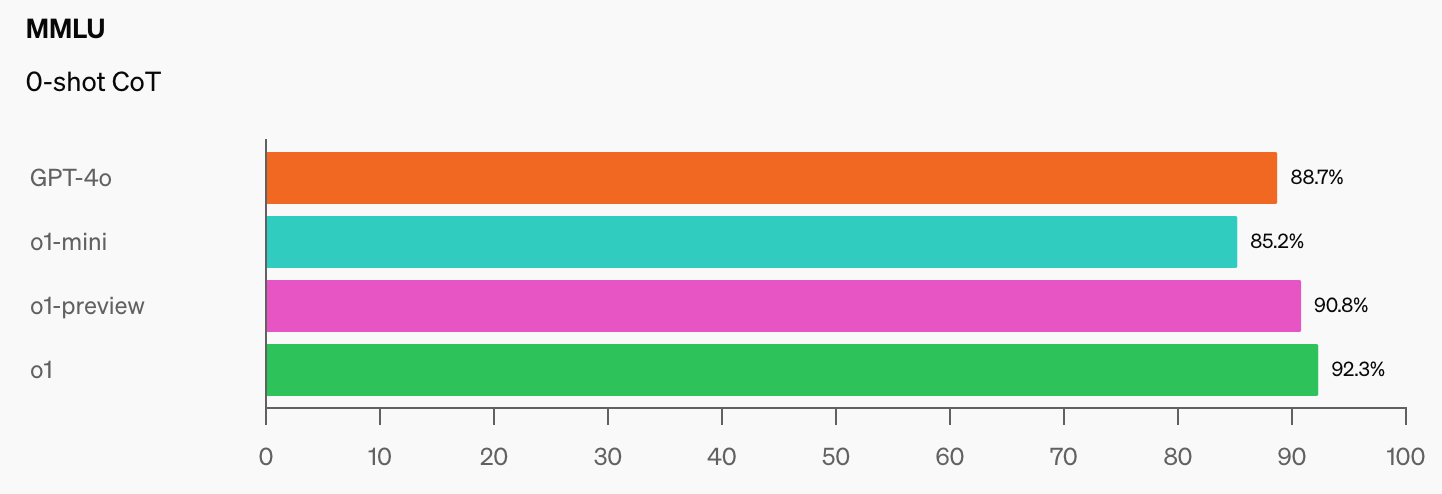
Når AI-modeller når 100% på MMLU, hvordan skal vi da måle dem? CAIS sier: "Eksisterende tester er nå blitt for enkle, og vi kan ikke lenger følge AI-utviklingen på en god måte, eller hvor langt de er fra å bli ekspertnivå."
Når du ser hoppet i referanseverdiene som o1 har lagt til de allerede imponerende GPT-4o-tallene, vil det ikke ta lang tid før en AI-modell vinner MMLU.
Dette er objektivt sett sant. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17. september 2024
Humanity's Last Exam ber folk sende inn spørsmål som virkelig ville overrasket deg hvis en AI-modell leverte det riktige svaret. De vil ha eksamensspørsmål på doktorgradsnivå, ikke spørsmål av typen "hvor mange R-er er det i jordbær", som noen modeller sliter med.
Scale forklarte at "Etter hvert som de eksisterende testene blir for enkle, mister vi evnen til å skille mellom AI-systemer som kan klare seg på eksamen, og de som virkelig kan bidra til nyskapende forskning og problemløsning."
Hvis du har et originalt spørsmål som kan overraske en avansert AI-modell, kan du få navnet ditt lagt til som medforfatter av prosjektets artikkel og ta del i en pott på $500 000 som vil bli tildelt de beste spørsmålene.
For å gi deg en idé om hvilket nivå prosjektet sikter mot, forklarte Scale at "hvis en tilfeldig utvalgt student kan forstå det som blir spurt om, er det sannsynligvis for enkelt for dagens og morgendagens ferske LLM-er."
Det er noen interessante begrensninger på hva slags spørsmål som kan sendes inn. De vil ikke ha noe som er relatert til kjemiske, biologiske, radiologiske eller kjernefysiske våpen, eller cybervåpen som brukes til å angripe kritisk infrastruktur.
Hvis du tror du har et spørsmål som oppfyller kravene, kan du sende det inn her.



