
Screening av pasienter for å finne egnede deltakere til kliniske studier er en arbeidskrevende, kostbar og feilutsatt oppgave, men AI kan snart løse dette problemet.
Et team av forskere fra Brigham and Women's Hospital, Harvard Medical School og Mass General Brigham Personalized Medicine gjennomførte en studie for å se om en AI-modell kunne behandle medisinske journaler for å finne egnede kandidater til kliniske studier.
De brukte GPT-4V, OpenAIs LLM med bildebehandling, aktivert av Retrieval-Augmented Generation (RAG) for å behandle potensielle kandidaters elektroniske pasientjournaler (EHR) og kliniske notater.
LLM-er er forhåndstrenet ved hjelp av et fast datasett og kan bare svare på spørsmål basert på disse dataene. RAG er en teknikk som gjør det mulig for en LLM å hente data fra eksterne datakilder som Internett eller en organisasjons interne dokumenter.
Når deltakere skal velges ut til en klinisk studie, avgjøres deres egnethet ut fra en liste med inklusjons- og eksklusjonskriterier. Dette innebærer vanligvis at opplært personale går gjennom EPJ-er til hundrevis eller tusenvis av pasienter for å finne dem som oppfyller kriteriene.
Forskerne samlet inn data fra en studie som hadde som mål å rekruttere pasienter med symptomatisk hjertesvikt. De brukte disse dataene for å se om GPT-4V med RAG kunne gjøre jobben mer effektivt enn studiepersonalet gjorde, samtidig som nøyaktigheten ble opprettholdt.
De strukturerte dataene i EPJ-ene til potensielle kandidater kan brukes til å fastsette 5 av 6 inklusjonskriterier og 5 av 17 eksklusjonskriterier for den kliniske studien. Det er den enkle delen.
De resterende 13 kriteriene måtte fastsettes ved å undersøke ustrukturerte data i hver enkelt pasients kliniske notater, noe som er den arbeidskrevende delen forskerne håpet at kunstig intelligens kunne hjelpe dem med.
🔍Kan @Microsoft @Azure @OpenAI's #GPT4 presterer bedre enn et menneske for screening i kliniske studier? Det spørsmålet stilte vi i vår siste studie, og jeg er veldig glad for å kunne dele resultatene våre i preprint:https://t.co/lhOPKCcudP
Å integrere GPT4 i kliniske studier er ikke...- Ozan Unlu (@OzanUnluMD) 9. februar 2024
Resultater
Forskerne innhentet først strukturerte vurderinger utført av studiepersonalet og kliniske notater for de siste to årene.
De utviklet en arbeidsflyt for et klinisk notatbasert system for spørsmålssvar basert på RAG-arkitektur og GPT-4V, og kalte denne arbeidsflyten RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Notater fra 100 pasienter ble brukt som utviklingsdatasett, 282 pasienter som valideringsdatasett og 1894 pasienter som testsett.
En klinikerekspert foretok en blindet gjennomgang av pasientjournalene for å svare på kvalifiseringsspørsmålene og fastsette "gullstandard"-svarene. Disse ble deretter sammenlignet med svarene fra studiepersonalet og RECTIFIER basert på følgende kriterier:
- Sensitivitet - Testens evne til å identifisere pasienter som er kvalifisert for studien (sanne positive).
- Spesifisitet - Testens evne til å identifisere pasienter som ikke er kvalifisert for studien (sanne negative).
- Nøyaktighet - Den totale andelen korrekte klassifiseringer (både sanne positive og sanne negative).
- Matthews korrelasjonskoeffisient (MCC) - Et mål som brukes til å måle hvor god modellen var til å velge eller ekskludere en person. En verdi på 0 er det samme som å kaste mynt og kron, mens 1 betyr at man treffer riktig 100% ganger.
