

Apples ingeniører har utviklet et AI-system som løser komplekse referanser til enheter på skjermen og brukersamtaler. Den lette modellen kan være en ideell løsning for virtuelle assistenter på enheten.
Mennesker er flinke til å løse referanser i samtaler med hverandre. Når vi bruker uttrykk som "den nederste" eller "han", forstår vi hva personen refererer til basert på konteksten i samtalen og ting vi kan se.
Det er mye vanskeligere for en AI-modell å gjøre dette. Multimodale LLM-er som GPT-4 er gode til å svare på spørsmål om bilder, men de er dyre å lære opp og krever mye databehandling for å behandle hvert spørsmål om et bilde.
Apples ingeniører valgte en annen tilnærming med sitt system, kalt ReALM (Reference Resolution As Language Modeling). Avisen er verdt å lese for å få mer informasjon om utviklings- og testprosessen.
ReALM bruker en LLM til å behandle samtaler, skjermbilder og bakgrunnsenheter (alarmer, bakgrunnsmusikk) som utgjør en brukers interaksjon med en virtuell AI-agent.
Her er et eksempel på hva slags interaksjon en bruker kan ha med en AI-agent.
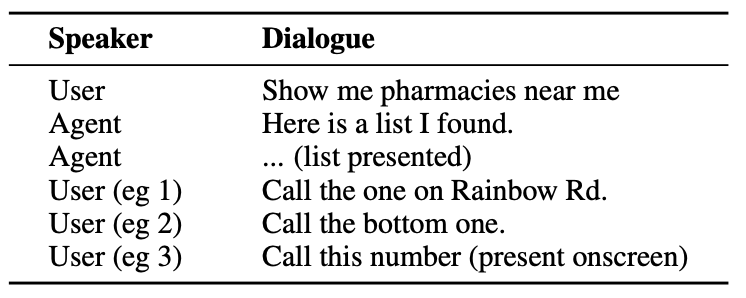
Agenten må forstå samtaleenheter, for eksempel at når brukeren sier "den ene", refererer han eller hun til telefonnummeret til apoteket.
Den må også forstå den visuelle konteksten når brukeren sier "den nederste", og det er her ReALMs tilnærming skiller seg fra modeller som GPT-4.
ReALM baserer seg på oppstrøms kodere for først å analysere elementene på skjermen og deres posisjoner. Deretter rekonstruerer ReALM skjermen i rene tekstlige representasjoner fra venstre til høyre og fra topp til bunn.
Enkelt sagt bruker den naturlig språk for å oppsummere brukerens skjermbilde.
Når en bruker stiller et spørsmål om noe på skjermen, behandler språkmodellen tekstbeskrivelsen av skjermen i stedet for å bruke en synsmodell til å behandle bildet på skjermen.
Forskerne lagde syntetiske datasett med samtale-, skjerm- og bakgrunnsenheter, og testet ReALM og andre modeller for å se hvor effektive de er når det gjelder å løse referanser i samtalesystemer.
ReALMs mindre versjon (80M parametere) presterte på linje med GPT-4, mens den større versjonen (3B parametere) presterte vesentlig bedre enn GPT-4.
ReALM er en liten modell sammenlignet med GPT-4. Den overlegne referanseoppløsningen gjør den til et ideelt valg for en virtuell assistent som kan eksistere på enheten uten at det går på bekostning av ytelsen.
ReALM fungerer ikke like godt med mer komplekse bilder eller nyanserte brukerforespørsler, men den kan fungere godt som en virtuell assistent i bilen eller på enheten. Tenk deg at Siri kunne "se" iPhone-skjermen og svare på henvisninger til elementer på skjermen.
Apple har vært litt trege i starten, men den siste utviklingen, som deres MM1-modell og ReALM viser at det skjer mye bak lukkede dører.



