

Forskere fra DeepMind og Stanford University har utviklet en AI-agent som faktasjekker LLM-er og muliggjør benchmarking av AI-modellers faktisitet.
Selv de beste AI-modellene har fortsatt en tendens til å hallusinere til tider. Hvis du ber ChatGPT om å gi deg fakta om et emne, er det mer sannsynlig at svaret inneholder fakta som ikke er sanne, jo lengre det er.
Hvilke modeller er mer faktabaserte enn andre når de genererer lengre svar? Det er vanskelig å si, for frem til nå har vi ikke hatt noen målestokk for hvor faktabaserte de lange LLM-svarene er.
DeepMind brukte først GPT-4 til å lage LongFact, et sett med 2280 spørsmål i form av spørsmål knyttet til 38 emner. Disse spørsmålene fremkaller lange svar fra LLM-en som testes.
Deretter skapte de en AI-agent ved hjelp av GPT-3.5-turbo for å bruke Google til å verifisere hvor faktabaserte svarene som LLM genererte, var. De kalte metoden Search-Augmented Factuality Evaluator (SAFE).
SAFE bryter først opp det lange svaret fra LLM i individuelle fakta. Deretter sender den søkeforespørsler til Google Søk og tar stilling til sannhetsgehalten i faktaene basert på informasjonen i søkeresultatene som returneres.
Her er et eksempel fra forskningsoppgave.
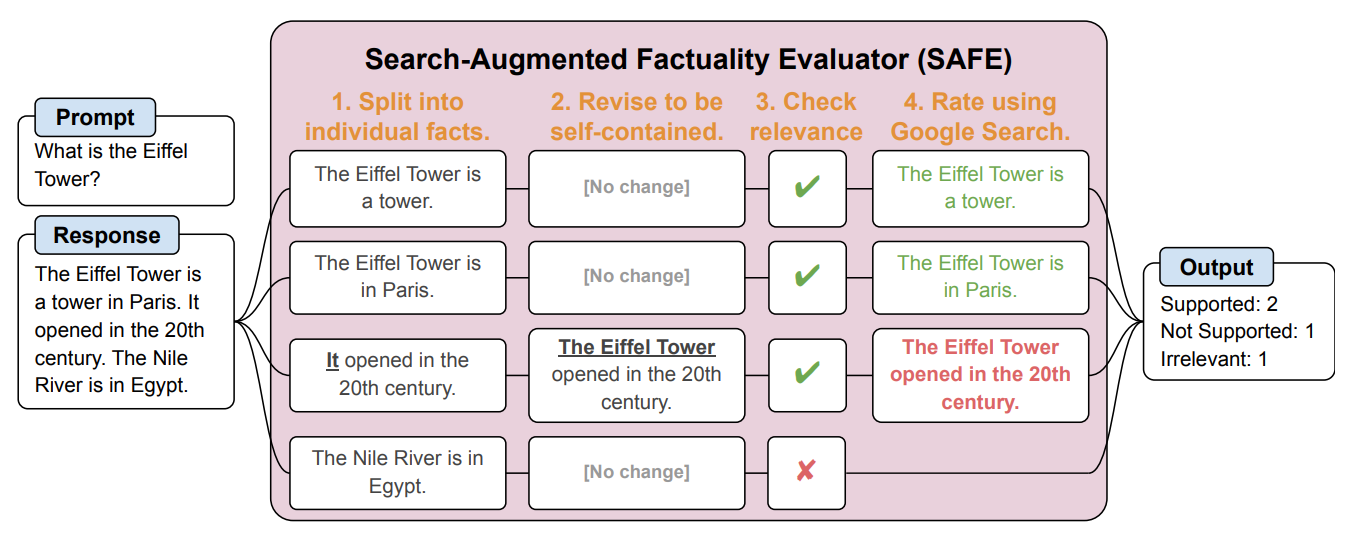
Forskerne sier at SAFE oppnår "overmenneskelig ytelse" sammenlignet med menneskelige kommentatorer som utfører faktasjekken.
SAFE var enig med 72% av de menneskelige annotasjonene, og der den var uenig med de menneskelige annotasjonene, hadde den rett i 76% av tilfellene. SAFE var også 20 ganger billigere enn menneskelige kommentatorer. LLM-er er altså bedre og billigere faktasjekkere enn mennesker.
Kvaliteten på svaret fra de testede LLM-ene ble målt ut fra antall faktoider i svaret kombinert med hvor faktabaserte de enkelte faktoidene var.