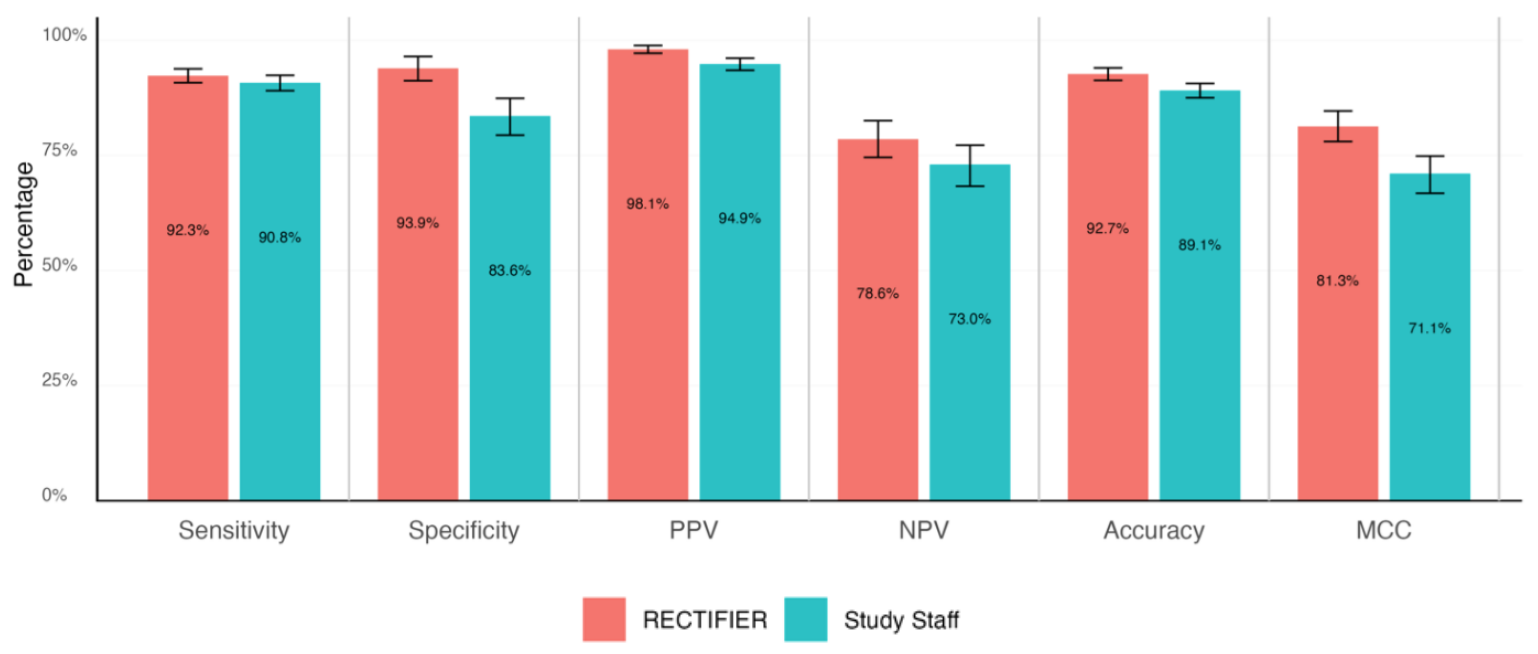
RECTIFIER presterte like godt, og i noen tilfeller bedre, enn studiepersonalet. Det viktigste resultatet av studien kom sannsynligvis fra kostnadssammenligningen.
Det ble ikke oppgitt noen tall for godtgjørelsen til studiepersonalet, men den må ha vært betydelig høyere enn kostnaden ved bruk av GPT-4V, som varierte mellom $0,02 og $0,10 per pasient. Å bruke kunstig intelligens til å evaluere en gruppe på 1 000 potensielle kandidater ville ta noen minutter og koste rundt $100.
Forskerne konkluderte med at bruk av en AI-modell som GPT-4V med RAG kan opprettholde eller forbedre nøyaktigheten i identifiseringen av kandidater til kliniske studier, og gjøre det mer effektivt og mye billigere enn å bruke menneskelige ansatte.
De påpekte at man må være forsiktig med å overlate medisinsk behandling til automatiserte systemer, men det ser ut til at kunstig intelligens vil gjøre en bedre jobb enn oss hvis den blir riktig ledet.



