

Googles DeepMind lanserte Gecko, en ny referanse for omfattende evaluering av AI-tekst-til-bilde-modeller (T2I).
I løpet av de siste to årene har vi sett AI-bildegeneratorer som DALL-E og Midt på reisen blir stadig bedre for hver versjon som lanseres.
Det har imidlertid vært svært subjektivt og vanskelig å avgjøre hvilken av de underliggende modellene disse plattformene bruker som er best.
Det er ikke så enkelt å hevde at én modell er "bedre" enn en annen. Ulike modeller utmerker seg i ulike aspekter av bildegenerering. Én kan være god på tekstgjengivelse, mens en annen kan være bedre på objektinteraksjon.
En av T2I-modellenes største utfordringer er å følge hver eneste detalj i ledeteksten og få disse nøyaktig gjenspeilet i det genererte bildet.
Med Gecko kan DeepMind forskere har laget en målestokk som evaluerer T2I-modellenes evner på samme måte som mennesker gjør.
Ferdigheter
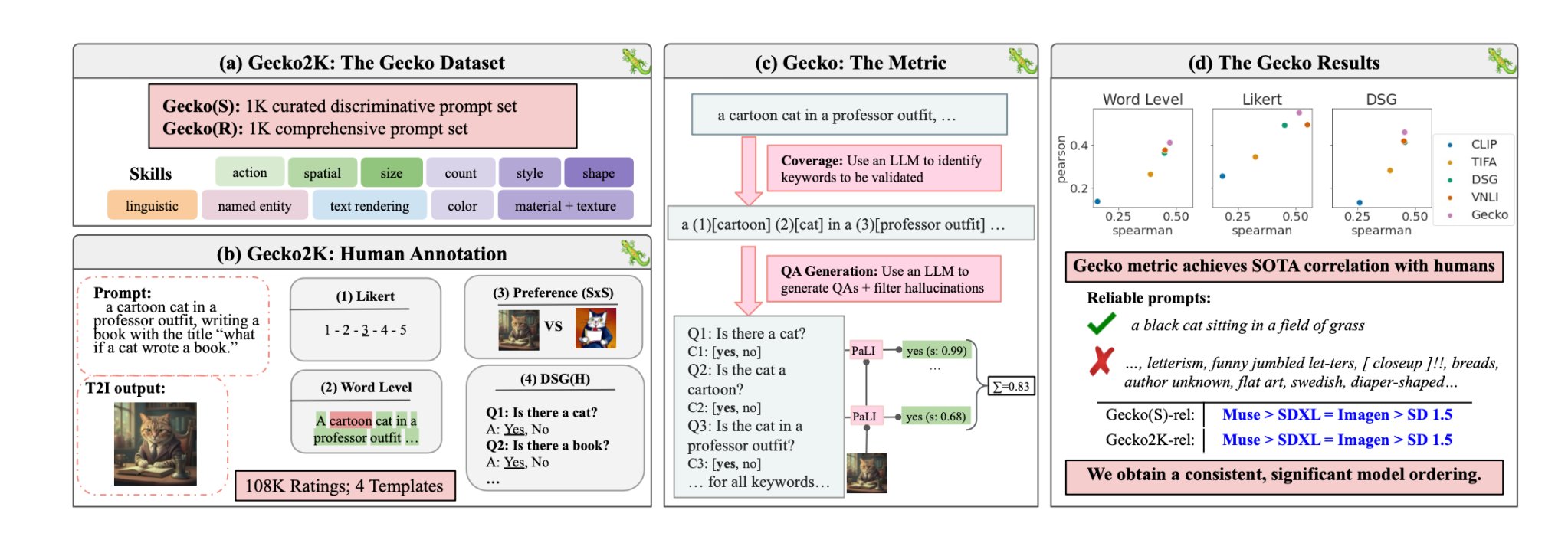
Forskerne definerte først et omfattende datasett med ferdigheter som er relevante for T2I-generering. Disse omfatter blant annet romforståelse, handlingsgjenkjenning og tekstgjengivelse. Deretter delte de disse opp i mer spesifikke delferdigheter.
Under tekstgjengivelse kan delferdighetene for eksempel omfatte gjengivelse av ulike skrifttyper, farger eller tekststørrelser.
En LLM ble deretter brukt til å generere spørsmål for å teste T2I-modellens evne til å teste en bestemt ferdighet eller delferdighet.
Dette gjør det mulig for skaperne av en T2I-modell å finne ut ikke bare hvilke ferdigheter som er utfordrende, men også på hvilket kompleksitetsnivå en ferdighet blir utfordrende for modellen.
Menneskelig vs. automatisk evaluering
Gecko måler også hvor nøyaktig en T2I-modell følger alle detaljene i en ledetekst. Også her ble en LLM brukt til å isolere viktige detaljer i hver ledetekst og deretter generere et sett med spørsmål knyttet til disse detaljene.
Disse spørsmålene kan være både enkle, direkte spørsmål om synlige elementer i bildet (f.eks. "Er det en katt i bildet?") og mer komplekse spørsmål som tester forståelsen av scenen eller forholdet mellom objekter (f.eks. "Sitter katten over boken?").
En VQA-modell (Visual Question Answering) analyserer deretter det genererte bildet og svarer på spørsmålene for å se hvor nøyaktig T2I-modellen tilpasser utgangsbildet til en ledetekst.
Forskerne samlet inn over 100 000 menneskelige annoteringer der deltakerne vurderte et generert bilde basert på hvor godt det stemte overens med spesifikke kriterier.
Menneskene ble bedt om å vurdere et spesifikt aspekt ved ledeteksten og gi bildet en poengsum på en skala fra 1 til 5 basert på hvor godt det stemte overens med ledeteksten.
Ved å bruke de menneskekommenterte evalueringene som gullstandard, kunne forskerne bekrefte at deres auto-evalueringsberegning "er bedre korrelert med menneskelige vurderinger enn eksisterende beregninger for vårt nye datasett".
Resultatet er et benchmarking-system som kan sette tall på spesifikke faktorer som gjør et generert bilde godt eller dårlig.
Gecko gir utgangsbildet poeng på en måte som ligger tett opp til hvordan vi intuitivt avgjør om vi er fornøyde med det genererte bildet eller ikke.
Så hva er den beste tekst-til-bilde-modellen?
I avisen dereskonkluderte forskerne med at Googles Muse-modell slår Stable Diffusion 1.5 og SDXL på Gecko-benchmarken. De er kanskje partiske, men tallene lyver ikke.



