

Google DeepMind-forskere har utviklet NATURAL PLAN, en referanse for å evaluere LLM-enes evne til å planlegge oppgaver i den virkelige verden basert på naturlige språkmeldinger.
Den neste utviklingen av AI er å få den til å forlate en chat-plattform og ta på seg agentroller for å fullføre oppgaver på tvers av plattformer på våre vegne. Men det er vanskeligere enn det høres ut.
Planleggingsoppgaver som å avtale et møte eller sette sammen en reiserute kan virke enkle for oss. Vi mennesker er flinke til å resonnere oss gjennom flere trinn og forutsi om et handlingsforløp vil føre til at vi når det ønskede målet eller ikke.
Det er kanskje enkelt, men selv de beste AI-modellene sliter med planlegging. Kan vi sammenligne dem for å se hvilken LLM som er best til å planlegge?
NATURAL PLAN-referansen tester LLM-er på tre planleggingsoppgaver:
- Planlegging av reisen - Planlegging av en reiserute med begrensninger knyttet til fly og reisemål
- Planlegging av møter - Planlegging av møter med flere venner på forskjellige steder
- Kalenderplanlegging - Planlegging av arbeidsmøter mellom flere personer ut fra eksisterende tidsplaner og ulike begrensninger
Eksperimentet begynte med noen få spørsmål, der modellene fikk fem eksempler på spørsmål med tilhørende riktige svar. Deretter ble de bedt om å planlegge oppgaver av varierende vanskelighetsgrad.
Her er et eksempel på en ledetekst og en løsning som er gitt som eksempel til modellene:

Resultater
Forskerne testet GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, og Gemini 1,5 Proingen av dem gjorde det særlig bra på disse testene.
Resultatene må ha falt i god jord på DeepMind-kontoret, for Gemini 1.5 Pro gikk av med seieren.

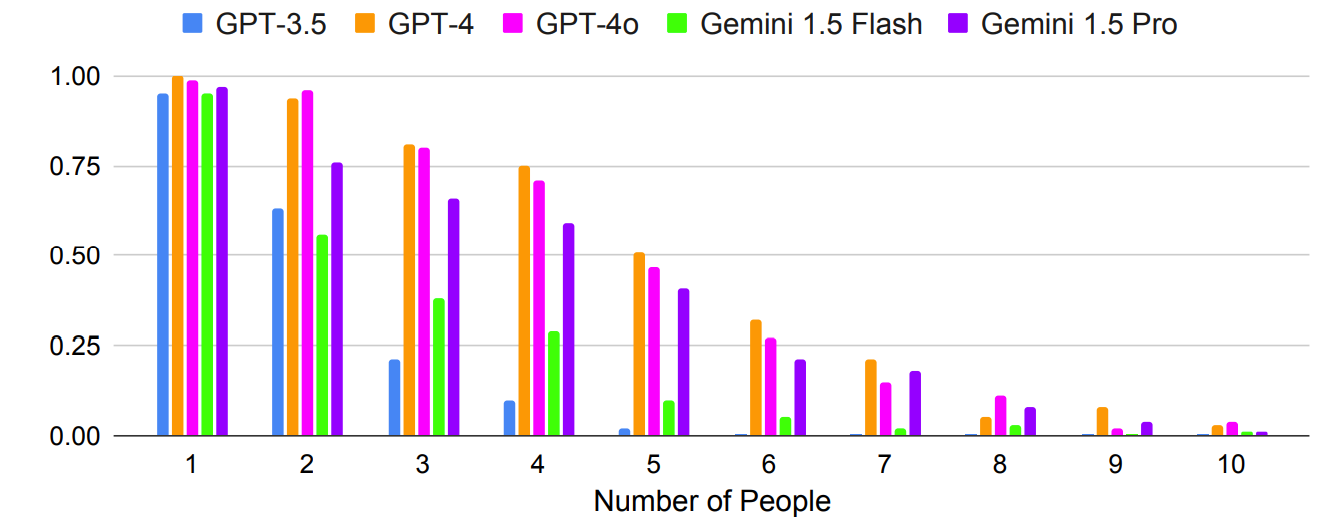
Som forventet ble resultatene eksponentielt dårligere med mer komplekse oppgaver der antall personer eller byer ble økt. Se for eksempel hvor raskt nøyaktigheten ble dårligere etter hvert som flere personer ble lagt til i møteplanleggingstesten.
Kan multi-shot prompting resultere i bedre nøyaktighet? Forskningsresultatene tyder på at det kan det, men bare hvis modellen har et stort nok kontekstvindu.
Det større kontekstvinduet i Gemini 1.5 Pro gjør det mulig å utnytte flere eksempler i konteksten enn i GPT-modellene.
Forskerne fant ut at en økning i antall skudd fra 1 til 800 forbedrer nøyaktigheten til Gemini Pro 1.5 fra 2,7% til 39,9% i Trip Planning.
Avisen "Disse resultatene viser at planlegging i kontekst er lovende, der LLM-ene kan utnytte den lange konteksten for å forbedre planleggingen."
Et merkelig resultat var at GPT-4o var veldig dårlig på turplanlegging. Forskerne fant ut at den slet med "å forstå og respektere begrensningene knyttet til flyforbindelser og reisedato".
Et annet merkelig resultat var at selvkorrigering førte til et betydelig fall i modellytelsen på tvers av alle modellene. Når modellene ble bedt om å kontrollere arbeidet sitt og korrigere, gjorde de flere feil.
Det er interessant å merke seg at de sterkere modellene, som GPT-4 og Gemini 1.5 Pro, hadde større tap enn GPT-3.5 ved selvkorrigering.
Agentisk AI er et spennende perspektiv, og vi ser allerede noen praktiske eksempler på bruk i Microsoft Copilot agenter.
Men resultatene fra NATURAL PLANs referansetester viser at vi har et stykke igjen før AI kan håndtere mer kompleks planlegging.
DeepMind-forskerne konkluderte med at "NATURAL PLAN er svært vanskelig å løse for moderne modeller".
Det ser ikke ut til at kunstig intelligens kommer til å erstatte reisebyråer og personlige assistenter helt ennå.



