

Til tross for den raske utviklingen av LLM-modeller, har vi fortsatt liten forståelse av hvordan disse modellene håndterer lengre inndata.
Mosh Levy, Alon Jacoby og Yoav Goldberg, fra Bar-Ilan University og Allen Institute for AI, har undersøkt hvordan ytelsen til store språkmodeller (LLM-er) varierer med endringer i lengden på inndatateksten de skal behandle.
De utviklet et resonneringsrammeverk spesielt for dette formålet, slik at de kunne analysere hvordan lengden på inndataene påvirker LLM-resonnering i et kontrollert miljø.
Spørsmålene inneholdt ulike versjoner av det samme spørsmålet, som hver inneholdt den informasjonen som var nødvendig for å svare på spørsmålet, men som var fylt ut med irrelevant tilleggstekst av varierende lengde og type.
Dette gjør det mulig å isolere lengden på inndataene som en variabel, slik at endringer i modellens ytelse kan tilskrives lengden på inndataene direkte.
Viktige funn
Levy, Jacoby og Goldberg avdekket at LLM-er utviser en bemerkelsesverdig nedgang i resonneringsytelse ved inputlengder langt under det utviklerne hevder at de kan håndtere. De dokumenterte funnene sine i denne studien.
Nedgangen ble konsekvent observert i alle versjoner av datasettet, noe som tyder på et systemisk problem med håndtering av lengre inndata snarere enn et problem knyttet til spesifikke datautvalg eller modellarkitekturer.
Forskerne beskriver det slik: "Funnene våre viser en merkbar forringelse av LLM-enes resonneringsytelse ved mye kortere inputlengder enn deres tekniske maksimum. Vi viser at denne forringelsestrenden dukker opp i alle versjoner av datasettet vårt, men med ulik intensitet."

Studien viser også hvordan tradisjonelle mål som perplexity, som ofte brukes til å evaluere LLM-modeller, ikke korrelerer med modellenes ytelse på resonneringsoppgaver som involverer lange inndata.
Videre undersøkelser viste at den reduserte ytelsen ikke bare var avhengig av tilstedeværelsen av irrelevant informasjon (padding), men ble observert selv når slik padding besto av duplisert relevant informasjon.
Når vi holder de to kjernespennene sammen og legger til tekst rundt dem, synker nøyaktigheten allerede. Når vi legger inn avsnitt mellom spennene, synker resultatene enda mer. Nedgangen skjer både når tekstene vi legger til, ligner på oppgavetekstene, og når de er helt forskjellige. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26. februar 2024
Dette tyder på at utfordringen for LLM ligger i å filtrere bort støy og den iboende behandlingen av lengre tekstsekvenser.
Ignorerer instruksjoner
Et kritisk område for feil som ble fremhevet i studien, er LLM-enes tendens til å ignorere instruksjoner som er innebygd i inndataene når lengden på inndataene øker.
Noen ganger genererte modellene også svar som indikerte usikkerhet eller mangel på tilstrekkelig informasjon, for eksempel "Det er ikke nok informasjon i teksten", til tross for at all nødvendig informasjon var tilgjengelig.
Generelt ser det ut til at LLM-ene gjennomgående sliter med å prioritere og fokusere på viktig informasjon, inkludert direkte instruksjoner, etter hvert som lengden på inndataene øker.
Viser skjevheter i svarene
Et annet problem som ble lagt merke til, var at modellenes responser ble mer skjeve etter hvert som inndataene ble lengre.
LLM-ene var mer tilbøyelige til å svare "Falsk" etter hvert som lengden på inndataene økte. Denne skjevheten indikerer en skjevhet i sannsynlighetsestimeringen eller beslutningsprosessene i modellen, muligens som en forsvarsmekanisme som svar på økt usikkerhet på grunn av lengre inputlengder.
Tilbøyeligheten til å favorisere "Falske" svar kan også gjenspeile en underliggende ubalanse i treningsdataene eller en artefakt i modellenes treningsprosess, der negative svar kan være overrepresentert eller assosiert med kontekster preget av usikkerhet og tvetydighet.
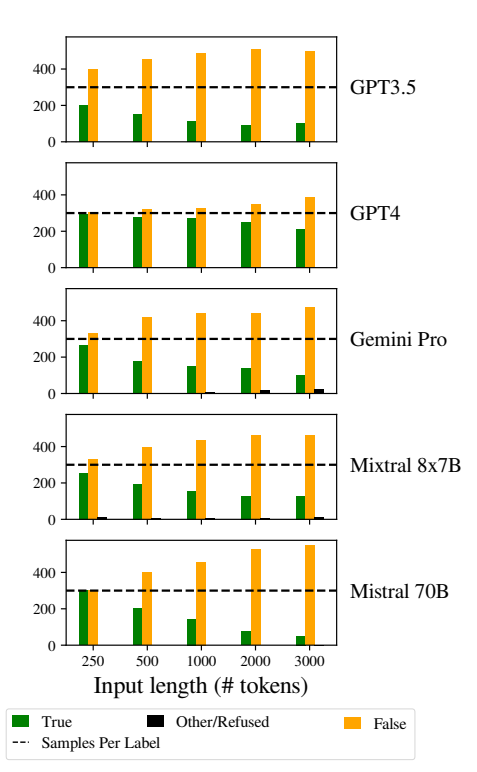
Denne skjevheten påvirker nøyaktigheten i modellenes resultater og gir grunn til bekymring når det gjelder LLM-enes pålitelighet og rettferdighet i anvendelser som krever nyansert forståelse og upartiskhet.
Det er viktig å implementere robuste strategier for å oppdage og redusere skjevheter under modellopplæringen og finjusteringsfasene for å redusere uberettigede skjevheter i modellresponsene.
En å sikre at treningsdatasettene er varierte, balanserte og representative for et bredt spekter av scenarier, kan også bidra til å minimere skjevheter og forbedre generaliseringen av modellen.
Dette bidrar til andre nyere studier som på samme måte belyser grunnleggende problemer i hvordan LLM-er fungerer, og som dermed kan føre til en situasjon der den "tekniske gjelden" kan true modellens funksjonalitet og integritet over tid.



