

Apple har ennå ikke offisielt lansert en AI-modell, men en ny forskningsrapport gir et innblikk i selskapets fremgang i utviklingen av modeller med toppmoderne multimodale evner.
AvisenDen har tittelen "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", introduserer Apples familie av MLLM-er kalt MM1.
MM1 viser imponerende evner innen bildeteksting, visuell spørsmålssvargivning (VQA) og naturlig språkinferens. Forskerne forklarer at nøye valg av bilde-tekstpar gjorde det mulig for dem å oppnå overlegne resultater, spesielt i læringsscenarier med få bilder.
Det som skiller MM1 fra andre MLLM-er, er dens overlegne evne til å følge instruksjoner på tvers av flere bilder og til å resonnere rundt de komplekse scenene den blir presentert for.
MM1-modellene inneholder opptil 30B parametere, noe som er tre ganger så mye som GPT-4V, komponenten som gir OpenAIs GPT-4 sine synsfunksjoner.
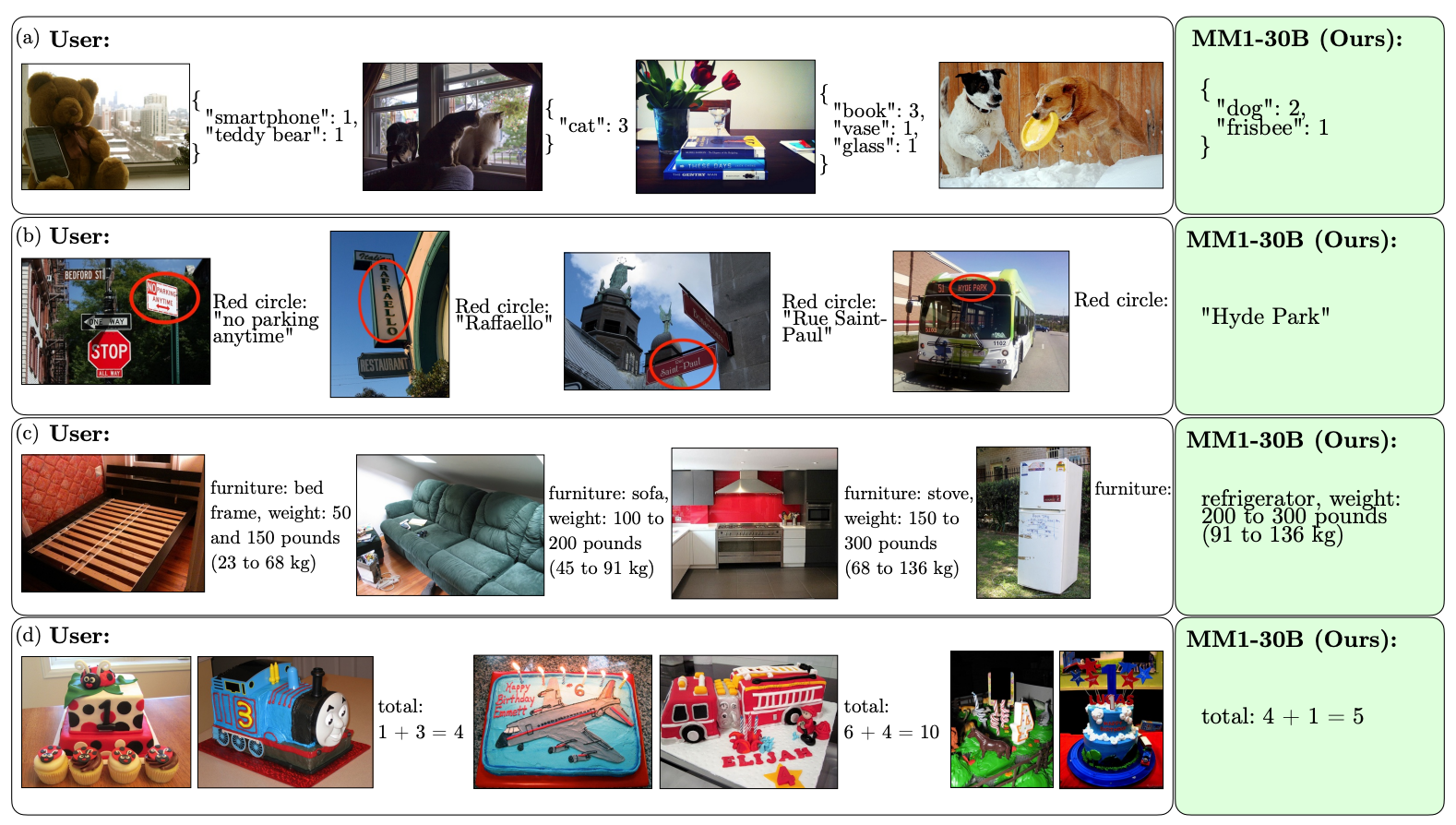
Her er noen eksempler på MM1s VQA-evner.

MM1 gjennomgikk en storstilt multimodal pretraining på "et datasett med 500 millioner sammenflettede bilde-tekstdokumenter, som inneholder 1B bilder og 500B teksttokens".
Omfanget og mangfoldet i pretreningen gjør det mulig for MM1 å utføre imponerende prediksjoner i kontekst og følge tilpasset formatering med et lite antall eksempler med få bilder. Her er eksempler på hvordan MM1 lærer seg ønsket resultat og format fra bare tre eksempler.
For å lage AI-modeller som kan "se" og resonnere, kreves det en syn-språk-kobling som oversetter bilder og språk til en enhetlig representasjon som modellen kan bruke til videre behandling.
Forskerne fant ut at utformingen av syn-språk-koblingen var en mindre viktig faktor for MM1s ytelse. Interessant nok var det bildeoppløsningen og antallet bildetokener som hadde størst innvirkning.
Det er interessant å se hvor åpne Apple har vært når det gjelder å dele forskningen sin med det bredere AI-fellesskapet. Forskerne skriver at "i denne artikkelen dokumenterer vi prosessen med å bygge MLLM og forsøker å formulere designleksjoner som vi håper kan være til nytte for samfunnet."
De publiserte resultatene vil sannsynligvis være retningsgivende for andre MMLM-utviklere når det gjelder valg av arkitektur og data for forhåndstrening.
Nøyaktig hvordan MM1-modeller vil bli implementert i Apples produkter gjenstår å se. De publiserte eksemplene på MM1s evner antyder at Siri vil bli mye smartere når hun etter hvert lærer seg å se.



