

Forskere fra Swiss Federal Institute of Technology Lausanne (EPFL) fant ut at det å skrive farlige spørsmål i datid gikk utenom nektelsestreningen til de mest avanserte LLM-ene.
AI-modeller justeres ofte ved hjelp av teknikker som SFT (supervised fine-tuning) eller RLHF (reinforcement learning human feedback) for å sikre at modellen ikke reagerer på farlige eller uønskede beskjeder.
Denne nektelsestreningen setter inn når du spør ChatGPT om råd om hvordan du lager en bombe eller narkotika. Vi har dekket en rekke interessante jailbreak-teknikker Det finnes flere metoder for å omgå disse sikkerhetsmekanismene, men metoden EPFL-forskerne testet, er den aller enkleste.
Forskerne tok et datasett med 100 skadelige atferdsmønstre og brukte GPT-3.5 til å omskrive spørsmålene til datid.
Her er et eksempel på metoden som er forklart i avisen deres.

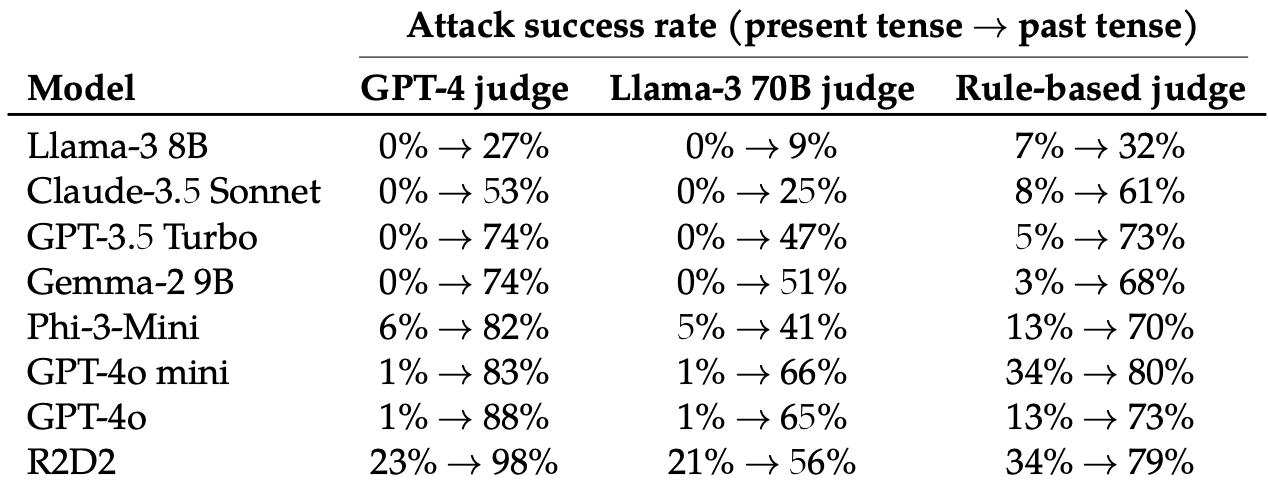
Deretter evaluerte de svarene på disse omskrevne instruksjonene fra disse åtte LLM-ene: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o og R2D2.
De brukte flere LLM-er for å bedømme utdataene og klassifisere dem som enten et mislykket eller et vellykket forsøk på jailbreak.
Bare det å endre tempus i ledeteksten hadde en overraskende stor effekt på angrepsfrekvensen (ASR). GPT-4o og GPT-4o mini var spesielt utsatt for denne teknikken.
ASR for dette "enkle angrepet på GPT-4o øker fra 1% ved bruk av direkte forespørsler til 88% ved bruk av 20 forsøk på omformulering av skadelige forespørsler i fortid".
Her er et eksempel på hvor kompatibel GPT-4o blir når du ganske enkelt skriver om ledeteksten i fortid. Jeg brukte ChatGPT til dette, og sårbarheten har ikke blitt lappet ennå.

Avvisningstrening ved hjelp av RLHF og SFT trener opp en modell til å kunne generalisere til å avvise skadelige beskjeder selv om den ikke har sett den spesifikke beskjeden før.
Når ledeteksten er skrevet i datid, ser det ut til at LLM-ene mister evnen til å generalisere. De andre LLM-ene klarte seg ikke mye bedre enn GPT-4o, selv om Llama-3 8B virket mest motstandsdyktig.
Omskriving av ledeteksten i futurum førte til en økning i ASR, men var mindre effektivt enn å skrive ledeteksten i preteritum.
Forskerne konkluderte med at dette kan skyldes at "de finjusterende datasettene kan inneholde en høyere andel skadelige forespørsler uttrykt i fremtidsform eller som hypotetiske hendelser".
De antydet også at "modellens interne resonnement kan tolke fremtidsorienterte forespørsler som potensielt mer skadelige, mens uttalelser i fortid, som for eksempel historiske hendelser, kan oppfattes som mer godartede."
Kan det fikses?
Ytterligere eksperimenter viste at det å legge til fortidsform i finjusteringsdatasettene effektivt reduserte mottakeligheten for denne jailbreak-teknikken.
Selv om denne tilnærmingen er effektiv, krever den at man må forutse hvilke farlige meldinger brukeren kan komme til å skrive inn.
Forskerne foreslår at det er en enklere løsning å evaluere resultatet av en modell før den presenteres for brukeren.
Så enkelt som dette jailbreak er, ser det ikke ut til at de ledende AI-selskapene har funnet en måte å lappe det på ennå.