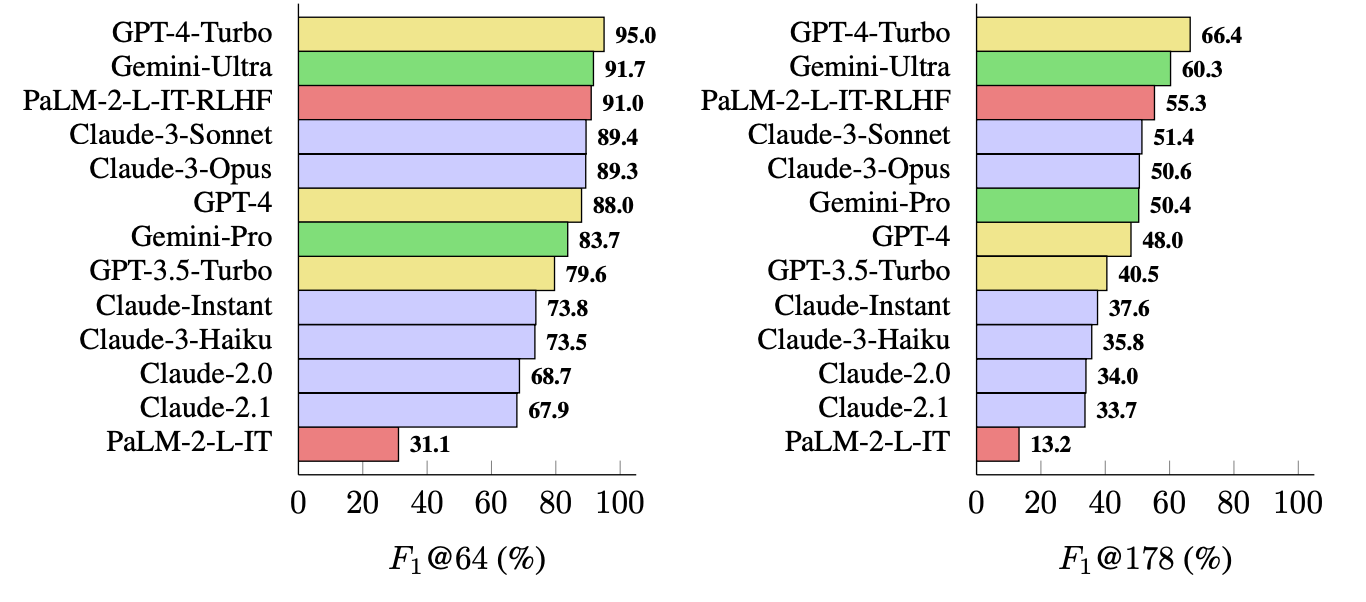
Målingen de brukte (F1@K), estimerer det "ideelle" antallet fakta i et svar. I referansetestene ble 64 brukt som median for K og 178 som maksimum.
Enkelt sagt er F1@K et mål på "Ga svaret meg så mange fakta som jeg ønsket?" kombinert med "Hvor mange av disse faktaene var sanne?".
Hvilken LLM er mest saklig?
Forskerne brukte LongFact til å spørre 13 LLM-er fra Gemini-, GPT-, Claude- og PaLM-2-familiene. Deretter brukte de SAFE til å evaluere hvor faktabaserte svarene deres var.
GPT-4-Turbo topper listen som den mest faktabaserte modellen når det gjelder å generere lange svar. Den ble tett fulgt av Gemini-Ultra og PaLM-2-L-IT-RLHF. Resultatene viste at større LLM-er er mer faktabaserte enn mindre LLM-er.
F1@K-beregningen ville sannsynligvis begeistret dataforskere, men for enkelhets skyld viser disse referanseresultatene hvor faktabasert hver modell er når den returnerer gjennomsnittlig lengde og lengre svar på spørsmålene.
SAFE er en billig og effektiv måte å kvantifisere LLM-langformfakta på. Det er raskere og billigere enn menneskelig faktasjekk, men det avhenger fortsatt av sannhetsgehalten i informasjonen som Google returnerer i søkeresultatene.
DeepMind lanserte SAFE for offentlig bruk og antydet at det kunne bidra til å forbedre LLM-faktualiteten ved hjelp av bedre forhåndstrening og finjustering. Det kan også gjøre det mulig for en LLM å sjekke fakta før den presenterer resultatet for en bruker.
OpenAI vil bli glade for å se at forskning fra Google viser at GPT-4 slår Gemini i enda en benchmark.



